计算机专业 CPU 应该用 AMD 还是 Intel?

闲着无事,用Python写了一个玩具测试,很简单的测试,就是用最原始的for循环,计算100000000阶的随机浮点矢量的点乘,不要问我为什么不用numpy之类的,就是故意这样写来测试for循环的执行速度的。
测试的CPU分别是Xeon Silver 6140(关闭睿频,只有2.3G主频),以及AMD 3700X(单核3.6G),操作系统都是CentOS 7。python解释器版本都是3.6.8。不要问我为什么拿服务器U来比,Python一个单线程负载,6140不过就是一个2.3G的Skylake而已,随便一个桌面级酷睿CPU单核都爆打之。
测试代码如下
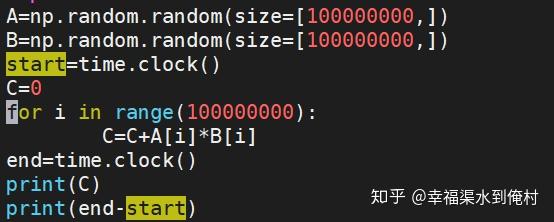

3700X测试结果


用时51.7s完成计算
有负载的核心频率如下,3700X是我的台式机,有图形界面可以看哪个核心在干活,我没有关闭睿频,但是Cent OS 7似乎对AMD的CPU兼容不完美,反正我没见到CPU工作在超过3.6G的频率。相当于没有睿频。


Xeon 6140测试结果


用时49.1秒完成计算。
这是一台机架式服务器,机器已经关闭睿频,核心频率如下


是的你没看错,2.3G的Xeon 6140非常愉快的击败了3.6G的3700X
为什么呢?其实机架式服务器上的python解释器是intel parallel studio XE 2019 update4自带的intel distribution for python,台式机上的python是官方普通的python解释器,那也没办法,AMD没有distribution for python。反正这就是一个生态上的问题。没考证过intel的东西对AMD有没有加成,不过可以认为intel的解释器在intel的CPU上,拥有更快的python for循环速度,意味着如果你以后要用Python的话,玩数据分析,机器学习之类的东西,intel肯定优于AMD。
说到3700X在CentOS 7下没有睿频的问题,表示Ubuntu 18.04更惨,我安装后CPU不管高低负载都维持在2.2G....真是令人惊叹。可能要在Linux下工作的同学注意一下。
-分割
评论区杠的看清楚了,要正正经经的测性能,我早就跑SPEC CPU 2017了,犯的着在这里让各位嘲笑我的代码能力?我根本不是在测这两个CPU的性能,只是在表达一个问题,intel有自己的Python解释器,AMD有么?没有。这就是一个生态的问题,intel有MKL数学库,有Python解释器,有完整的编译工具链,有openVINO,DAAL,也有专为自己CPU优化的openCV。AMD有么?没有。intel用自己的解释器实现高效快速的for循环,这个解释器你敢在AMD上用吗?intel的东西可未必在AMD处理器上调试过。出bug怎么办?杠精想秀自己的优越感还是趁早退散吧。一个np.dot就能解决的事,就不要指点江山了,开jit什么的,对了np.dot这个函数搞不好还是调的MKL,评论区大神们有本事写个比MKL更快的库让我观摩学习一下?
____2020/06/23更新
既然很多人觉得我的观点很多糟糕,那我就只能上SPEC CPU 2017了。与anandtech不同的是,我的这个SPEC CPU 2017的测试对intel的CPU使用了intel 编译2019 update3,对AMD的CPU使用最新的AOCC2.1,基于Clang9.0。使用LLVM后端。
下面是结果文件的截图,请忽视供应商信息,都是瞎写的
6140:
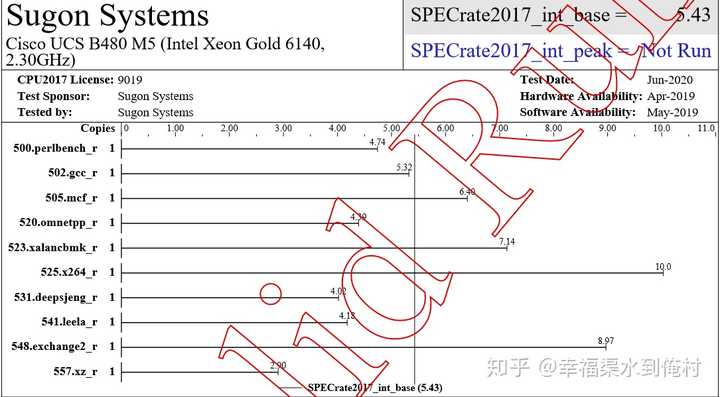

3700X:



为了确保不受睿频影响,所有处理器跑在它们的基础频率上。即,3700X是3.6G,6140是2.3G。
编译器:AOCC2.1 for 3700X:编译选项: COPTIMIZE = -O3 -flto -ffast-math -march=znver2 -fstruct-layout=3 \
-mllvm -unroll-threshold=50 -fremap-arrays \
-mllvm -function-specialize -mllvm -enable-gvn-hoist \
-mllvm -reduce-array-computations=3 -mllvm -global-vectoriz e-slp \
-mllvm -inline-threshold=1000 -flv-function-specialization
CXXOPTIMIZE = -O3 -flto -ffast-math -march=znver2 \
-mllvm -loop-unswitch-threshold=200000 \
-mllvm -unroll-threshold=100 -flv-function-specialization \
-mllvm -enable-partial-unswitch
FOPTIMIZE = -O3 -flto -march=znver2 -funroll-loops -Mrecursive \
icc2019 for Xeon 6140:编译选项:


备注一下,AMD这边的Malloc库采用jemalloc 5.2.0,intel采用编译器自带的qkmalloc。为啥一个截图,一个打字呢,AMD那一串优化选项貌似都不太合法。虽然我是从官网下载config来对着改,但是不知道为什么控制脚本就是觉得不合法哈哈
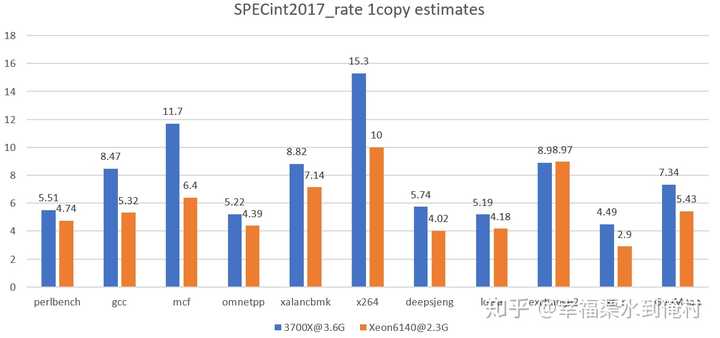
最后综合结果是3700X 7.34分 IPC 2.038/G,Xeon 6140 5.43分,IPC 2.36/G。
我看看谁要来质疑SPEC2017的。什么,统一编译器?不存在的。AOCC vs icc不好嘛
由于频率差异很大,实际消费级的CPU可能没有2.3这种频率。但是我们来看看一些与计算机专业密切相关的跑分如gcc,好吧。Xeon 同频完败。8.47 vs 8.32(换算同频),但Perlbench同频就是intel这边完胜,5.51 vs 7.41(换算同频),我们还看到,XML解析和人工智能下棋deepsjeng/leela,intel处理器也是完胜。其他的你们自己看吧