说话人识别中取到i-vector之后怎么做分类?i-vector又是如何推导?
6 个回答

最近新添加了PLDA的数学推导,搭配i-vector食用能更全面QAQ
下面修正了关于T矩阵特点的描述~感谢 @Coast 的指出
另外附上更为详细的i-vector推导过程(但整个推导过程还是过于麻烦==||,所以有些地方我会打马虎眼,请别介意)~~
假设训练集有 S 句话,有 S = \left \{ 1, 2, ..., s \right \}
第 s 句话有 H(s) 帧,其每帧的声学特征有 D 维,则每句语音的声学特征矩阵如下:
X(s) = \left [ x_1, x_2, ..., x_i, ..., x_H(s)\right ]
所以 X(s) 是以帧数为行,维度为列;
假设GMM-UBM有 C 个高斯分量,而第 c 个单高斯的参数则为: \lambda = \left \{ \pi _c, \mu _c, \Sigma _c \right \}^C_{c=1}
并从已训练完成的UBM中,提取出其每个高斯的均值矢量,拼接成如下形式:
m = \left [ \mu _1^T, \mu_2^T,...,\mu_c^T \right ]^T
其中 m 是一个 C \cdot D 的超矢量,因此也被叫做均值超矢量;
先直接给出我们的目标函数(最熟悉最出名的那条公式):
M(s) = m + Tw(s) (1)
其中, T 是总变化矩阵,其维度是 C \cdot D \times R ; w(s) 是 R 维的隐变量i-vector,其是符合高斯分布; M(s) 是经过GMM-UBM的MAP后获得的第 s 句话的均值超矢量;在(1)中,其实需要估计的就参数 T ,而 w(s) 则是隐变量i-vector;
此时,我再给出B-W的3种充分统计量,这是给后面EM估计 T 时要用到的:
对于第 c 个单高斯,第 s 句话的充分统计量如下:
N_c(s) = \sum_{i=1}^{H(s)}P_\lambda(c|x_i)
F_c(s) = \sum_{i=1}^{H(s)}P_\lambda(c|x_i)(x_i - \mu_c)
S_c(s) = \sum_{i=1}^{H(s)}P_\lambda(c|x_i)(x_i - \mu_c)(x_i - \mu_c)^T
若把该句话的所有高斯分量的充分统计量整合起来成矩阵形式,则如下:
N(s) = \begin{bmatrix} N_1(s)I & & 0 \\ & ... & \\ 0 & & N_c(s)I \end{bmatrix} (2)
F(s) = \begin{bmatrix} F_1(s)\\ ...\\ F_c(s) \end{bmatrix} (3)
其中 N(s) 是一个主对角线矩阵。
好了,现在开始推导T矩阵的EM公式==||,其中E步比较复杂。。。
对于E步,第 t 次迭代期望的Q函数如下(4):
Q(T|T^{(t)})=\sum_{s=1}^SE(logP_T(X(s), w(s))) \\ = \sum_{s=1}^SE(logP_T(X(s)|w(s))) + \sum_{s=1}^SE(logP_T(w(s)))
此步是把观测数据 X(s) 和隐数据 w(s) 的条件概率拆开,展开为似然概率与边缘概率的乘积,可以参考《统计学习方法》的(9.12)公式;
由于(4)中的第二项是边缘概率,与 T 无关,所以在M步中会被偏导置零,这里就先提前忽略掉,继续展开(4):
Q(T|T^{(t)}) = \sum_{s=1}^S E(logP_T(X(s)|w(s)) \\ = \sum_{s=1}^S E(G(s) + H_T(s, w(s)))
其中, G(s) 是和二阶统计量的相关项,但跟 T 估计无关的,所以也提前忽略;
而 H_T(s, w(s)) 则与零阶、一阶、 T 和 w(s) 都相关的一项,其可展开为:
H_T(s, w(s)) = w(s)^TT^T\Sigma ^{-1}F(s) - \frac{1}{2}w(s)^TT^T\Sigma^{-1}N(s)Tw(s) (5)
如果说(4)式是EM的最核心,那(5)式可以说是i-vector推导中的最重要,把(5)代入到(4)中,并展开如下:
Q(T|T^{(t)}) = \sum_{s=1}^SE(\widehat{w}^{(t)}(s)^T T^{T}\Sigma^{-1}F(s)) \\ - \frac{1}{2}\sum^{S}_{s=1}E(\widehat{w}^{(t)}(s)^T T^{T}\Sigma^{-1}N(s)T\widehat{w}^{(t)}(s)^T)
上式(6)中关键的部分有两个,分别是 w(s) 的后验密度函数的均值与协方差:
均值 E(\widehat{w}^{(t)}(s)^T) = \sigma^{{t}}(s)^{-1}T^T\Sigma^{-1}F(s) (7)
协方差 E(\widehat{w}^{(t)}(s)^T\cdot\widehat{w}^{(t)}(s)) = \sigma^{{t}}(s)^{-1} + E(\widehat{w}^{(t)}(s)^T)\cdot E(\widehat{w}^{(t)}(s)^T)^T (8)
其中, \sigma^{{t}}(s) = I + T^T \Sigma^{-1}N(s)T (9)
截至到现在,E步就完成了,简化得到(6)式。
对于M步,对(6)式求极大:
T^{t+1} = argmax Q(T|T^{(t)}) (10)
对 T^{(t)} 求偏导,并求极值点:
\sum_{s=1}^S\Sigma^{-1}F(s)E(\widehat{w}^{(t)}(s)^T) -\\ \frac{1}{2}\sum^S_{s=1}\Sigma^{-1}N(s) \cdot 2T^{t+1} \cdot E(\widehat{w}^{(t)}(s)^T \cdot \widehat{w}^{(t)}(s)) = 0
化简,把第二项挪到等号右边;除了 T^{t+1} 这项外,把其它一堆东西除到等号左边,就可以求到 t+1 次迭代的T矩阵:
T^{(t+1)} = \frac{\sum_{s=1}^S \Sigma^{-1}F(s)E(\widehat{w}^{(t)}(s)^T)}{\sum_{s=1}^S \Sigma^{-1}N(s)E(\widehat{w}^{(t)}(s)^T \cdot \widehat{w}^{(t)}(s))} (11)
通常会迭代T矩阵5~6次认为收敛,最后把 T 与 m 代入到(1)中,即可用于提取i-vector
先写那么多,有空对着Kaldi源码再逐一印证一波~~
-------------------------------分割线-----------------------------------------------------
根据知友要求,再详细介绍从GMM-UBM,T矩阵,均值超矢量,和i-vector这个流程是怎样来的。现在很多papers虽然都省略了介绍ivector提取的具体介绍,甚至连M=m+Tw这个公式也不放上来(不过我也是这样子了),不过这个算法很经典,也是公认基线系统,过程较复杂的,我在这里尽力梳理(真的尽力了QAQ。。。)。。。
1、先用一部分训练集(包含多个说话人),通过EM期望最大化算法,训练UBM通用背景模型;通常我们会先训练一个协方差对角矩阵,再训练全矩阵,理由如下:
1、M阶高斯的稠密全矩阵UBM效果等同于一个更大高斯分量的对角矩阵;
2、对角UBM较为稀疏,计算量低效率快;
3、对角UBM性能上有优势;
UBM特点:一个与说话人、信道无关的高斯混合模型;可以作为这个训练集的统一参考坐标空间;在一定程度上,还解决了某些说话人少样本问题;
2、假如初始化UBM时,我设了M=2048个高斯分量components,就会有2048个单高斯分量,每个 i 分量(i=1,2,...,M)包括一个权重、一个均值矢量、一个协方差矩阵:λ = {ci,μi,∑i},其中μi和∑i分别是矢量与矩阵;
假如声学特征是D=39维,则UBM的第 i 个高斯分量的均值矢量将包含了D维;
如果把均值矢量与协方差对角阵展开,则是μi = {μi1,μi2,...,μiD},∑i = diag{σ^(2)i1,σ^(2)i2,...,σ^(2)iD},即均值是一个D x 1维矢量,方差是D x D维对角(全)矩阵:
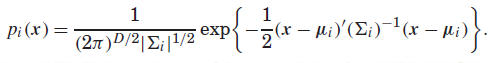

3、训练好了UBM,接下来就是计算充分统计量,我们会用一大部分的训练集去计算;充分统计量包括零阶、一阶(部分存在二阶),这是用于接下来训练总变化子空间矩阵T,公式分别如下:
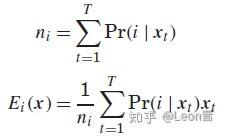

Pr(i | x)是UBM的第 i 个高斯分量的后验概率,如下:
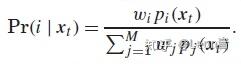

xt 是某句话的第 t 帧(D维),有改进的论文会把一阶统计量公式的 xt 改为 (xt - μi),这是基于UBM通用背景的均值矢量,实现去中心化,使 xt 更突出它的说话人变化性,如:
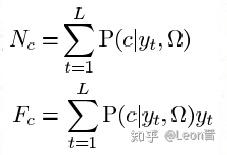

可以把上图的yt改为如下:
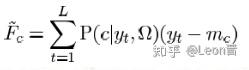

4、根据充分统计量,我们会先将M个高斯分量的均值矢量(每个矢量有D维),串接在一起形成一个高斯均值超矢量,即M x D维,构成F(x),F(x)是MD维矢量;同时利用零阶统计量构造N,N是MD x MD维对角矩阵,以后验概率作为主对角线元素拼接而成;然后,先初始化T矩阵,构造一个[MD, V]维矩阵,V要远小于MD,V<<MD,这个V就是 i-vector 维度;公式如下:
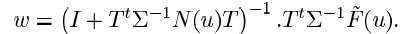
接着,固定T矩阵,根据最大似然准则MLE,估算隐变量 w 的零阶和一阶统计量;再把新的零阶和一阶统计量放回去上面的式子,继续估算w……即使用无监督EM算法去迭代收敛,反复迭代5-6次,即可认为T矩阵收敛。
T矩阵特点:总变化的截荷空间,用于表征总体变化子空间,可以认为包含了说话人信息、信道信息和噪声信息;是一个映射矩阵,类似于权重矩阵;能把高维统计量(超矢量)映射到低维说话人表征(i-vector);起到降维作用;
5、当UBM和T训练好,我们会将待提取i-vector的语音,提取高斯均值超矢量;基于UBM模型,用最大后验概率MAP去自适应当前句子的GMM模型,方法如下:
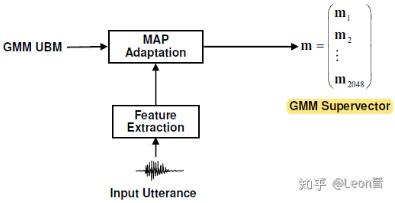

训练当中,可以只对均值进行更新,因为大量实验证明过只更新均值是性能最好的;然后生成M个分量的GMM,以每个高斯分量的均值矢量(每个矢量有D维)作为串接单元,形成MD维的高斯均值超矢量M
6、根据联合因子分析(简化):
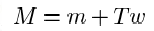
M是第5步的待提取iv的语音的高斯均值超矢量,m是UBM的高斯均值超矢量,T是总变化子空间矩阵,w是i-vector;
维度对应的是 : MD = MD + [MD , V]*V 如果MFCCs设为13维,一二阶差分后成39维,UBM是2048分量,那均值超矢量就是79,872维,V设600即i-vector维度。
参考文献:
【1】Speaker Verification Using Adapted Gaussian Mixture Models
【2】Front-End Factor Analysis for Speaker Verification
【3】SVM BASED SPEAKER VERIFICATION USING A GMM SUPERVECTOR KERNEL AND NAP VARIABILITY COMPENSATION
-------------------------------分割线-----------------------------------------------------
下面是给题目,上面是给科普(伪),QAQ错了记得戳我来改。。。
-------------------------------------------------------再分割----------------------------
训练时有了GMM-UBM,有了T矩阵,测试时就对enrollment和test的MFCC提取高斯超矢量M;然后根据M = m + Tw,得到w,也就是属于enrollment和test的i-vector;接下来就可以做分类了。
得到i-vector,那接下来就用PLDA或者cos作为后端分类器就好了,这个在kaldi的SRE10里有脚本。
如果想要在提取i-vector过程中使用到DNN,那就是借助语音识别的办法,训练DNN模型;然后以DNN的输出节点数作为UBM的高斯数。这个在SRE10-v2里有,不过这整套工程跑起来挺费时。
如果把DNN作为后端分类,也不是不行,就是把整个流程搞得太长了:得到i-vector之后,每次直接把单句话的iv输入进去,输入节点数等于iv维度;集内有多少个SPK,输出节点就有多少维,标签就有多少维;每个SPK的标签都保持one-hot;训练阶段用softmax或者cross entroy;这样就可以完成集内的识别。当然这方法有几个弊端,一是集内二是基于ivector。
如果要做识别,当然还有更暴力的方法,脱掉UBM T矩阵 ivector那一套,如果数据量够多的话,直接用MFCC输入DNN作识别就OK了,参考d-vector方法;不过dvector办法还是有弊端。同样,做二分类确认,也可以直接用DNN解决,只是还有些trick。

对@yichi 的回答稍微补充一点, 对于 1:N 识别的话,最简单的就是对注册集的每一个人的ivector特征取平均,直接作为这个人的model, 然后测试的时候直接计算cos距离就好了,取top1作为识别结果(亲测比gmm-ubm效果要好一点,可以直接yichi提到的sre10/v1中的脚本提)。 同理的可以lda之后再这么做。 如果数据足够多的话,可以用ivector特征再用简单的dnn模型训或者svm,random forest, 当然,一般注册集每个人就几句话,所以一般可以不考虑这种做法, 还有就是如果新注册一个说话人,难道你要重新训一遍模型?