
变声导论-变声器原理及实现(核心算法实现篇)

开篇
虽然笔者一向很喜欢长话短说,挑重点,但本文的内容恐怕不能说复杂但是绝对也不能说简单,在开始说正事之前,笔者仍然很愿意先聊聊一些开心轻松的事情,比如说为什么要做一个变声器,明白点说笔者有钉宫病,喜欢听钉宫的声音,软萌的萝莉音自然令人欲罢不能浑身舒服,再者作为萌妹纸画师的笔者显然不是第一天想给自己画的设子配音了,可惜囊中羞涩,买配音我也买不起,于是自然还是得自己来,但不管怎么说,作为一个信号处理的老狗,最终还是得本狗亲自出马,动用点专业知识来做点专业的事情.
在PC兴起的时期,变声器设计一向是一个很有意思的话题,即使是今天也是,关于变声器的效果也一向是日常娱乐,主播骗粉,女装大佬所津津乐道的话题,不过正如大家所看到的那样,不管是免费的还是收费的,软件的还是硬件的,效果也就那样,尤其是类似于男变女,女变男,效果大多不咋地.
为了进一步深入基层了解情况,笔者自掏腰包,购买了多套独立声卡及某宝的调音服务,遗憾的是,不能说没有效果,但效果还真不咋样,完全无法做到广告中的那种效果,并且很大一部分大肆宣传的那些效果好的那堆,大多是先用男声录一套,然后客服小姐姐再录一套,根本不是变声器效果所能完成的.尤其是一些粗制滥造的变声器,听上去就一堆噪音(基音断裂造成,将白点就是变声算法不行).
别看变声器这一话题,聊起来都觉得有点滑稽,但上升到声学模型来谈谈,那马上就是另一番风景了,笔者和调音师聊了一聊,发现大多的调音更多是基于感性上的,而很多的声学支撑理论他们大多也并不熟悉,经验固然重要,但缺乏基础理论支撑,常常会使得问题陷入一个僵局,毕竟每个人的发声系统是如此的独立且复杂,仅仅靠一套固定的变调滤波系统就想完成猛男到萝莉的转变,无异于天方夜谈.因此,目前比较省钱省事且靠谱的做法是,利用练习"嗓音"并配合变声器来完成这种变音效果,也就是我们所说的伪音.可惜笔者作为一个有尊严的信号狗,自然无法做到捏着嗓门成为vtb,因此,这也是笔者为什么要写这篇文章的原因.
在本篇文章中,我们终将从底层理论开始,剥丝抽茧,究其本质,并最终告诉大家变声器的核心算法是如何实现的(核心算法实现篇),而在本文的下一篇续作(基音分类与滤波系统实现)我们将对变声器效果进行进一步优化并讨论如何实现高质量的变声,同时讨论实现那种"完美"的变声效果,为何如此之难.但笔者并非全才也非天才,文中多有疏漏错误,还望读者不吝指正.
准备工具
在开始聊些基础理论之前,笔者需要先介绍一款软件《SoundLab》,不用担心,这是笔者开发的一款专门用于人声的声学分析与建模软件,同时附带一款实时变声器,它的大小不到1M,完全免费并且已经在Github上完整开源。
因为SoundLab是基于笔者开发的另一个引擎PainterEngine开发的,因此为了编译SoundLab,你还需要同时下载painterengine
你可以在百度网盘上下载到这个程序的release版本
提取码:n5mh
它包含一个SoundLab(声音调试器) 和一个Filter(实时变声器),其中Filters文件夹中包含了当前变声器使用的滤波器组,在当中包含了一个笔者依照自己的声音调的“钉宫”滤波器作为示范,下载好以后,你就可以打开试试了,当然因为每个人的发音效果并不相同,因此,笔者无法保证所有人使用该变声器最终的效果。
当然,调音的关键是使用Soundlab配置一个属于自己的滤波器,因此,本文的重点一是是基于一系列的声学理论来协助我们更好的对自己的声音进行建模,二是如果说你是编程玩家,你也可以基于这套理论你可以开发自己的变声程序,当然如果嫌麻烦的话,你可以在PainterEngine中直接抄代码。

声波采样与时域分析
初中物理就告诉我们,人类发声本质上是声带的震动引起的,这里我们先不比考虑太多复杂的东西,但我们不难想象,声带的振动带动了空气压差,这看上去就像是波一样,因此,声音的本质上也就是声波在空气中传播,在数学的表述上,我们常常使用正弦曲线来表达这一个概念,为了记录声波,也就是将正弦曲线保存成数据,这里就涉及到两个非常重要的概念,一个是采样,而一个是量化.
这两个概念常常一起使用
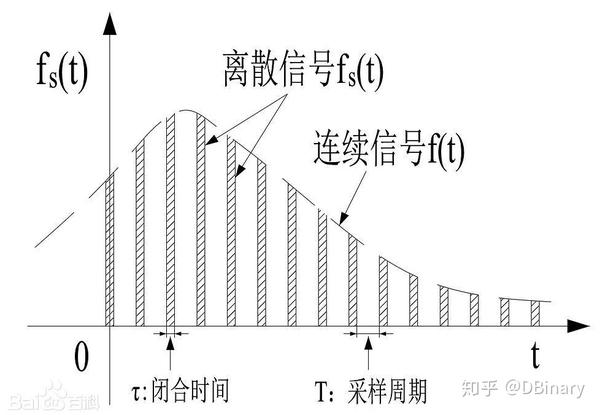

简单来说采样就是将连续信号打散为离散信号,并用一个范围的数值对其进行量化,在大部分的情况下,例如我们常见的使用PCM编码的WAV文件,采样率大多是44100hz,量化的范围大多是16bit,也就是说,在一秒钟内有44100个样本点来记录这个波形的具体形状.
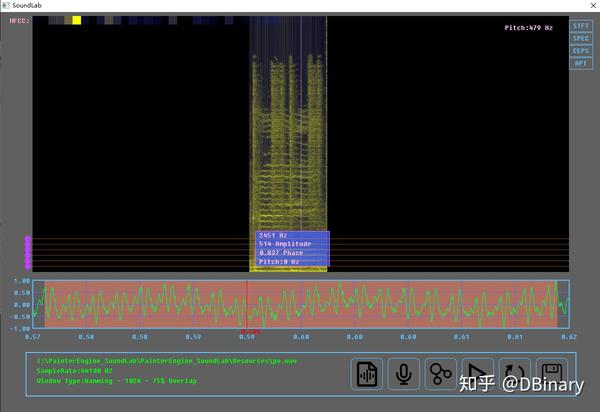
到了这一步,如果我们将这个波形的每个点都绘制出来,我们就能得到一个声波的图形化的显示,例如,下面我们以钉宫的po~音做示范,通过soundlab加载后,查看其波形
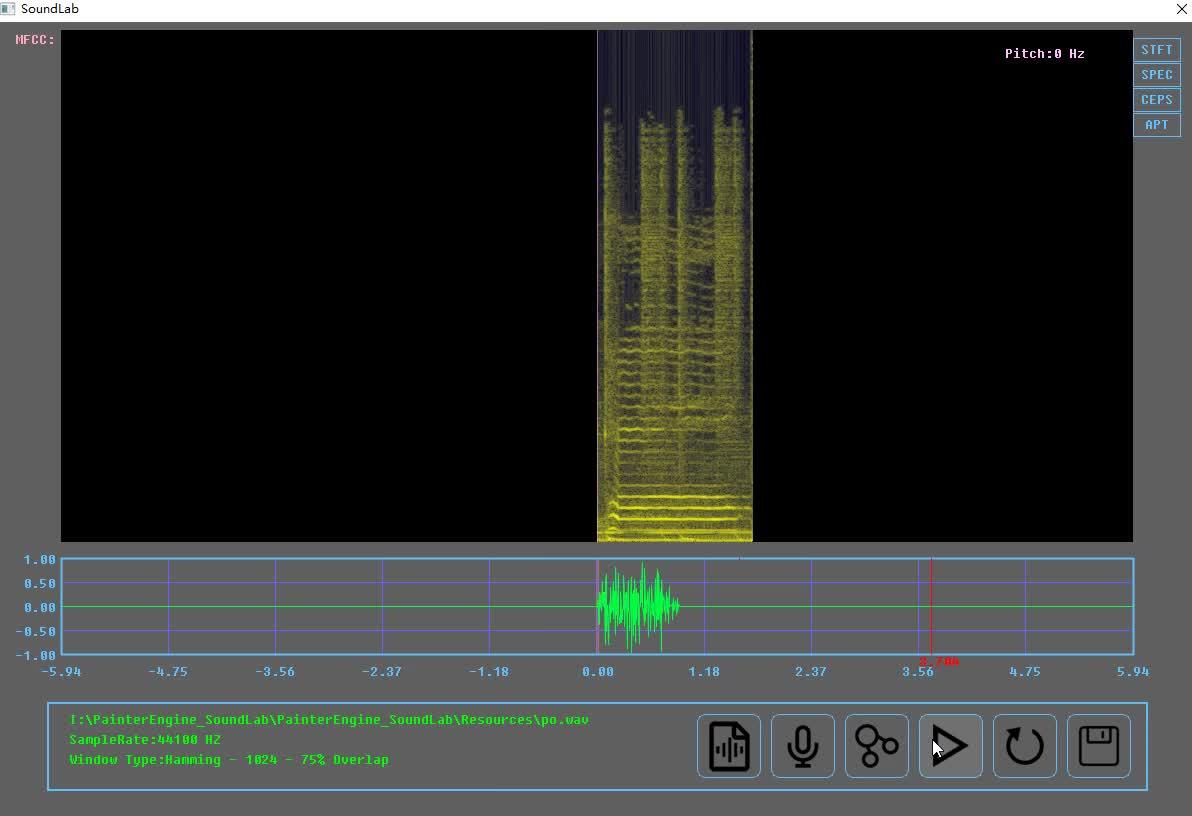 钉宫的po音波形分析https://www.zhihu.com/video/1219285442329300992
钉宫的po音波形分析https://www.zhihu.com/video/1219285442329300992虽然仅仅从时域波形图来看,我们并不能完整的描述其到底有多大的意义,但时域的波形给我们提示了很多的信息,例如我们可以发现,声波是呈现了一系列的周期性,例如从下图你可以看到整个波段几乎都是一个长度为2毫秒的"小波"循环组成


为了加深对其概念的理解,笔者使用男性的声音发出同样的po~音,并将之的时域图和钉宫的时域做进一步的对比
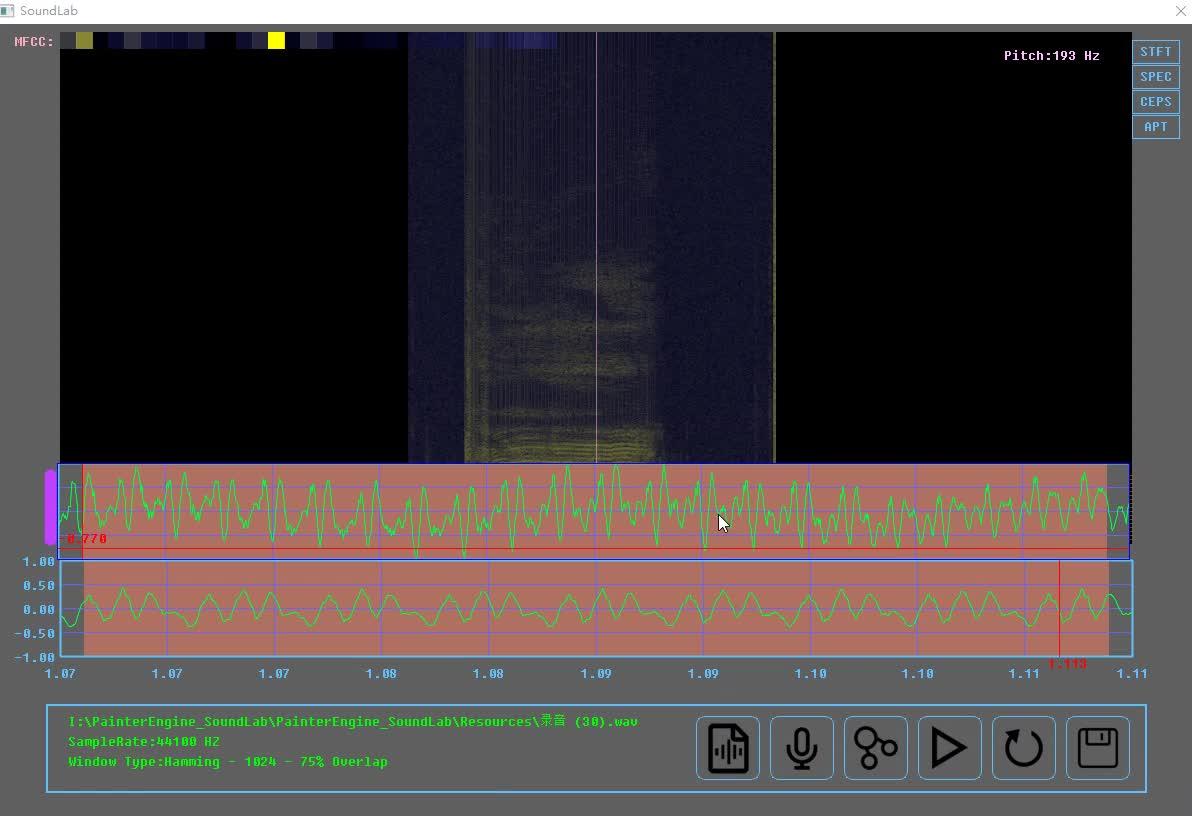 笔者的po~和钉宫的~https://www.zhihu.com/video/1219295847844028416
笔者的po~和钉宫的~https://www.zhihu.com/video/1219295847844028416观察下图,显而易见的一个明显的共同点是,不论是钉宫的萌音还是男性的大叔音,其时域都显示了一个"小波"的周期性,不同的是,男性声音的"小波"长度达到了5ms,并且,男性声音较为的平缓,而钉宫的声音则多了更多的毛糙




为了让这篇文章显得更专业一点,我们需要统一一下这些专业的名词:
我们将这个小波称作基波
将基波的时域长度称作基音周期
对应的一秒内出现了多少个基波,也就是基音频率了
那么基于这一点,我们变声器要完成的目标也就明确了,不论我们的变声器使用什么方式,比如我们需要让大叔音变声钉宫的萌音,最终的评估质量的标准是
我们使用男性声波重建的时域波形形状应该尽可能接近钉宫声波的波形
你可能想到了,如果要发出了钉宫一样的"po~"音,是不是只需要拷贝钉宫的基波,并依据自己的声波幅度变化进行重建,就能够发出和钉宫一样的声音了.
是的!这是一个非常直观简单暴力而且有效的做法,然而遗憾的是,这个目标看似简单,但除了"po~"音之外,仍然有其它不同的原因,并且,声音所携带的,不仅仅只是"响度"信息,而基波的样式会受到语气,语调、舌头、鼻子、嘴型、呼出气体的量....的影响,同时,如何将源音进行识别分类,也是一个大问题,从声带激励到声门系统是如此的独特复杂,以至于我们很难重建如此规模庞大的发声系统。
因此这一想法实际的使用中实现仍然任重道远且困难。
我们直接从时域对声波进行处理尽管直观但受限不小,因此在大多数的情况下,我们另寻出路在频域对声波进行进一步的处理,而这也就是我们下面要讨论的东西.
短时离散傅里叶变换
在讨论接下来的内容也就是时域特性到频域特性之前,不得不谈及到的就是傅里叶变换了,当然,准确来说是短时离散傅里叶变换(STFT),这有很多原因,一则是傅里叶变换使用正弦波进行信号拟合,这使得傅里叶变换对人声声波的处理非常合适,二是傅里叶变换拥有快速计算的方案,快速傅里叶变换(FFT)本质上只是运用在计算中的优化,因此在下文中,我们谈及短时傅里叶变换时大部分情况下它可能采用了快速傅里叶变换的算法,这点并不冲突,当然,挑选其它的母小波对人声小波变换的分析的情景也有,但在这里笔者就不做更多的讨论了.
但不管如何在开始介绍频域特性之前,我假设读者已经了解并掌握了傅里叶变换的相关内容(这很重要)如果读者并不清楚傅里叶变换是怎么回事,那么你可以翻阅笔者在知乎上相关的几篇回答与文章,并确保自己对傅里叶变换的原理与概念已经熟知,笔者希望读者能够尽可能的消灭关于傅里叶变换上哪怕是细节的疑问,因为在之后的一些理论讨论中,拥有扎实的基础将会显得非常的重要.
分帧,加窗
现在我们获得了一个音频信号,并且我们已经写好了STFT的相关代码,是时候对它进行频域分析了
在此之前我们首先会碰到第一个问题,我们应该如何对数据进行分析呢,一个显而易见的问题是我们每次应该对多长的时间的时域信号进行傅里叶变换?因为我们之前已经谈到过了,基2快速傅里叶变换[1],要求信号长度必须是一个2基数,但语音信号是如此的复杂,我们同样要求我们所变换的信号段必须是尽可能周期性的,在语音信号中一个普遍的认识是
在10~40ms内,我们可以把信号当做是一个周期平稳的信号[2]
假设我们的采样率为44100HZ,那么,这个分析帧长大约就会在512~2048之间,一个普遍的认识是,帧的长度过短,那么傅里叶变换的结果的分辨率不高,而帧长过长,很可能导致引入一些非平稳的信号,因此依据语音信号的不同,这个长度我们应该做对应的调整,同时才采集信号的时候,我们应该尽可能保证采集信号的质量,例如尽可以拖长发音的时间,或者利用时域压拓的方法让平稳信号尽可能长[3],在SoundLab中,取的帧长度是1024,对于人声分析来说,这个长度大部分情况下是合适的.
另外一个问题是帧之间是否应该有overlap也就是重叠部分,例如一个长度是2048的信号假如使用1024长度进行分帧,那么如果没有overlap,应该是可以分为两帧,但如果有0verlap,且overlap为50%,那么就会分为3帧下面的图表示了这一个分帧的过程.
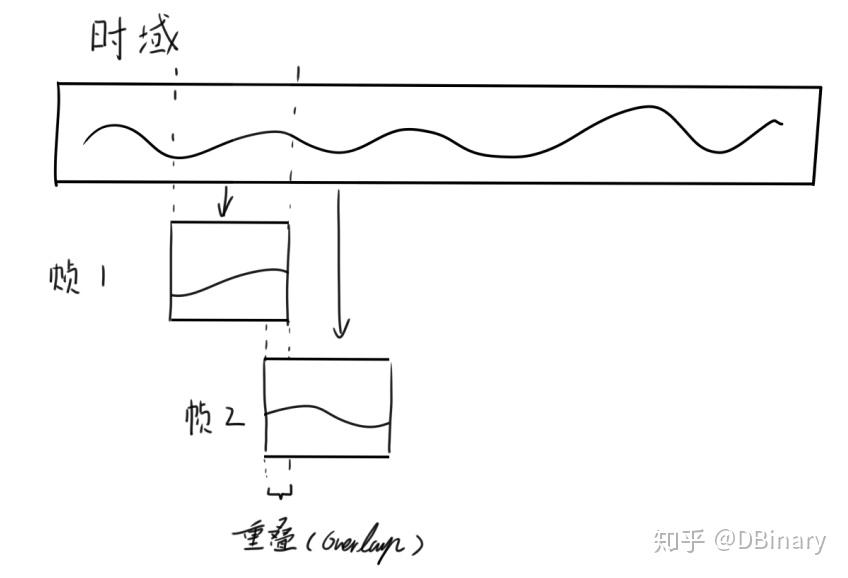

overlap的目的是避免信号中具有一些跳变信号导致信号分析时的准确度不够,说白点就是提高分辨率的,如果我们的语音信号只是用来看的并不需要逆变换处理,例如在本例中我们已经明确知道我们分析的仅仅是人声绝大部分情况而跳变信号大都是一些敲打乐引入的,因此是否做overlap其实影响并不大,但overlap有助于提高我们生成的时频图的长度让我们看上去更加的方便,因此在SoundLab中,笔者仍然将这个overlap提高到尽可能理想的75%


同时,笔者使用hamming窗对每一个分析帧进行加窗,加窗的目的是为了减轻分帧时无法截取整数周期倍的信号造成的频域泄露,关于这一点,读者可以在其它地方找到相关的材料[4]
需要重点提及的一点是,hamming窗在对语音信号生成时频图具有优异的性能,但是在语音重建时有时并不是非常适用,在之后的语音重建笔者使用的是sinc窗,这一点将会在之后进行讨论.
频域分析
现在万事俱备,为了进一步了解男声与女声之间的差距,我们已经可以从频域对男声和女声进行进一步的分析了
为了进一步说明,我们仍然使用Soundlab加载之前的男声和女声的po~音
 男声女声发音时频图https://www.zhihu.com/video/1219603926091292672
男声女声发音时频图https://www.zhihu.com/video/1219603926091292672为了进一步说明,笔者将男声(左)女声(右)时频图放在下面

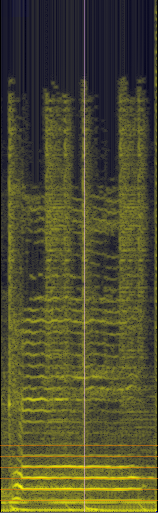
那么时频图如何看呢,我们可以看到,男声女声的时频图都由一系列的亮线组成,频域从图像的底部到顶部依次增高,颜色越亮表示能量在此处越集中.一个直观的体验是,男声的时频图的亮线较女声的更加密集且第一个亮线比女声的第一根亮线要低,而且这些亮线,呈等间距分布.
这引出了一系列概念
- 大部分情况下我们将时频图的第一根(也可能是第二根,排除直流分量那根亮线)亮线对应的频率,叫做基音频率.在上文的基音周期中我们同样有提及这一点.
- 在基音频率往上的第一根亮线,叫做第一泛音,你看注意到了时频图中一根橘黄色的线,倒数第二根,标注的就是第一泛音,然后再往上是第二泛音....以此类推,
- 这些亮线,统称为这个音的共振峰.很容易发现,这些共振峰在频率上呈基音频率的整数倍出现.
- 你可能还观察到,女声的高频能量明显较男声的能量分布清晰,这涉及到一个叫头腔共鸣的概念这对变音有着很强的指导意义,之后我们将会对其进行进一步讨论
- 这些频域特性,很大程度上决定了这个音的音调与的音色.
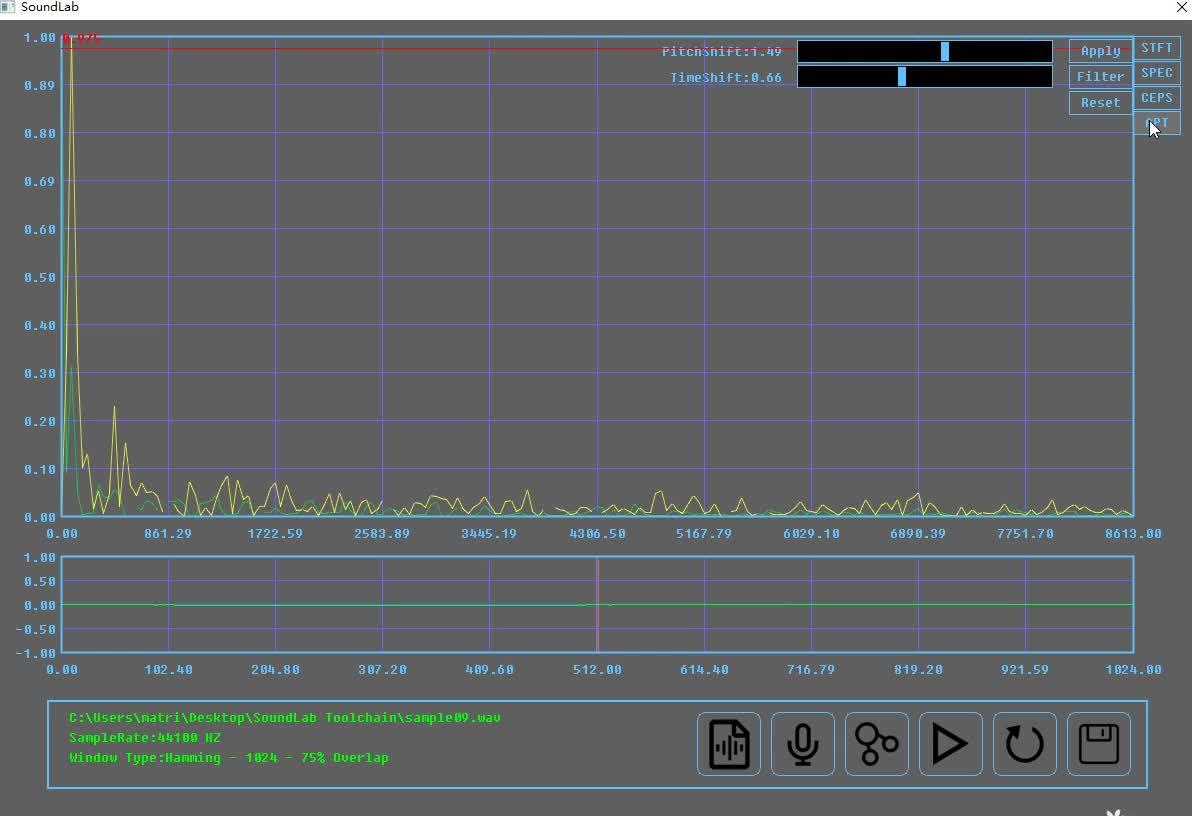
当然,如果你觉得时频图不便于观察,你可以点击SoundLab右上角的spec按钮,来详细观察其频域特性
 https://www.zhihu.com/video/1219612395712258048
https://www.zhihu.com/video/1219612395712258048变声的第一步,变调
你可能已经注意到,在很多的视频或音频当中,当我们加快播放的速度,男声就变成了"女声",这并不难理解,如果用100HZ的采样率去采样一个10HZ的正弦波.而用200 samplerate的速度去"播放"这个正弦波,那么,这个正弦波就会是20HZ的.对于变调,例如这种将频率升高的做法,其实也非常简单,假如我们想要将音调提高一倍,只需要每隔1个丢掉一个样本点就可以了
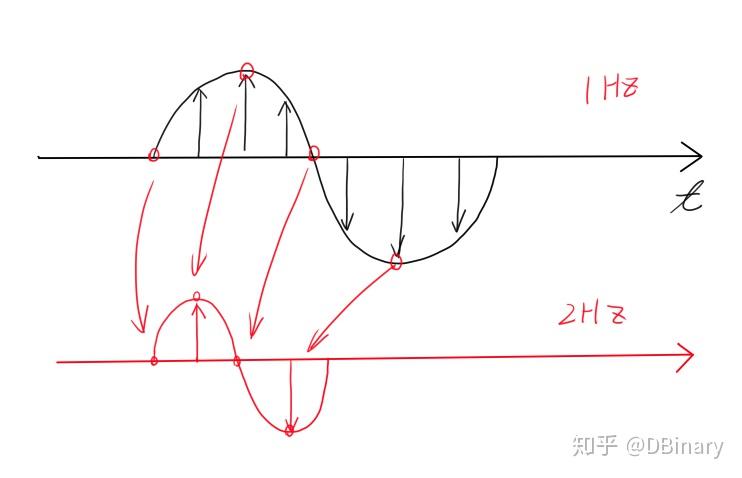

即管完成一个可用的变声器程序并不简单,但幸运的是,要完成其关键的变调几乎是整个变声算法中最为简单的第一步,变调的办法有很多,但就像我们在上面提到的那样,直接对采样的样本点进行操作,是一个简单而快速的方案,按专业的术语来说,这是一个重采样的过程.
举一个最简单的例子,如果我们要将声调提高一倍,我们只需要每隔一个丢弃一个样本点就可以了,如果我们想要将音调降低一倍,只需要每隔一个样本点插入一个0就可以了.其中,丢弃数据的过程叫做抽取(下采样),插入数据的过程叫做内插(上采样),需要注意一点的是,在抽取和插入的过程中,可能可能引入一些不必要的频域数据(混叠),因此,在抽取之前,一般我们会将信号通过一个滤波器,而插值之后,也会通过一个滤波器来消除那些我们不需要的频率,那么有一个疑问是,我们如何获得比如原频率的1.5倍的重采样数据呢.
一个通用的做法是,我们先使用抽取将原信号频率放大3倍,再使用插值将信号频率缩小2倍,这样就能得到1.5倍的频率样本了.需要注意的是,我们一般不会使用先插值后抽取的方案.
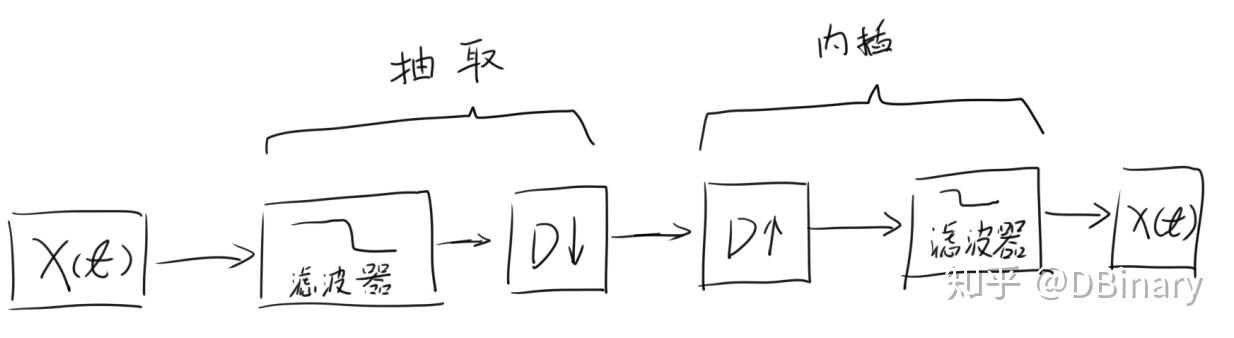

尽管这种抽取与内插能够很好地完成变调的工作,然而在实际的编程使用中,这并不是一个万能的办法,如果我们需要将频率准确放大1.1倍,这就意味着我们通过抽取先将频率放大11倍,然后再使用内插将频率缩小10倍,其前后需要通过2次滤波器,对计算机的性能消耗来说,恐怕并不算是什么好事.
因此,在更多的情况下,我们使用线性插值重采样的方法,对信号进行重采样


为了演示重采样的效果,我们继续回到soundlab当中模拟重采样的过程
 将声调提升1.5倍https://www.zhihu.com/video/1219729650450124800
将声调提升1.5倍https://www.zhihu.com/video/1219729650450124800时域压拓
正如上一章节所述,我们使用重采样进行变调操作,变调是成功了,但是也引入了变调后的长度和原长度不一致的问题:
总的来说,重采样是一种变调变速的音频处理办法,而我们变声器需要的是变调不变速的办法,当然,变声器未必一定需要使用重采样来完成,还有诸如频域变换法,正弦建模法等办法来完成,但前者容易在频域引入额外的分量,后者的计算量也较为庞大,因此在本文中,笔者并不讨论这两种方法,既然重采样改变了我们的音频长度,因此,使用变速不变调方法(又称时域压拓 Time-Scale Modification[3]),对时域进行修正,是一个不错的选择.
时域压扩(Time-scale modification简称TSM,又叫变速不变调)是一个能够改变音频的"语速"而不改变其音调的算法,是一个在目前音频信号处理中必不可少的一种重要算法,然而音频信号是多种多样的(包含了各种谐波(基音,泛音)冲击和瞬态分量),因为这种广泛的声学和音频特性,因此,目前没有一种能够通用的TSM算法,你需要依据音频特性来选择合适的TSM方法,本文的目的也就是科普一系列TSM算法并对它的特性与局限性进行讨论。
为此,我们先回顾一些基础的TSM方法,讨论一些比较典型的TSM相关问题。
变速不变调(TSM)的基本原理
变速不变调,顾名思义,改变速度不改变音调,大部分的TSM算法,都可以用下图进行解释
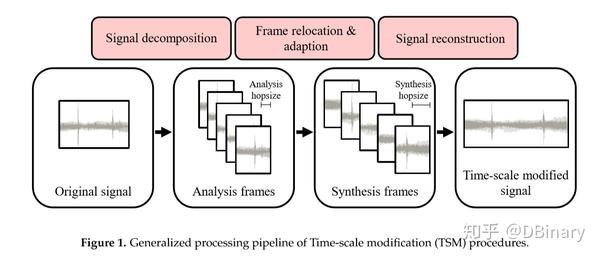

简单来说,就是把一段音频信号等分成不同的帧,帧的长度大多选取是50ms到100ms之间度,然后对每个帧进行一系列处理比如拉伸或者压缩,最后在将这些帧重新叠加成合成信号(当然很多的TSM方法中两个帧叠加时常常是由重叠部分(overlap)的)当然这个重叠部分需要进行一系列的处理以减少类似于相位不连续、幅度波动造成的影响,上述这个过程在论文中有一个数学的表达方式(当然有些内容是笔者依据自己经验加上去的),但不管是文字表达还是数学表达基本意思大致如此,如果有兴趣可以转到论文中去详细查看[3]。
最直接暴力的一种TSM方式(重叠叠加OLA)
这个很好解释,把音频信号分帧处理后,直接把这些处理后的信号首位拼接起来,比如一个最简单粗暴的方式,比如要把一段音频信号的语速放慢,只需要每一个帧都进行延扩,然后在首位拼接起来就行了,但造成的劣势也是显而易见的,它会造成拼接处的波形不连续(语音信号中的基音断裂),于是拼接的信号中会有biu吱biu吱的奇怪的声音。
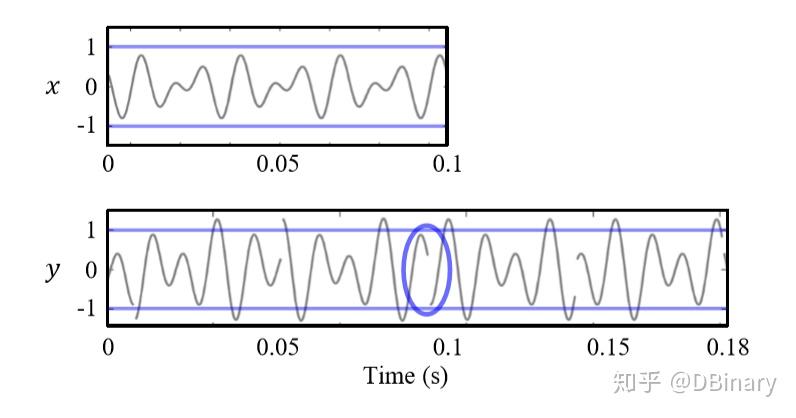

为了减轻这种波形不连续造成的影响,上一章节我们也提到了,两个帧之间需要留一点重叠的部分,同时,对每一个帧进行加窗处理,在OLA中,常常使用汉宁窗对帧进行加窗叠加。那么,一个音频变速的叠加算法的流程如下图所示


- 首先对音频时域进行分帧,
- 加上汉宁窗
- 间隔 H_{a} 取第二个帧
- 对第二个进行加窗,并与第一个窗进行叠加,叠加的长度是 H_{s}
上述加窗在一定程度上缓解了波形不连续(基音断裂)问题,但仍然造成了一系列失真。
波形相似叠加(Waveform similarity Overlap-Add WSOLA)
在上面的章节中我们已经明确了OLA算法的缺陷和导致缺陷的原因,为了减少这种相位跳变失真,一种直观的方式是调整那些连续的合成帧使得互相叠加的区域能够相位对齐,下图演示了WSOLA算法的基本思想。其中目前大名鼎鼎的soundtouch用的就是WSOLA方法
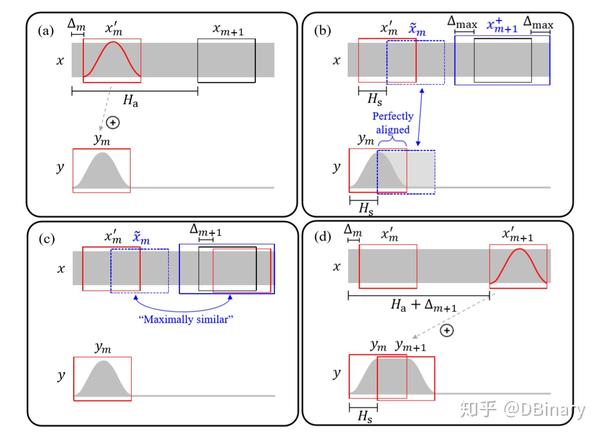

- 在原音频中截取一个帧,加窗
- 在一个范围内(蓝色虚线框)选取第二个帧,这个帧的相位参数应该和第一个帧相位对齐
- 在另一个范围内(蓝色实线框)中查找第三个帧,这个帧和第二个帧应该最相似
- 然后再把它们叠加在一块
那么,上述问题的主要问题就是,两个帧怎么样才是“最像”的,当然,要判断的办法很多,论文中给出了一种最直接的办法“自相关”(说通俗点就是每个样本点乘起来然后再加起来看看数值有多大),关于这个自相关,可以参考笔者关于傅里叶变换中正交性的讨论中得到一些启发
详细的数学表达可以转到论文中,这点并不复杂,笔者就不在这里进一步复述了。你可能已经意识到了,我们无法为所有的帧都找到最优匹配只能找到相对靠谱点的帧,因此WSOLA仅仅只是OLA方法的一种改进形式能够进一步减轻这种失真效应,但是遗憾的是,它仍然无法从根本上解决这种失真并可能导致一些新的问题
看下面图的栗子
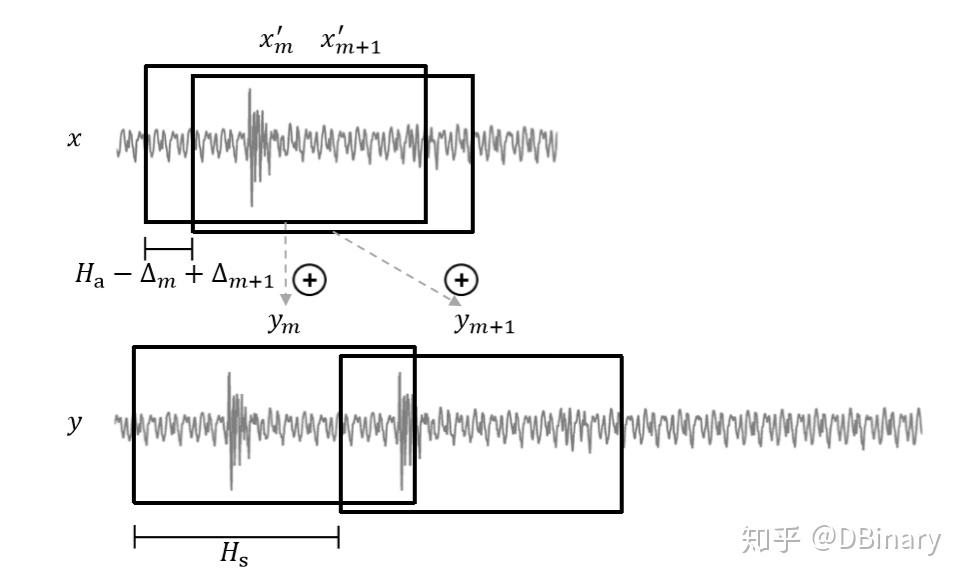

原音频信号截取一帧后,通过波形相似匹配下一帧,但两个帧都包含一个瞬态的音频信号,导致合成音频失真。(伸展信号通常会出现这种瞬态加倍失真,而压缩信号则容易发生瞬态跳跃),如果你将WSOLA应用于打击乐乐器的音频,这种现象将会更加的明显,正如我们之前在OLA中提到的那样,WSOLA与OLA相反并不适合处理这些冲击瞬态信号。
一个STFT的问题
在接下来讨论下一个问题时,我们首先要思考的一个问题是通过STFT变换的频域结果,是否是一个准确值呢,读者应该已经发现,当我们STFT样本数足够多的时候,我们能提高其频率分辨率,但不管如何,STFT始终是将信号分解为一组谐波关系的正弦组成,我们无法准确分辨出例如1.5HZ,6.8HZ之类的进一步细分准确的频率内容,于是,如何进一步估算其准确值,在我们进行频域操作与信号重构的过程中,是一个无法回避的问题.
但办法总是有的,我们发现,通过傅里叶变换后,一个复信号不仅包括当前波的频率,幅度信息也包括这个波的相位信息,通过相位的进一步计算,我们能够进一步估算这个波的频率误差,这也就是我们接下来要讨论的问题.
估算瞬时频率
讨论这一章节的目的,主要是为了之后要谈及的相位声码器,简单来说,通过STFT对连续的两个帧变换后,能够取得两个估算相位,对于某一个频率,可以使用相位信息对频率进行修正
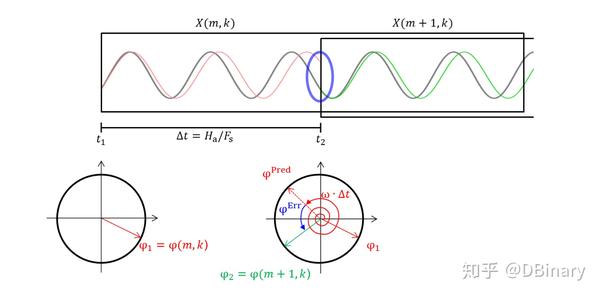

m-1和m分别是连续的两帧,时间间隔为 \triangle t , \varphi_{1} \varphi_{2} 分别是两帧启始相位,那么理想情况下应该有
\varphi_{2}=\varphi_{1}+w\Delta t
但实际上因为震荡(oscillates),可以看到,红色的正弦线和绿色的正弦线在交界处是相位不连续的,因此:
\varphi_{1} \ne \varphi_{2}
我们用 \varphi_{1} \varphi_{2} 的相位差 \varphi^{err} 来表示,就有
\varphi_{2}=\varphi_{1}+w\Delta t+\varphi^{err}
那么估算的瞬时频率应该是
IF(w)=w+\frac{\varphi^{err}}{\Delta t}
而这个频率,对应着上图的灰色正弦线,可以看到,相位已经被修正了,同时我们也能估算出它的瞬时频率,当然,瞬时的概念仅仅是说这个时间比较短,这个频率实际上覆盖在了整个分析帧中.
基于相位声码器的TSM(TSM Based on the Phase Vocoder简称PV-TSM)
这章是本文的重点,SoundLab使用的TSM方法也正是相位声码器,从上一章节可知,如果如果我们能知道信号的正弦组成成分,我们就能重构信号,但正如我们之前谈到的那样,STFT出于采样与分析帧长等一系列问题,其分辨率仅能够为我们提供一个估计频率频率值,而相位声码器就是通过利用给定的相位信息来完善STFT的初略频率估计的技术.
在理解完STFT和瞬时频率估算后,相位声码器的基本原理基本也就呼之欲出了,我们可以使用具体的频率信息重构出一个没有相位跳变的信号.
下图演示了相位声码器的基本流程


a.首先先对原音频信号进行分帧处理
b.通过STFT,对两个帧进行处理,计算其相位差,并依照瞬时频率估计章节的内容对其进行瞬时频率估算.
c.通过瞬时频率的计算后,我们可以重构出和m+1帧没有相位跳变的信号,下图的灰色正弦曲线正是通过瞬时频率估算后的频率曲线,可以看到它和下一帧的相位已经衔接上了.
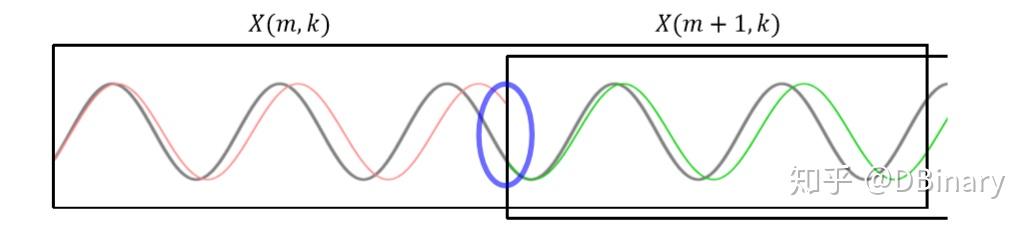

d.ISTF,也就是逆变换,重构时域信号[5]
相比于WSOLA,基于STFT的相位声码器的性能更加的稳定优异,同时其计算量相较于直接正弦建模(和相位声码器类似)颇具优势,适合对声音的实时处理,因此在SoundLab中,笔者采用了重采样与相位声码器的方案来实现变速不变调的功能呢.
关于合成窗的一些讨论
在参考5[5]中,笔者讨论了关于加窗信号的重叠叠加与信号重建,在之前的章节笔者提到过,使用hamming窗在本例中可能并不适合,而笔者使用的是sinc窗.
究其原因,重叠叠加的准则是尽可能还原信号而尽可能减少失真,一种方案是保持幅度一致,而另一种是保持能量一致,hamming窗在离散化后,其叠加仍然存在相当的失真(即使有做能量修正),相比之下,sinc窗的叠加保持的能量一致并在减少频率分析泄露中表现得更加良好,因为当窗函数在50%overlap时,只需要在分析时乘一次窗函数,在处理完成后再乘以一次窗函数,就能在overplap部分叠加为 sin^{2}x+cos^{2}x 形式的幅度一致
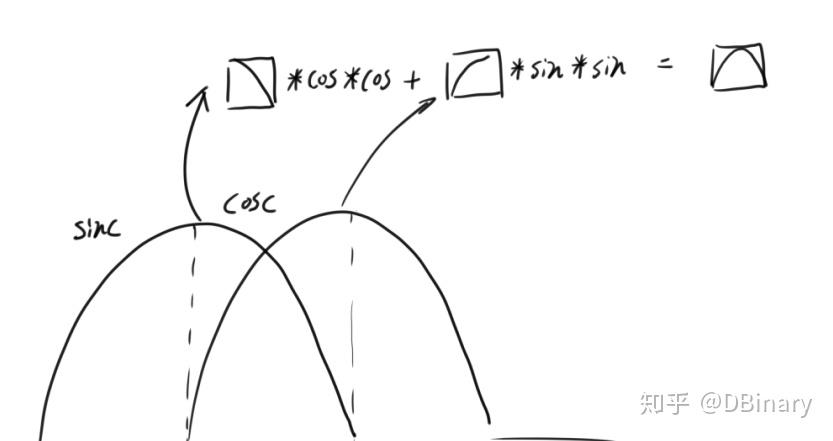

- 对原信号进行50%overlap的分帧
- 对分析信号加sinc窗
- STFT进行频域处理
- ISTFT逆变换
- 两分析帧再乘以sinc窗,那么叠加部分就是后半部分加前半部分,刚好变成了 cos^{2}x+sin^{2}x 的形式.
完成变声器的核心功能
读者应该已经发现,变声器的核心功能,就是变速不变调系统的实现,而变速不变调的实现,笔者的实现方案可以可以分为两个部分:
- 利用重采样,实现变调变速
- 利用相位声码器,实现变速不变调
综合上面两个算法,就能够实现一个变调不变速功能了,例如我们要将音调提高1.5倍,我们利用重采样变调,同时,信号长度变为了原来的2/3,然后我们使用相位声码器对其进行变速不变调处理,再将信号拓展1.5倍,这样我们就能得到一个和原信号等长的变调不变速信号了,当然,该功能已经封装在SoundLab当中了,在下面的视频中,你看到笔者使用soundlab完成一段男声的"变声"效果.
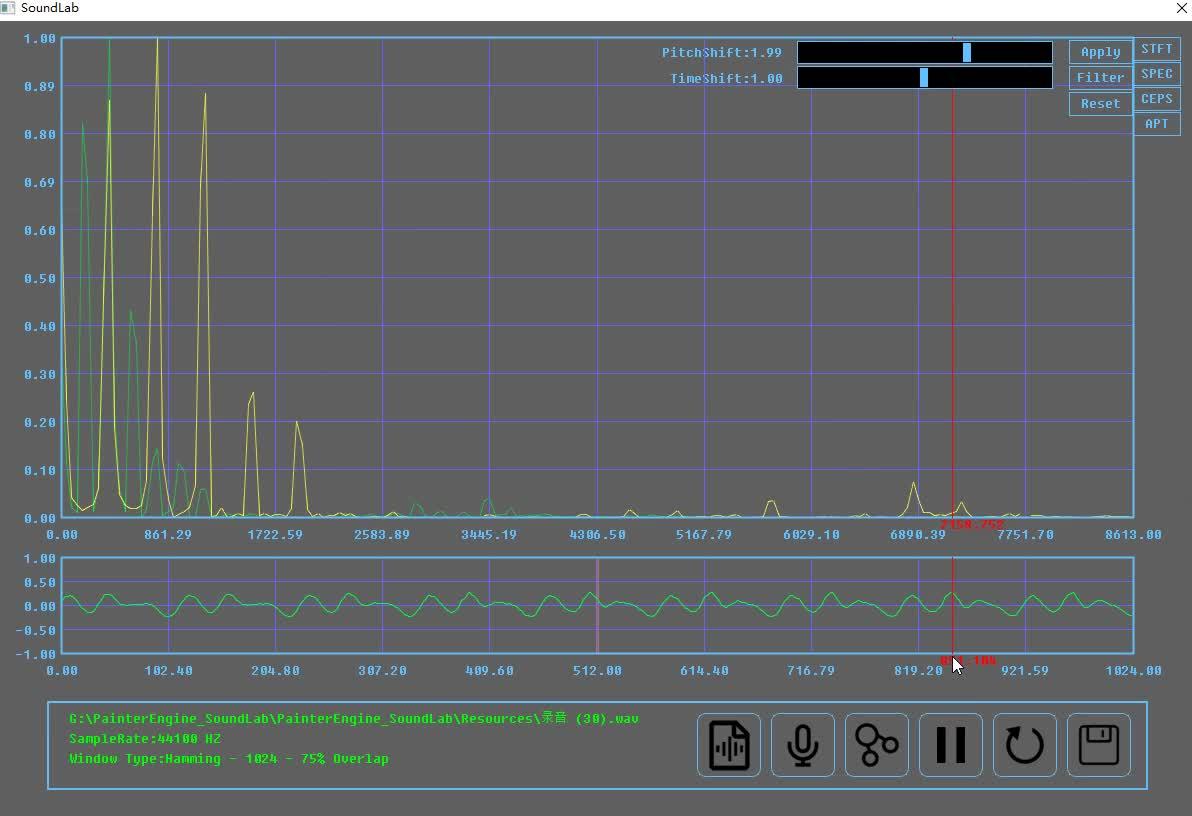 男声变调效果演示https://www.zhihu.com/video/1219945045589450752
男声变调效果演示https://www.zhihu.com/video/1219945045589450752遗憾的是,即使洋洋洒洒写了那么长的内容,我们也完成了变声器的核心功能实现.但距离一个高质量的变声器我们仍然有很长的路要走(但做到这一步,基本已经能完爆一大片市面上那堆连基音断裂都处理不好的变声器了),鉴于篇幅关系,本篇文章作为本系列的第一篇文章,先做个开胃菜效果,敬请续作关注变声导论-变声器原理及实现(基音分类与滤波系统实现),在下一篇文章中,我们将进一步讨论男声与女声的差别,讲述倒谱与基音频率估算,基于BP神经网络与MFCC的语音识别,并使用滤波器与频域补偿进行声学建模让声音听上去更加的自然.
代码与附录
现在,相关的核心算法(变速不变调)代码已经集成在了PainterEngine当中,归属于PX_Tuning.h,PX_Tuning.c,如果你想制作自己的变声器,你现在就可以下载PainterEngine来完成了,同时SoundLab已经完整开源,你可以在本文首页处,找到PainterEngine和soundlab的完整代码.如果你有相关疑问,你可以直接私信笔者发上你的问题
参考
- ^基2快速傅里叶变换 https://zhuanlan.zhihu.com/p/77388996
- ^A Review of Time-Scale Modification of Music Signals https://www.mdpi.com/2076-3417/6/2/57
- ^abc时域压拓 https://zhuanlan.zhihu.com/p/101198499
- ^频域泄露 https://blog.csdn.net/u014122266/article/details/43242905
- ^ab重叠叠加与信号重建 https://zhuanlan.zhihu.com/p/104985345
