最小二乘法的本质是什么?
81 个回答

最小平方法是十九世纪统计学的主题曲。
从许多方面来看, 它之于统计学就相当于十八世纪的微积分之于数学。
----史蒂芬·史蒂格勒的《The History of Statistics》
1 日用而不知
来看一个生活中的例子。比如说,有五把尺子:


用它们来分别测量一线段的长度,得到的数值分别为(颜色指不同的尺子):
\begin{array}{c|c}\qquad\qquad&\qquad长度\qquad\\\hline\color{red}红& 10.2 \\\hline \color{blue}蓝& 10.3 \\\hline \color{orange}橙&9.8\\\hline \color{Goldenrod}黄&9.9\\\hline \color{green}绿&9.8\\\end{array}\\
之所以出现不同的值可能因为:
- 不同厂家的尺子的生产精度不同
- 尺子材质不同,热胀冷缩不一样
- 测量的时候心情起伏不定
- ......
总之就是有误差,这种情况下,一般取平均值来作为线段的长度:
\overline{x}=\frac{10.2+10.3+9.8+9.9+9.8}{5}=10\\
日常中就是这么使用的。可是作为很事'er的数学爱好者,自然要想下:
- 这样做有道理吗?
- 用调和平均数行不行?
- 用中位数行不行?
- 用几何平均数行不行?
2 最小二乘法
换一种思路来思考刚才的问题。
首先,把测试得到的值画在笛卡尔坐标系中,分别记作y_i :


其次,把要猜测的线段长度的真实值用平行于横轴的直线来表示(因为是猜测的,所以用虚线来画),记作y :


每个点都向y 做垂线,垂线的长度就是|y-y_i| ,也可以理解为测量值和真实值之间的误差:


因为误差是长度,还要取绝对值,计算起来麻烦,就干脆用平方来代表误差:
|y-y_i|\to (y-y_i)^2\\
误差的平方和就是(\epsilon 代表误差):
S_{\epsilon^2}=\sum (y-y_i)^2\\
因为y 是猜测的,所以可以不断变换:


自然,误差的平方和S_{\epsilon^2} 在不断变化的。


法国数学家,阿德里安-马里·勒让德(1752-1833,这个头像有点抽象)提出让总的误差的平方最小的y 就是真值,这是基于,如果误差是随机的,应该围绕真值上下波动(关于这点可以看下“如何理解无偏估计?”)。
勒让德的想法变成代数式就是:
S_{\epsilon^2}=\sum (y-y_i)^2最小\implies 真值y\\
这个猜想也蛮符合直觉的,来算一下。
这是一个二次函数,对其求导,导数为0的时候取得最小值:
\begin{aligned} \frac{d}{dy}S_{\epsilon^2}&=\frac{d}{dy}\sum (y-y_i)^2=2\sum (y-y_i)\\ \quad\\&=2((y-y_1)+(y-y_2)+(y-y_3)+(y-y_4)+(y-y_5))=0 \quad\\\end{aligned}\\
进而:
5y=y_1+y_2+y_3+y_4+y_5\implies y=\frac{y_1+y_2+y_3+y_4+y_5}{5}\\
正好是算术平均数。
原来算术平均数可以让误差最小啊,这下看来选用它显得讲道理了。
以下这种方法:
S_{\epsilon^2}=\sum (y-y_i)^2最小\implies 真值y\\
就是最小二乘法,所谓“二乘”就是平方的意思,台湾直接翻译为最小平方法。
3 推广
算术平均数只是最小二乘法的特例,适用范围比较狭窄。而最小二乘法用途就广泛。
比如温度与冰淇淋的销量:
\begin{array}{c|c} \qquad\qquad&\qquad销量\qquad\\\hline\color{red}{25^\circ}& 110 \\\hline\color{blue}{27^\circ}& 115 \\\hline\color{orange}{31^\circ}&155\\\hline \color{Goldenrod}{33^\circ}&160\\\hline\color{green}{35^\circ}&180\\\end{array}\\
看上去像是某种线性关系:
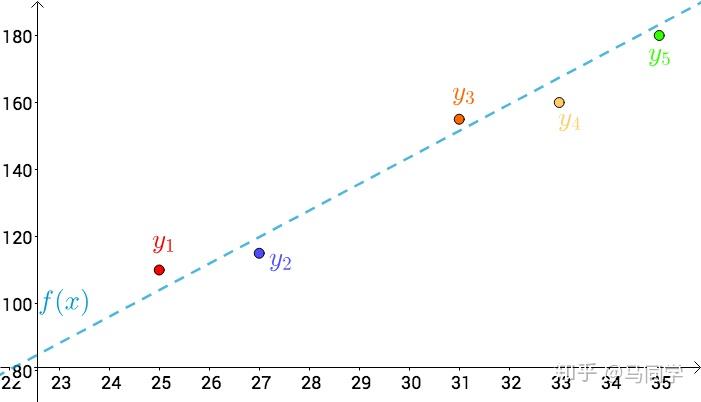
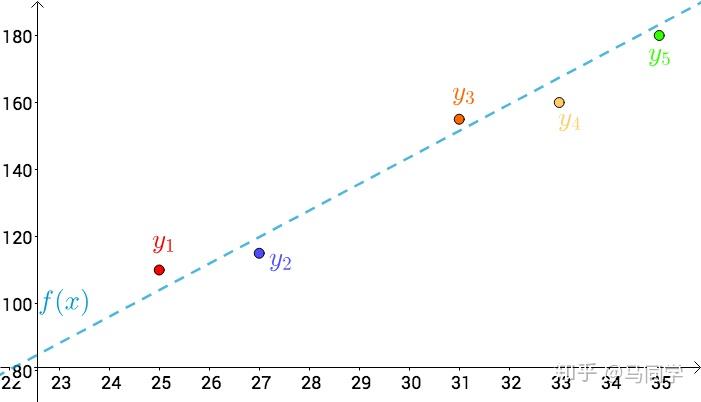
可以假设这种线性关系为:
f(x)=ax+b\\
通过最小二乘法的思想:


上图的i,x,y 分别为:
\begin{array}{c|c|c}\qquad i\qquad&\qquad x\qquad&\qquad y\qquad\\\hline 1&25& 110 \\\hline2&27& 115 \\\hline3&31&155\\\hline 4&33&160\\\hline 5&35&180\\\end{array}\\
总误差的平方为:
S_{\epsilon^2}=\sum (f(x_i)-y_i)^2=\sum (ax_i+b-y_i)^2\\
不同的a,b 会导致不同的S_{\epsilon^2} ,根据多元微积分的知识,当:
\begin{cases} \frac{\partial}{\partial a}S_{\epsilon^2}=2\sum (ax_i+b-y_i)x_i=0\\\quad\\\frac{\partial}{\partial b}S_{\epsilon^2}=2\sum (ax_i+b-y_i)=0\end{cases}\\
这个时候S_{\epsilon^2} 取最小值。
对于a,b 而言,上述方程组为线性方程组,用之前的数据解出来:
\begin{cases} a\approx 7.2\\\quad\\ b\approx -73\end{cases}\\
也就是这根直线:


其实,还可以假设:
f(x)=ax^2+bx+c\\
在这个假设下,可以根据最小二乘法,算出a,b,c ,得到下面这根红色的二次曲线:


同一组数据,选择不同的f(x) ,通过最小二乘法可以得到不一样的拟合曲线(出处):


不同的数据,更可以选择不同的f(x) ,通过最小二乘法可以得到不一样的拟合曲线:


f(x) 也不能选择任意的函数,还是有一些讲究的,这里就不介绍了。
4 最小二乘法与正态分布
我们对勒让德的猜测,即最小二乘法,仍然抱有怀疑,万一这个猜测是错误的怎么办?


数学王子高斯(1777-1855)也像我们一样心存怀疑。
高斯换了一个思考框架,通过概率统计那一套来思考。
让我们回到最初测量线段长度的问题。高斯想,通过测量得到了这些值:
\begin{array}{c|c}\qquad\qquad&\qquad长度\qquad\\\hline\color{red}红& 10.2 \\\hline\color{blue}蓝& 10.3 \\\hline\color{orange}橙&9.8\\\hline\color{Goldenrod}黄&9.9\\\hline \color{green}绿&9.8\\\end{array}\\
每次的测量值x_i 都和线段长度的真值x 之间存在一个误差:
\epsilon_i=x-x_i\\
这些误差最终会形成一个概率分布,只是现在不知道误差的概率分布是什么。假设概率密度函数为:
p(\epsilon)\\
再假设一个联合概率,这样方便把所有的测量数据利用起来:
\begin{aligned} L(x) &=p(\epsilon_1)p(\epsilon_2)\cdots p(\epsilon_5)\\\quad\\&=p(x-x_i)p(x-x_2)\cdots p(x-x_5)\end{aligned}\\
把x 作为变量的时候,上面就是似然函数了(关于似然函数以及马上要讲到的极大似然估计,可以参考“如何理解极大似然估计法?”)。
L(x) 的图像可能是这样的(随便画的):


根据极大似然估计的思想,联合概率最大的最应该出现(既然都出现了,而我又不是“天选之子”,那么自然不会是发生了小概率事件),也就是应该取到下面这点:


当下面这个式子成立时,取得最大值:
\frac{d}{dx}L(x)=0\\
然后高斯想,最小二乘法给出的答案是:
x=\overline{x}=\frac{x_1+x_2+x_3+x_4+x_5}{5}\\
如果最小二乘法是对的,那么x=\overline{x} 时应该取得最大值,即:
\frac{d}{dx}L(x)|_{x=\overline{x}}=0\\
好,现在可以来解这个微分方程了。最终得到:
p(\epsilon)={1 \over \sigma\sqrt{2\pi} }\,e^{- {{\epsilon^2 \over 2\sigma^2}}}\\
这是什么?这就是正态分布啊。
并且这还是一个充要条件:
x=\overline{x}\iff p(\epsilon)={1 \over \sigma\sqrt{2\pi} }\,e^{- {{\epsilon^2 \over 2\sigma^2}}}\\
也就是说,如果误差的分布是正态分布,那么最小二乘法得到的就是最有可能的值。
那么误差的分布是正态分布吗?
如果误差是由于随机的、无数的、独立的、多个因素造成的,比如之前提到的:
- 不同厂家的尺子的生产精度不同
- 尺子材质不同,热胀冷缩不一样
- 测量的时候心情起伏不定
- ......
那么根据中心极限定理(参考“为什么正态分布如此常见?”),误差的分布就应该是正态分布。
虽然勒让德提出了最小二乘法(高斯说他最早提出最小二乘法,只是没有发表),但是高斯的努力,才真正奠定了最小二乘法的重要地位。
文章最新版本在(有可能会有后续更新):如何理解最小二乘法?
更多内容查看马同学图解数学系列教程

万字长回答,从基础的最小二乘开始,剖析本质再到进阶方法,看完需要一些耐心。
最小二乘的概念可以追溯到高斯和勒让德在19世纪早期的工作,最小二乘的使用广泛渗透在现代统计和数据建模领域中,回归和参数估计的关键技术成为科学和工程计算中的基本工具。
1 最小二乘与法线方程
1.1 不一致的方程组
如果一个方程组无解,那么这个方程组被称为不一致。例如下面的方程组:
x_1+x_2=2\\ x_1-x_2=1\\ x_1+x_2=3
根据线性代数的知识,m个方程n个未知量 m>n 时通常无解,但是虽然不能求出 Ax=b 的解,那何不退而求其次,去寻找与解近似的向量 x 。
那么如何定义与解相似,一般使用欧氏距离来进行度量,即两点间的距离,这其实很好理解,越相似,欧氏距离越近,这样求出的 x 被称为最小二乘解。
将我们开始举的例子写成矩阵形式:
\\ \begin{bmatrix} 1&1\\ 1&-1\\ 1&1 \end{bmatrix}\begin{bmatrix} x_1\\ x_2 \end{bmatrix} =\begin{bmatrix} 2\\ 1\\ 3 \end{bmatrix}
写成等价方程为:
\\ x_1\begin{bmatrix} 1\\ 1\\ 1 \end{bmatrix} + x_2\begin{bmatrix} 1\\ -1\\ 1 \end{bmatrix} =\begin{bmatrix} 2\\ 1\\ 3 \end{bmatrix}
对于任意 m\times n 方程组 Ax=b 都可以看做向量方程:
\\ x_1v_1+x_2v_2+\dots+x_nv_n=b
其实也就是把 b 看做 A 的列向量的线性组合,对应的系数即为 x_i ,对于举的例子来说,就是把 b 表示为另外两个三维向量的线性组合,由于 R^3 中两个三维向量的组合生成一个平面,方程仅当b在这个平面上才有解,推广至m个方程n个未知量 m>n 时也是相同的情况。
下图表明了如果解不存在时的情况,如果对于例子没有点 x_1,x_2 满足条件,但是在所有候选点构成的平面 Ax 中有与 b 最接近的点,即有一个向量 A\bar x 满足 b-A\bar x 与平面 {\{Ax|x\in R^n}\} 垂直,那么表达成数学语言就是向量之间正交,即:
\\(Ax)^T(b-A\bar x)=0
运算一下,就有:
\\x^TA^T(b-A\bar x)=0
也就是n维向量 A^T(b-A\bar x) 和 R^n 中包括自己在内的其他n维向量垂直,那么满足条件的只有0向量,即:
A^T(b-A\bar x)=0\\ A^TA\bar x=A^Tb
A^TA\bar x=A^Tb 就被称为法线方程,它的解 \bar x 也就是方程组 Ax=b 的最小二乘解。


那么用法线方程就可以得到举的例子的最小二乘解为 \bar x=[7/4\ 3/4] ,代入原方程就为:
\\ \begin{bmatrix} 1&1\\ 1&-1\\ 1&1 \end{bmatrix}\begin{bmatrix} 7/4\\ 3/4 \end{bmatrix} =\begin{bmatrix} 2.5\\ 1\\ 2.5 \end{bmatrix} \not= \begin{bmatrix} 2\\ 1\\ 3 \end{bmatrix}
计算余项:
\\r=b-A\bar x=[-0.5\quad 0\quad 0.5]^T
很显然如果余项是0,就意味着精确求解了原系统,如果不是,那么余项的欧式长度就是误差,度量了 \bar x 与真实解的距离。
那么对于余项大小的度量就有三种方法:
- (1)向量的欧式长度(二范数): ||r||_2=\sqrt{r_1^2+\cdots+r_m^2}
- (2)向量的平方误差: SE=r_1^2+\cdots+r_m^2
- (3)平均平方根误差(误差平方均值的根): RMSE=\sqrt{SE/m}
这三种表达紧密相关,即:
\\ RMSE=\sqrt{SE/m}=||r||_2/\sqrt{m}
2. 数据的拟合模型
令(t_1,y_1),\cdots,(t_m,y_m)是平面上的一组点,给定一类确定的模型,例如线性模型 y=c_1+c_2t ,在2范数意义上最优拟合给定的数据点,最小二乘思想的核心在于找出某种模型参数使得在数据点上通过平方误差度拟合的余项最小。如下图:

很显然,最小二乘数据拟合的步骤为:
- 给定一组数据点(t_1,y_1),\cdots,(t_m,y_m)。
- (1)选择模型,确定用于拟合数据的参数模型,例如 y=c_1+c_2t
- (2)利用模型拟合数据,将数据点代入模型,得到系统 Ax=b
- (3)求解法线方程 A^TA\bar x=A^Tb 的解
在MATLAB中提供了polyfit和polyval命令,不仅可以插值数据,而且可以使用多项式模型拟合数据,对于 n 个数据点,polyfit使用 n-1 阶多项式,返回阶数为 n-1 的多项式的系数,如果输人阶数小于 n-1 ,polyfit将找出该阶数对应的最小二乘估计,例如下面这段代码:
x0=[-1 0 1 2];
y0=[1 0 0 -2];
%c=polyfit(x0,y0,1);%一阶拟合
c=polyfit(x0,y0,2);%二阶拟合
x=-1:0.01:2;
y=polyval(c,x);
y1=polyval(c,x0);
err=y1-y0;
err1=y0-p;
p=mean(y0);
n=norm(err,2);
n1=norm(err1,2);
SE=n^2;
ST=n1^2;
[~,m]=size(y0);
RMSE=n/sqrt(m);
R_square=1-SE/ST;
plot(x0,y0,'o',x,y)上述代码的结果为:


3. 模型概述
3.1 周期数据
对于周期数据,常常选用 y=c_1+c_2cos2\pi t+c_3sin2\pi t+... 来进行拟合,下面的例子代码给出了利用这个函数来拟合温度数据的例子。
t=[0:1/8:7/8]';
y0=[-2.2 -2.8 -6.1 -3.9 0 1.1 -0.6 -1.1]';
[n,~]=size(t);
A=[ones(n,1),cos(2*pi*t),sin(2*pi*t),cos(4*pi*t)];
a=A(:,1:3)'*A(:,1:3);
b=A(:,1:3)'*y0;
c=inv(a)*b;
a1=A(:,1:4)'*A(:,1:4);
b1=A(:,1:4)'*y0;
c1=inv(a1)*b1;
%[m,~]=size(c);
x=[0:0.01:1];
y=c(1)+c(2)*cos(2*pi*x)+c(3)*sin(2*pi*x);
y1=c1(1)+c1(2)*cos(2*pi*x)+c1(3)*sin(2*pi*x)+c1(4)*cos(4*pi*x);
plot(t,y0,'o',x,y,'r',x,y1,'g','linewidth',1);
hold on
plot(t,y0,'b','Linewidth',1)
err=(c(1)+c(2)*cos(2*pi*t)+c(3)*sin(2*pi*t))-y0;
err1=(c1(1)+c1(2)*cos(2*pi*t)+c1(3)*sin(2*pi*t)+c1(4)*cos(4*pi*t))-y0;
n=norm(err,2);
n1=norm(err1,2);
[m,~]=size(y0);
RMSE=n/sqrt(m);
RMSE1=n1/sqrt(m);
text(0.7,-5,['三阶RMSE=' num2str(RMSE)]);
text(0.7,-5.5,['四阶RMSE1=' num2str(RMSE1)]);
legend('数据点','三阶拟合','四阶拟合','平滑连接')
set(gca, 'LineWidth',1); %%设置坐标轴线宽
xlabel('x'); %%设置横坐标
ylabel('y'); %%设置纵坐标
title('周期方法拟合')

3.2 数据线性化
即采用指数模型 y=c_1e^{c_2 t} ,通过对两边取对数得到 lny=lnc_1+c_2t=k+c_2t 来对数据进行拟合。
同样还有幂法则模型 y=c_1t^{c_2 } 两边取对数 lny=lnc_1+c_2lnt=k+c_2lnt 对数据进行拟合。
这里的例子和代码就不举了,很简单,可以自己尝试几个例子。
最小二乘拟合的本质其实就在法线方程的求解,但是还有这并不是万能的,比如拟合范德蒙德行列式等,这也催生了QR分解,GMRES方法等一系列方法。
感谢评论区@Maple的批评指正,下面给出推导:
4. 最小二乘法对误差的估计为什么是平方
评论区提出了问题,为什么最小二乘法对误差的估计是平方,不是四次方,六次方,这要从另一个角度来推导:
原因在于取二次方的时候,对参数的估计是当前样本下的最大似然估计,从最简单的一维情况给出证明,如果对n维感兴趣可以去看看卡尔曼滤波的基础推导。
记样本点为 t(i),y(i) ,对样本的预测值为 \hat y(i)|_\theta ,表示预测依赖于参数 \theta 的选择:
那么对于真实值和预测值很明显就有:
\\y=\hat y|_\theta+\varepsilon
\varepsilon 是一个误差函数,代表着真值与预测值之间的误差,那么这个误差满足什么条件?
概率论中学过大数定律和中心极限定理,通常认为其服从正态分布 \varepsilon\sim N(0,\sigma^2) ,根据正态分布的性质,就有 y-\hat y|_\theta\sim N(0,\sigma^2) , y\sim N(\hat y|_\theta,\sigma^2) ,这里的运算就是均值和方差的性质,很简单,因为预测值 \hat y|_\theta 的均值就是自己,方差0,加和即可。
那么接下来就是构建似然函数,很熟悉的概率论过程了:
\\ L(\theta|y)=P(y=\hat y|\theta)=\prod_{i=1}^{n}\frac{1}{\sqrt{2\pi}\sigma}e^{-\frac{(y(i)-\hat y(i)|_\theta)^2}{2\sigma}}
取对数,得到:
\\l(\theta|y)=ln L(\theta|y)=nln\frac{1}{\sqrt{2\pi}\sigma}+\sum_{i=1}^{n}{-\frac{(y(i)-\hat y(i)|_\theta)^2}{2\sigma}}
都不用求导,很明显可以看出当 \sum_{i=1}^{n}{(y(i)-\hat y(i)|_\theta)^2} 最小时, l(\theta|y) 达到最大值,也就意味着当误差函数定为平方时,参数 \theta 是样本的极大似然估计,而不是选用别的误差函数。
那么法线方程不好用怎么办?使用QR分解
5. QR分解
5.1 格拉姆-施密特正交与最小二乘
格拉姆-施密特方法是将一组向量正交化,给定一组输入的m维向量, 目的在于找出正交坐标系统,得到由这些向量张成的空间,精确点说就是给定n个线性无关的输入向量,计算n个彼此垂直的单位向量,张成和输入向量m相同的子空间,单位长度由二范数进行定义。
令 A_1,\dots,A_n 是R^m 中线性无关的向量,就有 n\leq m , 首先选择A_1除以它的长度得到单位向量 y_1=A_1,q_1=\frac{y_1}{||y_1||_2} ,接着寻找第二个单位向量,在 A_2 上减去 A_2 在 q_1 上的投影,并进行规范化,就有 y_2=A_2-q_1(q_1^TA_2),q_2=\frac{y_2}{||y_2||_2} ,因为 q_1^Ty_2=0 ,那么 q_1,q_2 两两正交。
以此类推,在第 j 步中定义:\\ \begin{aligned} \\y_j&=A_j-q_1(q_1^TA_j)-q_2(q_2^TA_j)-\dots-q_{j-1}(q_{j-1}^TA_j) \\q_j&=\frac{y_j}{||y_j||_2} \end{aligned}
这样,原来向量 A_1,\dots,A_n 所张成的空间转化成了由正交单位向量 q_1,\dots,q_n 描述的空间,这是很有意义的工作,因为这个空间中的信息就可以由正交向量来描述了,正交向量就成为了这个空间的坐标系。
格拉姆-施密特方法可以通过引入新的符号写为矩阵形式,即定义 :
\\r_{jj}=||y_j||_2,r_{ij}=q_i^TA_j
这样就有 A_j=r_{1j}q_1+\dots+r_{j-1,j}q_{j-1}+r_{jj}q_j ,将结果表示为矩阵:
\\ \left( \begin{array}{c|c|c} A_1&\cdots&A_n\\ \end{array} \right)= \left( \begin{array}{c|c|c} q_1&\cdots&q_n\\ \end{array} \right) \left[ \begin{array}{cccc} r_{11} & r_{12} & \cdots & r_{1n} \\ 0 & r_{22} & \cdots & r_{2n} \\ \vdots & \vdots& \ddots & \vdots \\ 0& 0 & \cdots &r_{nn} \\ \end{array} \right]
即 A=QR ,其中A是包含列向量 A_j 的矩阵,上面就被称为消减QR分解,由于假设 A_j 线性无关,那么主对角线系数 r_{jj} 非0。
这样,经典格拉姆-施密特正交算法为:
\\\begin{align} &令A_j(j=1,\dots,n)为线性无关向量 \\&for\ j=1,\cdots,n \\ &\quad y=A_j \\ &\quad for\ i=1,2,\cdots,j-1 \\ &\quad \quad r_{ij}=q_i^TA_j \\ &\quad \quad y=y-r_{ij}q_i \\& \quad end \\& \quad r_{ij}=||y||_2 \\& \quad q_j=y/r_{jj} \\&end \end{align}
经典的格拉姆-施密特正交可以得到n个线性无关的输入向量张成的输入向量m相同的子空间,那么要张成和输入向量m一样的空间怎么办?这就需要实现“完全”的QR分解,通过在 A_j 中加入 m-n 个额外向量,这样由基 q_1,\dots,q_m 构成的 R^m 可以表达为由输入向量 A_1,\dots,A_n 的完全QR分解,注意A是m x n矩阵,Q是m x m方阵,上三角阵R是m x n矩阵和A规模相同。
\\ \left( \begin{array}{c|c|c} A_1&\cdots&A_n\\ \end{array} \right)= \left( \begin{array}{c|c|c} q_1&\cdots&q_m\\ \end{array} \right) \left[ \begin{array}{cccc} r_{11} & r_{12} & \cdots & r_{1n} \\ 0 & r_{22} & \cdots & r_{2n} \\ \vdots & \vdots& \ddots & \vdots \\ 0& 0 & \cdots &r_{nn} \\ 0 & 0 & \cdots & 0 \\ 0 & 0 & \cdots & 0 \\ \vdots & \vdots& \ddots & \vdots \\ 0& 0 & \cdots &0 \end{array} \right]
对于QR分解的矩阵Q,有一些特别的定义:
(1)当 Q^T=Q^{-1} 时,方阵Q正交。
(2)如果Q是 m \times m 正交矩阵,x是m维向量,则 ||Qx||_2=||x||_2 。
MATLAB提供了qr命令来对m x n矩阵的QR分解,但是MATLAB的qr命令并没有使用格拉姆-施密特正交,而是更加稳定有效的方法,下面再说,命令如下:
[Q,R]=qr(A,0)%消减QR分解
[Q,R]=qr(A)%完全QR分解QR分解主要有三个用途:
- (1)首先它可以用于求解n个方程n个未知变量的系统 Ax=b ,如果A非奇异,那么就可以将A分解为QR,回代则求解出x,但是QR分解线性方程组比LU分解方法的计算代价大三倍还多,用的不多。
- (2)用于求解最小二乘问题
- (3)用于特征值计算,这个之后的帖子再写
通过QR分解实现最小二乘的算法为:\\\begin{align} \\&给定m\times n不一致系统 \\&\quad \quad Ax=b \\&找出完全QR分解A=QR,令 \\ &\quad \quad \hat R=R的上n\times n子矩阵 \\ &\quad \quad \hat d=d=Q^Tb的上面的n个元素 \\&求解\hat R\bar x=\hat d得到最小二乘解\bar x \end {align}
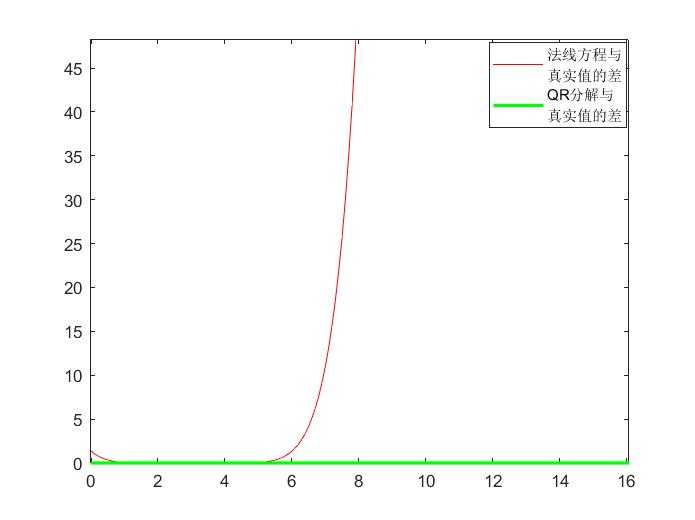
QR分解可以通过不计算 A^TA 来避开最小二乘法线方程方法带来的病态问题,比如用拟合区间 [2,4] 和七阶多项式 1+x^2+x^2+x^3+x^4+x^5+x^6+x^7 的对应值,程序代码如下:(可以看到系数矩阵的条件数达到了惊人的 6.46\times 10^{18} 次方,用法线方程拟合的效果非常不好,但是使用QR分解可以很好的拟合)
x=(2+(0:10)/5)';
y=1+x+x.^2+x.^3+x.^4+x.^5+x.^6+x.^7;
A=[x.^0 x x.^2 x.^3 x.^4 x.^5 x.^6 x.^7];
c1=(A'*A)\(A'*y);
x1=0:0.1:100;
y1=c1(1)+c1(2)*x1+c1(3)*x1.^2+c1(4)*x1.^3+c1(5)*x1.^4+c1(6)*x1.^5+c1(7)*x1.^6+c1(8)*x1.^7;
y2=1+x1+x1.^2+x1.^3+x1.^4+x1.^5+x1.^6+x1.^7;
err=abs(y2-y1);
cond(A'*A);
[Q,R]=qr(A);
b=Q'*y;
c2=R(1:8,1:8)\b(1:8);
y3=c2(1)+c2(2)*x1+c2(3)*x1.^2+c2(4)*x1.^3+c2(5)*x1.^4+c2(6)*x1.^5+c2(7)*x1.^6+c2(8)*x1.^7;
err1=abs(y2-y3);
plot(x1,err,'r'),axis([0 10 0 30]);
hold on
plot(x1,err1,'g','linewidth',2),axis([0 10 0 30])如果用七阶多项式 c_1+c_2x^2+c_3x^2+c_4x^3+c_5x^4+c_6x^5+c_7x^6+c_8x^7 来进行拟合,正确的解的系数为8个1,但是使用法线方程解出的系数为:
\\\begin{bmatrix} -0.3588& 4.3560& -2.5167& 3.0269& 0.3059& 1.1412& 0.9841& 1.0008 \end{bmatrix}
使用QR分解得到的系数为8个1,绘制预测值与真实值差的绝对值就可以看到具体的情况如下图:

5.2 改进的格拉姆-施密特正交
与经典的格拉姆-施密特正交相比,改进的格拉姆-施密特正交将 A_j 被y在最内层的循环替换掉,这样被投影的将是余项,而不是 A_j ,这种改进的格拉姆-施密特正交将被用在GMRES中。
\\\begin{align} &令A_j(j=1,\dots,n)为线性无关向量 \\&for\ j=1,\cdots,n \\ &\quad y=A_j \\ &\quad for\ i=1,2,\cdots,j-1 \\ &\quad \quad r_{ij}=q_i^Ty \\ &\quad \quad y=y-r_{ij}q_i \\& \quad end \\& \quad r_{ij}=||y||_2 \\& \quad q_j=y/r_{jj} \\&end \end{align}
5.3 豪斯霍尔德反射子
尽管改进的格拉姆-施密特正交是计算矩阵的QR分解的有效方式,但却不是最优的,另一种方法是使用豪斯霍尔德反射,以获得更少的计算量。
豪斯霍尔德反射子是正交矩阵,通过m-1维平面反射m维向量,这也就意味着当每个向量乘上矩阵后,长度保持不变,这样豪斯霍尔德反射就被称为移动向量的完美形式,给定一个向量x,找出一个相同长度的向量w,计算豪斯霍尔德反射得出矩阵H满足Hx=w。
其实原理也十分简单,就是使用中垂线,如下图:

假设x和w是具有相同欧几里得长度的向量, ||x||_2=||w||_2 ,则 w-x 和 w+x 正交,这个从上面的图就很容易看出来了。
令x和w是向量, ||x||_2=||w||_2 ,并定义v=w-x,则 H=I-2vv^T/v^Tv 是对称正交矩阵,并且 Hx=w ,H矩阵就被称为豪斯霍尔德反射子。
那么有了豪斯霍尔德反射子,完成QR分解将变得非常简单,QR分解不就是把对应矩阵的列向量等长搬到x,y,z轴上么,那只需要计算对应矩阵列向量的欧式长度,然后利用豪斯霍尔德反射子把它们搬过去不就行了吗,这样的操作要比前面我们提的格拉姆-施密特正交简单不少,因此豪斯霍尔德反射子是将矩阵进行QR分解的常用方法。
可能上面的描述不是很好理解,举个例子:
对矩阵 A=\begin{bmatrix} 1&-4\\ 2&3\\ 2&2 \end{bmatrix} 利用豪斯霍尔德反射子进行QR分解:
首先将第一列向量 [1,2,2]^T 保持长度不变挪到x轴上去,那么该向量的长度为3,是不是就是意味着挪到 [3,0,0]^T 处,那么这个移动的豪斯霍尔德反射子就用上面的公式来计算:v=w-x=[3,0,0]^T-[1,2,2]^T=[2,-2,-2]^T , H_1=\begin{bmatrix} 1/3&2/3&2/3\\ 2/3&1/3&-2/3\\ 2/3&-2/3&1/3 \end{bmatrix} ,用 H_1 乘A就处理完了矩阵A的所有x轴上的量,即: H_1A=\begin{bmatrix} 3&2\\ 0&-3\\ 0&-4 \end{bmatrix} ,在搬完了第一列之后,注意之后的移动就不能破坏已经搬好的x位置,因此,接下来把 [2,-3,-4]^T 在保证x分量不变的情况下等长的搬到y轴上,也就是将其搬到 [2,5 ,0]^T 处,重复上面的过程,就可以得到豪斯霍尔德反射子 H_2=\begin{bmatrix} 1&0&0\\ 0&-0.6&-0.8\\ 0&-0.8&0.6 \end{bmatrix} ,这样将两个豪斯霍尔德反射子相乘就完成了QR分解,即:
A=H_1H_2R=QR,Q=H_1H_2 。
如果矩阵维度更多,那就继续类推,接下来就是保证x,y分量不变,等长变换z等等,其实豪斯霍尔德算子的几何思想就是空间内长度不变的移动,就像拼图游戏,你拿着一个坐标系,目标在于将坐标轴对上去。
6 广义最小余项(GMRES)方法
在前面的帖子里,介绍过共轭梯度方法,它可以看做是一种迭代方法,用于求解矩阵系统 Ax=b ,其中A是对称方阵,如果A不对称,则不能使用共轭梯度法,但是有几种不同的方法可以用于求解非对称的矩阵A,其中最常见的方法是广义最小余项方法(GMRES),这种方法是求解大规模、稀疏、非对称线性方程组 Ax=b 的有效方法。
6.1 Krylov方法
GMRES方法属于Krylov方法,依赖于精确的Krylov空间计算,该空间是向量 {\{r,Ar,\dots,A^kr}\} 张成的空间,其中 r=b-Ax_0 是初始估计的余项,GMRES的思想就是在特殊矢量空间,即Krylov空间中寻找初始估计 x_0 的改进,Krylov空间由余项r和它的非奇异矩阵A的积所张成,在算法的第k步,通过加入 A^kr 来扩大Krylov空间,重新对基进行正交化,然后通过最小二乘获取改进并加到 x_0 中。
广义最小余项方法的算法为:
\\ \begin{align} &x_0=初始估计\\ &r=b-Ax_0\\ &q_1=r/||r||_2\\ &for\ k=1,2,\dots,m\\ &\quad \quad y=Aq_k\\ &\quad forj=1,2,\dots,k\\ &\quad \quad h_{jk}=q_j^Ty\\ &\quad \quad y=y-h_{jk}q_j\\ &\quad end\\ &\quad \quad h_{k+1,k}=||y||_2(如果 h_{k+1,k}=0,跳过下一行并在底端终止)\\ &\quad \quad q_{k+1}y/h_{k+1,k}\\ &\quad \quad min||Hc_k-[||r||_2,0,0,\dots,0]^T||_2得到c_k\\ &\quad \quad x_k=Q_kc_k+x_0\\ &end \end{align}
迭代的 x_k 就是系统 Ax=b 的近似解。
GMRES的典型用途是用于大规模系数的 n\times n矩阵A,理论上,算法经过n步终止,只要A是非奇异矩阵就可以得到解x,在大多数情况下目标就是仅仅运行k步,k比n小很多,如果k步迭代之后没能得到足够趋近的解,而且 Q_k 变得难以处理,那么很简单的思想就是丢开这个 Q_k 重新进行GMRES方法,使用当前的最优估计x_k 作为新的 x_0 ,这种操作称之为重启GMRES。
6.2 预条件GMRES方法
预条件GMRES方法的思想和共轭梯度法的思想非常相似,也就是利用前面帖子讨论过的预条件子M,对GMRES方法略加改变,就可以得到:
预条件GMRES :
\\\begin{align} &x_0=初始估计\\ &r=M^{-1}(b-Ax_0)\\ &q_1=r/||r||_2\\ &for\ k=1,2,\dots,m\\ &\quad \quad w=M^{-1}Aq_k\\ &\quad forj=1,2,\dots,k\\ &\quad \quad h_{jk}=w^Tq_j\\ &\quad \quad w=w-h_{jk}q_j\\ &\quad end\\ &\quad \quad h_{k+1,k}=||w||_2(如果 h_{k+1,k}=0,跳过下一行并在底端终止)\\ &\quad \quad q_{k+1}=w/h_{k+1,k}\\ &\quad \quad min||Hc_k-[||r||_2,0,0,\dots,0]^T||_2得到c_k\\ &\quad \quad x_k=Q_kc_k+x_0\\ &end \end{align}
7 非线性最小二乘
线性方程组 Ax=b 的最小二乘解通过最小化余项的欧几里得范数 ||Ax-b||_2 ,可以通过法线方程或QR分解来求出最小二乘解。
但是如果是非线性系统,两种方法都不能用,就要选择别的方法。
7.1 高斯-牛顿方法
考虑m个方程n个未知变量的方程组
\\ r_1(x_1,\dots,x_n)=0\\ \vdots\\ r_m(x_1,\dots,x_n)=0\\
误差的平方和为:
\\E(x_1,\dots,x_n)=\frac{1}{2}(r_1^2+\dots+r_m^2)=\frac{1}{2}r^Tr,r=[r_1,\dots,r_m]^T
那么目标就很明显了,即最小化误差的平方和,那么令梯度 :
\\F(x)=\nabla E(x)=r(x)^TDr(x)=0
对列向量函数 F(x)^T=(Dr)^Tr 求导就有:
D((Dr)^Tr)=(Dr)^TDr+\sum_{i=1}^{m}{r_iDc_i} , c_i 是 Dr 的第 i 列,注意到 Dc_i=H_{r_i} ,即 r_i 的二阶偏导矩阵(海森Hessian矩阵):
\\ H_{r_i}=\begin{bmatrix} &\frac{\partial^2r_i}{\partial x_1 \partial x_1}&\cdots&\frac{\partial^2r_i}{\partial x_1 \partial x_n}\\ &\vdots&&\vdots\\ &\frac{\partial^2r_i}{\partial x_n \partial x_1}&\cdots&\frac{\partial^2r_i}{\partial x_n \partial x_n} \end{bmatrix}
通过舍掉部分很项就可以简化牛顿方法,不使用上面的n步求和,就有:
高斯-牛顿方法:
\\\begin{align} &为了min \ r_1(x^2)+\dots+r_m(x)^2\\ &令x^0=初始向量\\ &for \ k=0,1,2,\dots\\ &\quad A=Dr(x^k)\\ &\quad A^TAv^k=-A^Tr(x^k)\\ &\quad x^{k+1}=x^k+v^k\\ &end \end{align}
注意到高斯-牛顿法的每步都有法线方程的影子,其中的系数矩阵替换为Dr,高斯-牛顿求解了平方误差梯度的根,在最小化时,梯度必然是0,但是其收敛并不确定,方法可能收敛到极大值或者中间点,在解释算法结果时需要十分注意。
7.2 具有非线性参数的模型
高斯-牛顿方法的重要应用是拟合具有非线性参数的模型,令 (t_1,y_1),\dots,(t_m,y_m) 是数据点, y=f_c(x) 是要进行拟合函数,其中 c=[c_1,\dots,c_p] 是一组选择的参数,用以最小化余项的平方和:
\\ r_1(c)=f_c(t_1)-y_1\\ \vdots\\ r_m(c)=f_c(t_m)-y_m\\
如果参数 c_1,\dots,c_p 以线性的方式引入模型,法线方程或者QR分解可以求解关于参数c的最优选择,如果参数 c_i 在模型中是非线性,相同的处理得到一组关于 c_i 的非线性方程组,例如,将模型 y=c_it^{c_2} 拟合至数据点 (t_i,y_i) 得到非线性方程:
\\ y_1=c_1t_1^{c_2}\\ y_2=c_1t_2^{c_2}\\ \vdots\\ y_m=c_1t_m^{c_2}\\ 由于 c_2 以非线性方式被引入模型,方程组无法写成矩阵形式。
当然可以通过对模型两侧取对数,用最小二乘最小化对数形式的误差,但是为了求解原始的最小二乘问题,使用高斯-牛顿法,去最小化误差E,E是关于向量c的函数,矩阵Dr是误差 r_i 关于参数 c_j 的偏导数矩阵:
\\ (Dr)_{ij}=\frac{\partial r_i}{\partial c_j}=f_{c_j}(t_i)
这样,就可以套用上面的高斯-牛顿方法。
7.3 Levenberg-Marquardt方法
当最小二乘系数矩阵变为病态矩阵时,由于 A^TA 的大条件数求解就会很难,对于非线性最小二乘问题,情况会变得更加糟糕,Levenberg-Marquardt方法选择引入“正则化项”来修复这个问题,可以看做是混合高斯-牛顿法和最速下降法,关于最速下降法后面的帖子再介绍。
Levenberg-Marquardt方法是高斯-牛顿法的简单改进:
Levenberg-Marquardt方法
\\\begin{align} &为了min \ r_1(x^2)+\dots+r_m(x)^2\\ &令x^0=初始向量,\lambda=const\\ &for \ k=0,1,2,\dots\\ &\quad A=Dr(x^k)\\ &\quad (A^TA+\lambda diag(A^TA))v^k=-A^Tr(x^k)\\ &\quad x^{k+1}=x^k+v^k\\ &end \end{align}
\lambda=0 的情况就和高斯-牛顿法相同,提高正则化参数则增强了矩阵 A^TA 对角线元素的作用,这样通常可以改善条件数,允许方法从一个更宽的初始估计开始并实现收敛。
注意,为了尽量简单,将 \lambda 视为常数,但是该方法常常使用不同的 \lambda 来适应问题,一般的策略是在每个迭代步骤中,只要余下的平方误差和在每步中降低,就使用因子10连续降低 \lambda ,如果误差升高,则拒绝当前步,并以因子10升高 \lambda 。