深度学习多分类任务的损失函数详解

多分类问题一般用softmax作为神经网络的最后一层,然后计算交叉熵损失。
TensorFlow中的tf.nn.softmax_cross_entropy_with_logits函数可以直接计算多分类损失。
tf.nn.softmax_cross_entropy_with_logits(
labels,
logits,
axis=-1,
name=None
)输入labels是标签向量,形状为[batch_size, num_classes],每一行的labels[i]必须符合有效的概率分布。
输入logits是神经网络最后一层的输出,形状与labels相同。注意logits不需要在神经网络最后一层通过softmax函数,因为tf.nn.softmax_cross_entropy_with_logits函数已经把softmax和交叉熵结合在一起了。
输出是一组包含softmax交叉熵损失的张量。其类型与logits相同,形状与labels相同。
TensorFlow官方文档对于softmax_cross_entropy_with_logits交叉熵损失的函数的解释是:
Measures the probability error in discrete classification tasks in which the classes are mutually exclusive (each entry is in exactly one class). For example, each CIFAR-10 image is labeled with one and only one label: an image can be a dog or a truck, but not both.
此外,还有tf.nn.sparse_softmax_cross_entropy_with_logits,它们的区别仅仅在于labels,softmax_cross_entropy_with_logits是one-hot输入,而sparse_softmax_cross_entropy_with_logits的label是是int型,输入shape为[batch_size]。
softmax原理
Softmax函数的作用就是将每个类别所对应的输出分量归一化,使各个分量的和为1。可以理解为,能将任意是输入值转化为概率。Softmax主要用于多分类任务的激活函数,一般用在神经网络的输出端。

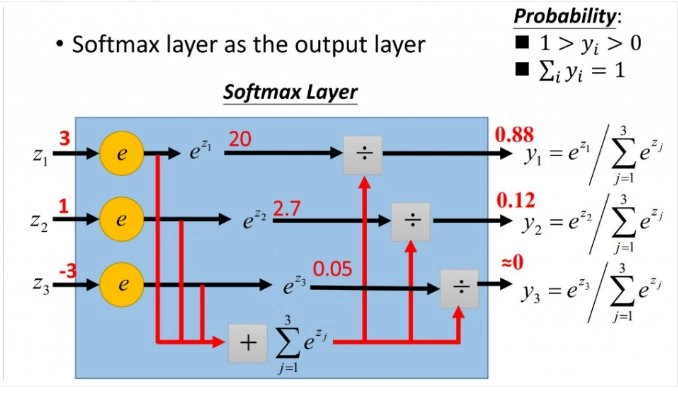
Softmax的计算步骤如下:
- 算出求出e关于输入向量的每个元素的的幂;
- 将所有的幂相加,得到分母
- 每一个幂,作为相应位置输出结果的分子
- 输出的概率=分子/分母
计算公式为:
s\left( x_{i} \right)=\frac{e^{x_{i}}}{\sum_{j=1}^{n}{e^{x_{j}}}}


看一个简单是例子,比如输入向量为[-1,0,3,5],softmax的计算结果如下表。


最后附上吴恩达老师关于softmax的详细讲解——
 吴恩达-softmaxhttps://www.zhihu.com/video/1196526508955746304
吴恩达-softmaxhttps://www.zhihu.com/video/1196526508955746304交叉熵损失函数的原理
交叉熵是信息论领域的一种度量方法,它建立在熵的基础上,通常计算两种概率分布之间的差异。
交叉熵损失函数经常用于分类问题中,特别是神经网络分类问题。交叉熵是用来描述两个分布的距离的,神经网络训练的目的就是使 g(x) 逼近 p(x)。
相对于sigmoid求损失函数,在梯度计算层面上,交叉熵对参数的偏导不含对sigmoid函数的求导,而均方误差(MSE)等其他则含有sigmoid函数的偏导项。Sigmoid的值很小或者很大时梯度几乎为零,这会使得梯度下降算法无法取得有效进展,交叉熵则避免了这一问题。
为了弥补 sigmoid 型函数的导数形式易发生饱和(saturate,梯度更新的较慢)的缺陷,可以引入Softmax作为预测结果,计算交叉熵损失。由于交叉熵涉及到计算每个类别的概率,所以在神经网络中,交叉熵与softmax函数紧密相关。
在二分类的情况下,模型最终预测的结果只有2类,对于每个类别我们预测的概率为p和1-p。
此时Binary Cross Entropy为:
J=-[y·log(p)+(1-y)·log(1-p)]
其中:
- y : 样本标签,正样本标签为1,负样本标签为0
- p : 预测为正样本的概率
而本问题题主关心的是多分类,多分类的交叉熵损失可表示为:
J= - \sum\limits_{i = 1}^K {{y_i}\log ({p_i})}
其中:
- K是种类数量
- y是标签,也就是如果类别是i,则 y_i =1,否则等于0
- p是神经网络的输出,也就是指类别是i的概率。这个输出值就是用上文提到的softmax计算得来的。
最后附上吴恩达老师详细讲解交叉熵损失的视频。
 吴恩达-loss functionhttps://www.zhihu.com/video/1196524375632035840
吴恩达-loss functionhttps://www.zhihu.com/video/1196524375632035840