数据库计算引擎的优化技术:向量化执行与代码生成

作者:徐飞,李德竹
随着数据库软硬件技术的发展,经典的 SQL 计算引擎逐渐成为数据库系统的性能瓶颈,尤其是对于涉及到大量计算的 OLAP 场景。如何进一步提升 SQL 计算引擎的性能成为数据库从业者们的热门研究方向,无论是学术界还是工业界都对此作了大量的努力,而向量化执行与代码生成正是在这一过程中实践总结出来的两种有效方法,在新一代的数据库系统中,大多都能看到这两种技术的运用。本文主要对这两种技术的原理及好处进行简单的介绍。
SQL 中的计算
SQL 是一种声明式语言,用户通过 SQL 语句向数据库发起计算请求,SQL 中的计算主要包括两类:expression 级别的计算和 operator 级别的计算。以下面这条 SQL 为例:
select c1 + 100, c2 from t where c1 < 100 and c3 = 10
该 SQL 包含了 3 个 operator:tablescan,selection 和 projection,而每个 operator 内部又包含了各自的 expression,例如 selection 内部的 expression 为c1 < 100 and c3 = 10,projection 内部的 expression 则为c1 + 100和c2。
经典的 SQL 计算引擎
经典的 SQL 计算引擎在 expression 层面一般采用 expression tree 的模型来解释执行,而在 operator 层面则大多采用火山模型。
Expression 一般有如下定义:
class Expression {
// 由于返回值类型是不定的,因此往往会用万能值对象包裹
Datum eval(Row input);
Expression children[];
}
上述 SQL 中的 filter 条件对应的 expression tree 就如下图所示:
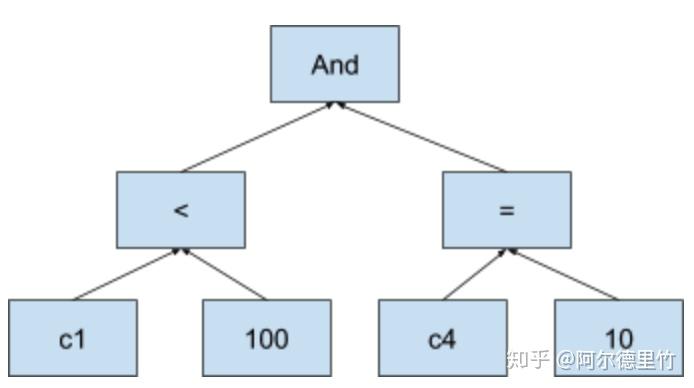

与 Expression tree 类似,在火山模型中,operator 也被组织为 operator tree 的形式,operator 之间则通过迭代器来串联。Operator 一般有如下定义:
class Operator {
Row next();
void open();
void close();
Operator children[];
}
在具体的 operator 中一般包含其需要计算的 expression,例如:
class Projection extends Operator {
Expression projectionExprs[];
Row next() {
Row output = new Row(projectionExprs.length);
Row input = children[0].next();
for (int i = 0; i < projectionExprs.length; i++) {
output.set(i, projectionExprs[i].eval(input));
}
return output;
}
}
这样上述 SQL 在数据库中实际上会被编译为如下的 operator tree:
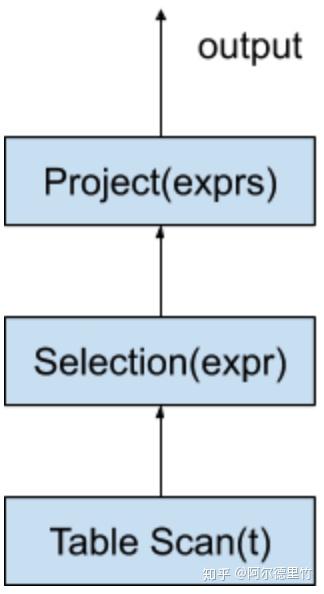
火山模型的最大好处是实现简单,每个 operator 都只需要完成其自身特定的功能,operator 之间是完全解耦合的,SQL complier 只需要根据 SQL 的逻辑构造对应的 operator 然后将 operator 串联起来即可。
上面这套模型诞生于上世纪九十年代,对于那时候的数据库产品,IO 速度是远小于计算速度的,所以计算引擎上的提速对整体数据库的提速效果并不多,大部分数据库优化更偏向于怎么更快的读取数据,但是随着近年来数据库存储组件越来越快,数据库从业者们发现计算速度也逐渐成为了数据库的一个瓶颈。从 expression 和 operator 两个层面来看,经典的计算模型都显得有点笨重:
Expression层面:基于 expression tree 的解释执行往往使得一些看上去很简单的表达式执行起来很复杂,以上述 SQL 的 filter 条件为例:c1 < 100 and c3 = 10 这个过滤条件在数据库中会被转换为包含 7 个节点的 expression tree,对于表中的每行数据,这 7 个节点的 eval 函数都会被触发一次。而实际上,这个 expression tree 的效果与下面这段手写代码是等价的:
(input.getInt(0) < 100 && (input.getInt(2) == 10)
相比之下 expression tree 的解释执行就显得笨重很多。而且由于虚函数调用,即使是最简单的求值函数也基本无法被内联。
Operator 层面面临的问题与 Expression 类似,火山模型虽然带来了实现简单、干净的好处,但是每次计算一行结果都会有一个很长的 next 虚函数调用链(而且 operator next 函数中一般还会有一个 expression eval 的虚函数调用链)。虽然虚函数调用本身开销并不算特别大,但是仍需要花费一定的时间,而虚函数内部的操作可能就是一个简单的轻量级计算,而且每一行数据都需要若干次的虚函数调用,当数据量非常大的时候,这个开销就会变得十分可观。
除了虚函数带来的计算框架开销外,经典计算引擎还有一些其他缺点,试想上述 SQL 在火山模型中生成相应的 plan 后,其运行时的代码如下:
for(; Row row = plan.next(); row != null) {
// send to client
}
其中 plan 即 operator tree 的 root 节点,对上述 SQL 来说就是 projection。
而如果手动写一段代码来实现上述 SQL 的话,其代码大概如下:
for(Row row in scanBuffer) {
int c1 = row.getInt(0);
int c3 = row.getInt(2);
if (c1 < 100 && c3 == 10) {
// construct new row and send to the client
}
}
上述两段代码虽然都是一个 for 循环,但是对于第一段代码来说,for 循环里面是很深的虚函数调用,而第二段代码 for 循环里做的事则要简单的多。对 compiler 来说,越简单的代码越容易优化,在这个例子中,compiler 就可以通过将c1和c3放在寄存器中来实现提速。
SQL 计算引擎的优化
从上面的介绍来看,经典 SQL 的计算引擎一个很大问题就是无论是 expression 还是 operator ,其计算的时候都大量使用到虚函数,由于每行数据都需要经过这一系列的运算,导致计算框架开销比较大,而且由于虚函数的大量使用,也影响了编译器的优化空间。在减小框架开销方面,两个常用的方法就是
- 均摊开销
- 消除开销
向量化执行与代码生成正是数据库从业者们在这两个方向上进行的努力。
向量化执行
向量化执行的思想就是均摊开销:假设每次通过 operator tree 生成一行结果的开销是 C 的话,经典模型的计算框架总开销就是 C * N,其中 N 为参与计算的总行数,如果把计算引擎每次生成一行数据的模型改为每次生成一批数据的话,因为每次调用的开销是相对恒定的,所以计算框架的总开销就可以减小到C * N / M,其中 M 是每批数据的行数,这样每一行的开销就减小为原来的 1 / M,当 M 比较大时,计算框架的开销就不会成为系统瓶颈了。除此之外,向量化执行还能给 compiler 带来更多的优化空间,因为引入向量化之后,实际上是将原来数据库运行时的一个大 for 循环拆成了两层 for 循环,内层的 for 循环通常会比较简单,对编译器来说也存在更大的优化可能性。举例来说,对于一个实现两个 int 相加的 expression,在向量化之前,其实现可能是这样的:
class ExpressionIntAdd extends Expression {
Datum eval(Row input) {
int left = input.getInt(leftIndex);
int right = input.getInt(rightIndex);
return new Datum(left+right);
}
}
在向量化之后,其实现可能会变为这样:
class VectorExpressionIntAdd extends VectorExpression {
int[] eval(int[] left, int[] right) {
int[] ret = new int[input.length];
for(int i = 0; i < input.length; i++) {
ret[i] = new Datum(left[i] + right[i]);
}
return ret;
}
}
显然对比向量化之前的版本,向量化之后的版本不再是每次只处理一条数据,而是每次能处理一批数据,而且这种向量化的计算模式在计算过程中也具有更好的数据局部性。
代码生成
代码生成的思想是消除开销。代码生成可以在两个层面上进行,一个是 expression 层面,一个是 operator 层面,当然也可以同时在 expression 与 operator 层面进行代码生成。经典 SQL 计算引擎的一大缺点就是各种虚函数调用不但会带来很多额外的开销,而且还挤压了 compiler 的优化空间。代码生成可以直观的理解为在 SQL plan build 好之后,将 plan 中的代码进行一次逻辑上的内联。如果实现的好,代码生成能够将上述所说的火山模型代码转换为类似于手动优化的代码,显然和向量化执行一样,代码生成后的新代码也给编译器带来了更多的优化机会。与向量化执行相比,代码生成之后数据库运行时仍然是一个 for 循环,只不过这个循环内部的代码从简单的一个虚函数调用plan.next()展开成了一系列具体的运算逻辑,这样数据就不用再各个 operator 之间进行传递,而且有些数据还可以直接被存放在寄存器中,进一步提升系统性能。当然为了获取这些好处代码生成也付出了一定的代价,代码生成需要在 SQL 编译器编译获得 plan 之后进行额外的 code gen + jit ,对应到具体的工程实现也比向量化执行的难度要高一些。 举例来说,对于下面这条 query:
select *
from R1,
(select R2.y, count(*)
from R2
where R2.x=3
group by R2.y) R2
where R1.a=7 and R1.b=R2.y通过代码生成技术,其执行过程会变成这样:
map<int, vector<Row>> hash_table_for_join;
map<int, int> hash_table_for_agg;
for(Row row in scanBuffer_R1) {
int a = row.getInt(0);
int b = row.getInt(1);
if (a == 7) {
// ignore the case when the key `b` doesn't exists for simplicity
hash_table_for_join[b].push_back(row);
}
}
for(Row row in scanBuffer_R2) {
int x = row.getInt(0);
int y = row.getInt(1);
if (x == 3) {
// ignore the case when the key `y` doesn't exists for simplicity
hash_table_for_agg[y] = hash_table_for_agg[y] + 1;
}
}
for (auto &v1 : hash_table_for_agg) {
for (auto &v2 : hash_table_for_join) {
if (v1.first == v2.first) {
// construct new row and send to the client
}
}
}
相比于传统的火山模型,上述执行过程不再以 operator 为核心,而是以数据为核心,其最大特征是将单一 operator 的执行逻辑分散在多个代码块中,模糊了 operator 之间的执行边界,从而大大降低了 operator 之间数据传递的开销。
总结
向量化执行和代码生成是现代数据库中常用的两种执行优化技术,本文通过几个案例简单地阐述了这两种技术的基本思想。这两种技术从不同角度提高了数据库 query 的执行效率,关于这两种技术更多详细的介绍可以参考这两篇论文:Everything You Always Wanted to Know About Compiled and Vectorized Queries But Were Afraid to Ask, Efficiently Compiling Efficient Query Plans for Modern Hardware
