TSM时域压扩(变速不变调)算法总结

本文图片和原理大多来自


先感谢并致敬论文和书籍作者大佬们
本人并非全才,文中疏漏错误,还望读者不吝指正。
摘要
时域压扩(Time-scale modification简称TSM,又叫变速不变调)是一个能够改变音频的"语速"而不改变其音调的算法,是一个在目前音频信号处理中必不可少的一种重要算法,然而音频信号是多种多样的(包含了各种谐波(基音,泛音)冲击和瞬态分量),因为这种广泛的声学和音频特性,因此,目前没有一种能够通用的TSM算法,你需要依据音频特性来选择合适的TSM方法,本文的目的也就是科普一系列TSM算法并对它的特性与局限性进行讨论。
为此,我们先回顾一些基础的TSM方法,讨论一些比较典型的TSM相关问题,同时针对这些问题也给出一系列解决方案,特别的,本文要讨论一种音频融合算法(也就是WSOLA了),其中涉及了一些谐波(泛音)分离的最新技术和时域、频域相关的TSM程序。
介绍
时域压扩(Time-scale modificatio) 算法简单说就是能改变"语速"不改变"语调"(改变速度不改变音调)的一种音频处理算法,当然,这是理想状态下的效果,很多时候这种算法会有各种各样的问题,为啥捏,这里卖个关子往下看你就知道了,那么TSM算法适用于哪些场景呢,按论文的说法是,它让音乐创作和混音变得简单,比如你在B站看到的那些二次创作的鬼畜,或者来说你想变声成可爱的女孩纸,那么在使用例如重采样方法进行变调(重采样变调的同时也会变速)后,你还得依靠TSM方法把语速变回来这样才不会导致“乔碧萝”惨案。同样的,除了很多“不正当”用途外,TSM也广泛应用于各类正当用途,比如作为一个Dj你完全可以把一个让人听着想睡的音乐听起来像是打了鸡血。
然而TSM算法面临各种各样的挑战,我们听到的声音往往有多种不同的音源,比如小提琴和响板一起演奏,在理想情况下,TSM必须保持小提琴的音色和音调,但是响板的“click” “click”“click”的声音没有音调,在变调的过程中,如何保证响板的声音不被抹掉就显得更为的重要,为了保持音乐的节奏,你就需要知道这些响板声音出现的位置。
因此,保持这些声学特性并非易事,你往往需要使用不同的TSM方法,例如基于波形相似重叠叠加算法(WSOLA)或者是相位声码器(PV-TSM)就能够在很大程度上保留这些谐波信号的质量但同时也很容易引入一系列的瑕疵(失真),因此通常使用不同的TSM方法对音频信号进行分类处理,比如把音频中的谐波信号和冲击信号给区分开来,然后分类处理后在合到一块。
那么,本文的目标就有2个,一个是回顾一些经典的TSM算法并讨论他们的优缺点然后改进他们,之后,聊聊两类比较有代表性的TSM算法,分别是时域WSOLA类算法和频域PV-TSM算法。
变速不变调(TSM)的基本原理
变速不变调,顾名思义,改变速度不改变音调,大部分的TSM算法,都可以用下图进行解释
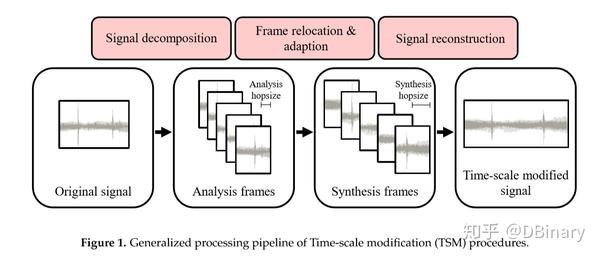

简单来说,就是把一段音频信号等分成不同的帧,帧的长度大多选取是50ms到100ms之间度,然后对每个帧进行一系列处理比如拉伸或者压缩,最后在将这些帧重新叠加成合成信号(当然很多的TSM方法中两个帧叠加时常常是由重叠部分(overlap)的)当然这个重叠部分需要进行一系列的处理以减少类似于相位不连续、幅度波动造成的影响,上述这个过程在论文中有一个数学的表达方式(当然有些内容是笔者依据自己经验加上去的),但不管是文字表达还是数学表达基本意思大致如此,如果有兴趣可以转到论文中去详细查看。
最直接暴力的一种TSM方式(重叠叠加OLA)
这个很好解释,把音频信号分帧处理后,直接把这些处理后的信号首位拼接起来,比如一个最简单粗暴的方式,比如要把一段音频信号的语速放慢,只需要每一个帧都进行延扩,然后在首位拼接起来就行了,但造成的劣势也是显而易见的,它会造成拼接处的波形不连续(语音信号中的基音断裂),于是拼接的信号中会有biu吱biu吱的奇怪的声音。

为了减轻这种波形不连续造成的影响,上一章节我们也提到了,两个帧之间需要留一点重叠的部分,同时,对每一个帧进行加窗处理,在OLA中,常常使用汉宁窗对帧进行加窗叠加。那么,一个音频变速的叠加算法的流程如下图所示


- 首先对音频时域进行分帧,
- 加上汉宁窗
- 间隔 H_{a} 取第二个帧
- 对第二个进行加窗,并与第一个窗进行叠加,叠加的长度是 H_{s}
上述加窗在一定程度上缓解了波形不连续(基音断裂)问题,但仍然造成了一系列失真。
我那么努力了,为什么还会失真
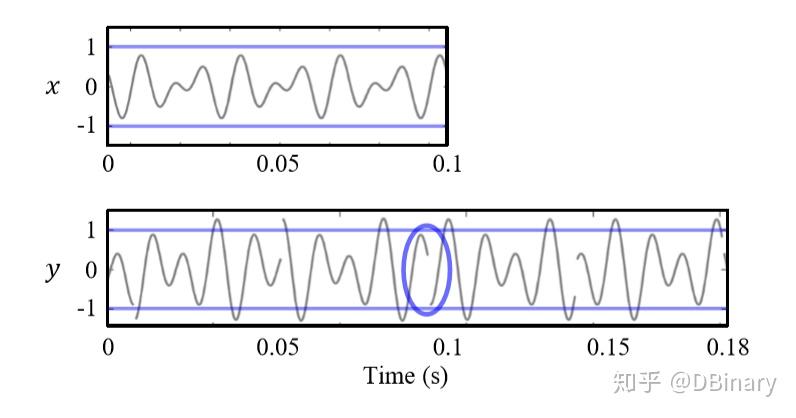
首先最直观的,OLA常常无法保持信号中的周期性结构,在帧裁剪的过程中,你没办法保证每一个帧都能覆盖完整周期并保证其相位对齐,这种失真也叫相位跳跃失真(phase jump artifacts),那么重点来了,因为音频信号中的局部周期性与谐音(基音、泛音)相对应,因此OLA并不适合处理这类信号,至少处理的效果不咋样。

不过OLA并非是一无是处,对于一些纯打击乐来说,OLA还是能取得非常好的效果的(打击乐音频很少有局部周期结构),重要的是,帧长应该尽量选的比较小(比如10ms)以减少瞬态加倍引起的影响。
波形相似叠加(Waveform similarity Overlap-Add WSOLA)
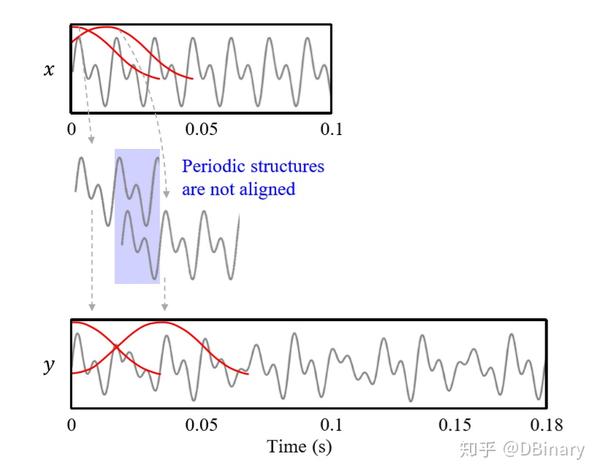
在上面的章节中我们已经明确了OLA算法的缺陷和导致缺陷的原因,为了减少这种相位跳变失真,一种直观的方式是调整那些连续的合成帧使得互相叠加的区域能够相位对齐,下图演示了WSOLA算法的基本思想。
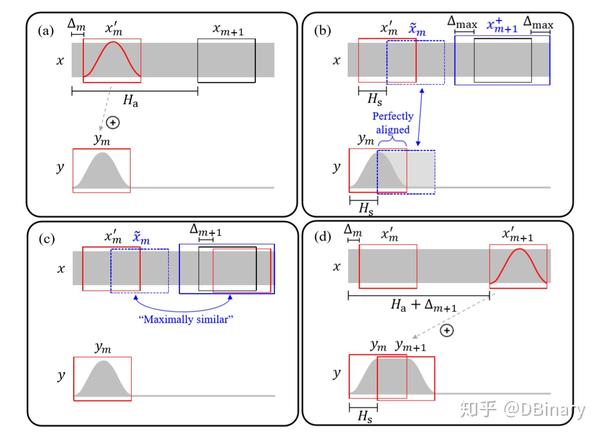

- 在原音频中截取一个帧,加窗
- 在一个范围内(蓝色虚线框)选取第二个帧,这个帧的相位参数应该和第一个帧相位对齐
- 在另一个范围内(蓝色实线框)中查找第三个帧,这个帧和第二个帧应该最相似
- 然后再把它们叠加在一块
那么,上述问题的主要问题就是,两个帧怎么样才是“最像”的,当然,要判断的办法很多,论文中给出了一种最直接的办法“自相关”(说通俗点就是每个样本点乘起来然后再加起来看看数值有多大),关于这个自相关,可以参考笔者关于傅里叶变换中正交性的讨论中得到一些启发
详细的数学表达可以转到论文中,这点并不复杂,笔者就不在这里进一步复述了。
Sorry,WSOLA仍然无法完全解决根本问题
你可能已经意识到了,我们无法为所有的帧都找到最优匹配只能找到相对靠谱点的帧,因此WSOLA仅仅只是OLA方法的一种改进形式能够进一步减轻这种失真效应,但是遗憾的是,它仍然无法从根本上解决这种失真并可能导致一些新的问题
看下面图的栗子
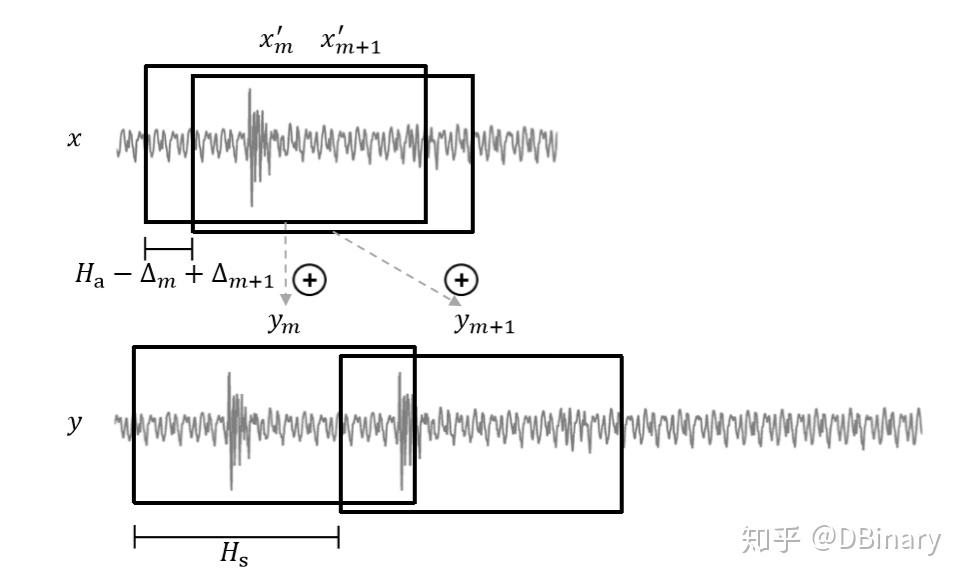

原音频信号截取一帧后,通过波形相似匹配下一帧,但两个帧都包含一个瞬态的音频信号,导致合成音频失真。(伸展信号通常会出现这种瞬态加倍失真,而压缩信号则容易发生瞬态跳跃),如果你将WSOLA应用于打击乐乐器的音频,这种现象将会更加的明显,正如我们之前在OLA中提到的那样,WSOLA与OLA相反并不适合处理这些冲击瞬态信号。
WSOLA的一点建议
为了让wsola可以更好的工作,每一个帧应该至少能覆盖整个音频周期,此外,公差参数 \Delta max 应该足够大以进行适当的调整(就是WSOLA开篇下面那张图b中的 \Delta max ),因此应该至少设置为半个周期,因此对应于50ms的帧长对应25ms长度的容差参数,同时应该尽量避免那些包含瞬态信号的区域或者直接将瞬态信号复制到输出中。
音频分离
正如我们所见,WSOLA能够尽可能的保持输入音频信号的周期性,但它仍然存在诸多的缺陷,那么,我们下一步的工作就是提升其质量,为此如果我们将音频信号当做是一系列正弦信号的谐波组合,那么如果将它每个分析帧分解为对应频率和相位的正弦信号加权和,然后根据这些参数,对每个分量进行操作并重构,这样就能避免频域上出现的相位跳变失真了.而这正是我们频域算法要做的,为此,我假设读者已经熟悉了傅里叶变换中的那些关系,如果你对这方面的知识仍然抱有疑惑,你可以在下面的文章与回答中找到答案
但是,鉴于分析帧的样本数目与短时傅里叶变换在实际使用中分辨率的关系,其离散化的参数估计可能并不准确,为此,我们使用相位声码器通过推导正弦分量的瞬时频率来改善短时傅里叶变换的粗略估计,而这也就是我们接下来要讨论的东西,不过在此之前,先来谈谈Modified STFT。
Modified STFT(简称MSTFT)在笔者开篇的下面那本蓝皮书的第八章有关于这个的详细讨论
就是这本书:Müller, M. Fundamentals of Music Processing; Springer International Publishing: Cham, Switzerland, 2015.
简单来说,MSTFT是用于分离频域冲击和谐波的一种方法.
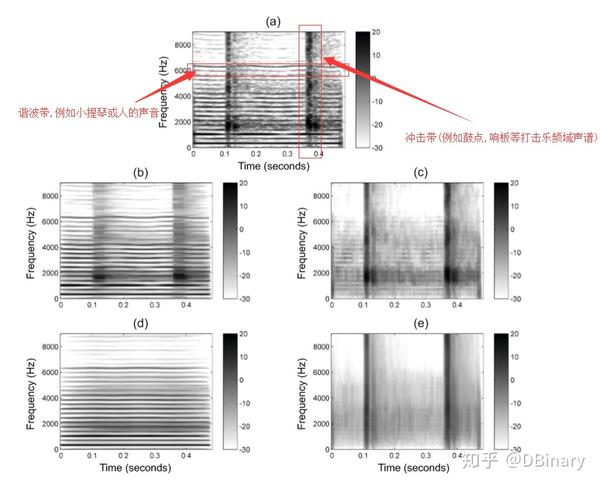

通过音频分解(Audio Decomposition),MSTFT的频域参数在公式中用 X^{mod} 进行表示,通过iSTFT(STFT逆变换)
x_{}^{Mod}(r)=\frac{1}{N}\sum_{k=0}^{N-1}{X^{mod}(k)e^{2\pi ikr/N}}
取得一个 x_{}^{Mod}(r) ,需要注意的是,这里的 x_{}^{Mod}(r) 并非是一个有效的重构信号,但却有一些办法能够计算误差修正让 x_{}^{Mod}(r) 近似等于 x_{}^{}(r) (重构信号)
设 y_{m}(r) 为第m个分析帧,有
y_{m}(r)=\frac{window(r)x_{m}^{Mod}(r)}{\sum_{n\in Z}^{}{(r-nH_{s})^{2}}}
最后,通过
y(r)=\sum_{m\in Z}^{}{y_{m}(r-mH_{s})}
重构信号.
估算瞬时频率
简单来说,通过STFT对连续的两个帧变换后,能够取得两个估算相位,对于某一个频率,可以使用相位信息对频率进行修正
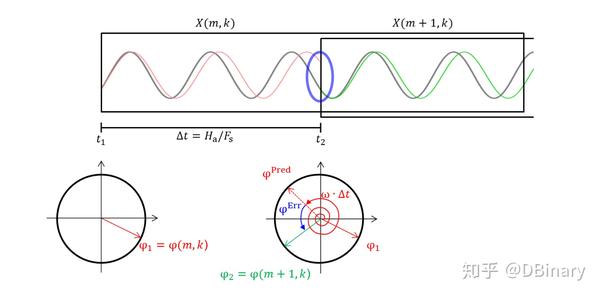

m-1和m分别是连续的两帧,时间间隔为 \triangle t , \varphi_{1} \varphi_{2} 分别是两帧启始相位,那么理想情况下应该有
\varphi_{2}=\varphi_{1}+w\Delta t
但实际上因为震荡(oscillates),可以看到,红色的正弦线和绿色的正弦线在交界处是相位不连续的,因此:
\varphi_{1} \ne \varphi_{2}
我们用 \varphi_{1} \varphi_{2} 的相位差 \varphi^{err} 来表示,就有
\varphi_{2}=\varphi_{1}+w\Delta t+\varphi^{err}
那么估算的瞬时频率应该是
IF(w)=w+\frac{\varphi^{err}}{\Delta t}
而这个频率,对应着上图的灰色正弦线,可以看到,相位已经被修正了
基于相位声码器的TSM(TSM Based on the Phase Vocoder简称PV-TSM)
如果我们能知道信号的正弦组成成分,我们就能重构信号,但正如我们之前谈到的那样,STFT出于采样与分析帧长等一系列问题,其分辨率仅能够为我们提供一个估计频率频率值,而相位声码器就是通过利用给定的相位信息来完善STFT的初略频率估计的技术.
在理解完Modified STFT和瞬时频率估算后,相位声码器的基本原理基本也就呼之欲出了,我们可以使用具体的频率信息重构出一个没有相位跳变的信号.
下图演示了相位声码器的基本流程


a.首先先对原音频信号进行分帧处理
b.通过Modified STFT,对两个帧进行处理,计算其相位差,并依照瞬时频率估计章节的内容对其进行瞬时频率估算.
c.通过瞬时频率的计算后,我们可以重构出和m+1帧没有相位跳变的信号,下图的灰色正弦曲线正是通过瞬时频率估算后的频率曲线,可以看到它和下一帧的相位已经衔接上了.
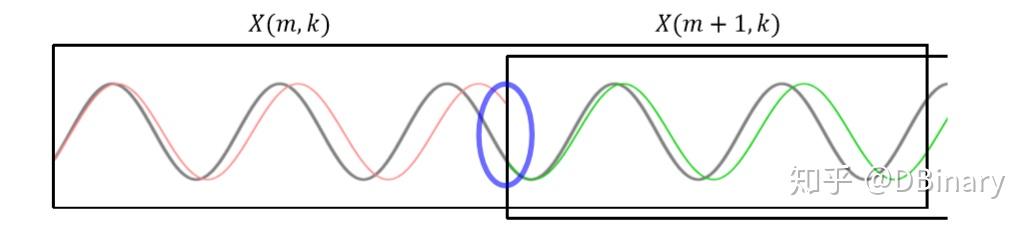

d.再根据MSTFT章节的内容,重构时域信号,
