二分查找有几种写法?它们的区别是什么?
115 个回答

更新:一图解释二分法分类
强烈安利C++和Python标准库的超简洁、bug free的通用写法(C++: lower_bound; 感谢评论区指认出Python标准库的bisect_left)
6行Python解决,同时适用于区间为空、答案不存在、有重复元素、搜索开/闭的上/下界等情况:
def lower_bound(array, first, last, value): # 求非降序范围[first, last)内第一个不小于value的值的位置
while first < last: # 搜索区间[first, last)不为空
mid = first + (last - first) // 2 # 防溢出
if array[mid] < value: first = mid + 1
else: last = mid
return first # last也行,因为[first, last)为空的时候它们重合\pm 1 的位置调整只出现了一次!而且最后返回first或last都是对的,无需纠结!

诀窍是搜索区间[first, last)左闭右开!
好处都有啥?请下滑看看"Dijkstra的干货/题外话"ヽ(゚▽゚)ノ
(你一直在用的)两头闭区间[l, r]写出来的binary search一般免不了多写一两个+1,-1,return,而且区间为空时l和r只有一个是正确答案,极易出错,除非你有肌肉记忆。
如果你想求的不是第一个不小于value的值的位置,而是任意等于value的值的位置,你可以在更新[first, last)区间之前先检查array[mid] == value是否成立。以下我们只讨论广义的求上界、下界的二分搜索,适用于完全相等的值不存在的情况。
担心搞错范围/终止条件/edge case?
array不是升序怎么办?
且听我徐徐道来ヽ(゚▽゚)ノ
二分查找有几种写法?
一图即可解释,在array中搜索value=3:
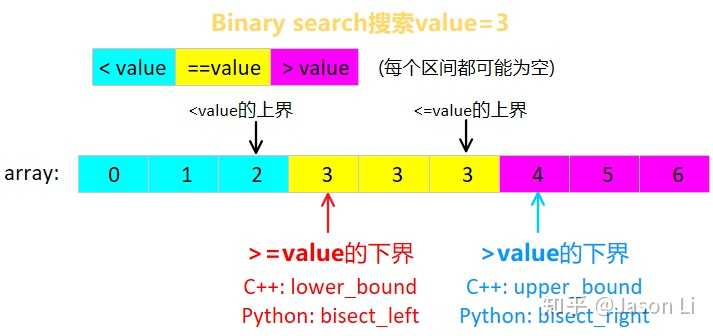

Binary search找的无非是四个箭头中的一个:开/闭区间,上/下界。C++和Python标准库都只提供了找下界的函数,下标减一即可获得相邻互补的上界。如果只需找任意一个黄色value,可直接找闭区间下界(红箭头),然后再检查一次是否等于value;当然,也可以在二分法循环中检查。只讨论输入array是非降序non-descending order的情况。其他情况,如降序,可以通过自定义比较函数轻松转化为这种情况而无需修改原array。
一、搜索区间和中点
i) 求下界,即找满足x >= value或x > value条件的最小x的位置,
用左闭右开搜索区间[first, last),
区间为空时终止并返回first或last(重合,无需纠结),
求中点时从下界first(闭区间侧)出发: mid = first + (last - first) / 2,
以确保区间长度为1时,mid = first仍在[first, first + 1)区间内;
ii) 求上界(找满足x < value 或 x <= value条件的最大x的位置),可以调用互补的求下界的函数再减一得到,如x >= value的下界再减一就是x < value的上界,所以C++标准库只提供求下界的两个函数。
如果非要写(不推荐),则是求下界的镜面情况,把所有数组下标反过来即可:
用左开右闭搜索区间(first, last],
区间为空时终止并返回last或first(重合,无需纠结),
求中点时从上界last(仍为闭区间侧)出发: mid = last - (last - first) / 2,
以确保区间长度为1时,mid = last仍在(last - 1, last]区间内。
中点mid有了,怎样缩小区间才能不出错?
请往下看到"四、while loop的循环不变量"ヽ(゚▽゚)ノ有图有真相
(以下为详细解说,括号内的斜体为C++相关的选读(逃))

二、Dijkstra的干货/题外话
为什么区间要写成左闭右开?怕傻傻分不清楚,一直用两头闭区间?
其实我们早就习惯了左闭右开区间,只不过你忘了它的便利。
例如:遍历长度为n的数组,下标i你是怎么写的?
你一定是使用左闭右开区间[0, n)作为起始和终止条件,这样一来循环执行次数为n,for loop结束时i == n,一目了然,且无需多余的 \pm 1 边界调整:
for (size_t i = 0; i < n; ++i) {
// i is in [0, n)
}换成Python 3,区间则是range(start, stop[, step]),左闭(包括起点start)右开(不包括终点stop):
for i in range(n):
# 等价于range(0, n)或range(0, n, 1)
# i is in [0, n)同理的还有Python的slice,如list slicing:arr[start:stop]以及arr[start:stop:step]。
一切始于图灵奖得主Dijkstra(没错就是20分钟内不用纸笔发明Dijkstra's Algorithm的那位神人)早在1982年的安利(他还安利过goto有害论,并且成功了),大意是:
假设有一个长度为4的数组,用整数边界的区间表示它的下标0, 1, 2, 3,有四种写法:
a) 0 ≤ i < 4
b) -1 < i ≤ 3
c) 0 ≤ i ≤ 3
d) -1 < i < 4
显然左边不闭的话-1太丑了,所以只考虑a)和c),然后怎么取舍呢?
现在假设该数组长度慢慢减小到0,右边界减小,此时它的index范围是空集 \varnothing ,整数边界的区间的四种写法变成了:
a) 0 ≤ i < 0
b) -1 < i ≤ -1
c) 0 ≤ i ≤ -1
d) -1 < i < 0
现在只有a)不会出现负数了。看来左闭右开的a)是唯一一种不反人类的写法!它还有一些个好处:
1. 区间两端值的差,如[0, 4)中的4 - 0 = 4,正好是区间或数组的长度
2. 刚好相邻的区间,如[0, 2)和[2, 4), 中间值(即2)相同,一眼就可以看出来
综上,代码中使用a)的左闭右开区间既符合直觉,又可以省去代码中大量的+1和-1和edge case检查,减少off-by-one error,提高效率。
三、while loop第一行:如何取中点
现在我们知道lower_bound在干啥,以及为啥区间要写成左闭右开了。
我们来看循环第一行,mid = first + (last - first) // 2,为何中点这么取?
def lower_bound(array, first, last, value):
while first < last: # 搜索区间[first, last)不为空
mid = first + (last - first) // 2 # 防溢出
if array[mid] < value: first = mid + 1
else: last = mid
return first # last也行,因为此时重合如 @胖君 等大佬们所言,
若用mid = (first + last) / 2算中点(下标的中位数),在C++、Java等语言里(first + last)可能会溢出。
讽刺的是,这是多年以前的标准写法,且问题存在了20年都没被发现,比如Java标准库java.util.Arrays里的binarySearch,因为当年的硬件限制了数组长度,所以测试的时候没有溢出。
解决方案就是我们的写法。评论区有人问为什么可以这么写,其实很简单:mid = (first + last) / 2= (2 * first + last - first) / 2= first + length / 2,
其中length = last - first为区间长度。
Python有big integer所以不怕溢出,但要记得Python 3 的整除是//。
此外,中点的选择并不唯一:
1. 上位中位数:upperMid = first + length / 2(不用-1,就它了)
2. 下位中位数:lowerMid = first + (length - 1) / 2
不难发现只有length为偶数时它们才不同,分别是中间那一对下标中的更大和更小的,想想[0, 3)和[0, 4)就很好懂了。
由于这两个中位数都在区间[first, last)内,所以都可以采用。算上位中位数不用-1,就是你了!
陷阱: 当我们使用左开右闭区间(first, last]找上界时,闭区间在右侧!本文开头已经说明,算中点时应从闭区间一侧向中心靠拢:
mid = last - (last - first) / 2
以确保区间长度为1时,mid = last仍在(last - 1, last]区间内
如果不小心写成mid = first + (last - first) / 2 那么此时mid = first就超出(first, last]范围了,要么溢出要么死循环!
所以推荐用互补的求下界的函数,再减一得到上界。
四、while loop的循环不变量 - loop invariants
(怎样缩小区间才不出错)(会写代码 vs 会用计算机科学的思考方式)
要真正理解这6行代码为啥能出正确答案,并每次写binary search都能bug free(而不是靠先写错再debug,或者死记硬背上/下界开/闭区间的四种情况,甚至其他答案说的区间长度小于一定值时暴力分类讨论),首先需要理解while循环里的loop invariants (循环不变量),也就是代码跑到while里面时一定成立的条件(别怕,下面有图):
- 搜索范围
[first, last)不为空,即first < last; - 搜索范围
[first, last)左侧,即[first0, first)内所有元素(若存在),都小于value,其中first0是first的初始值; - 搜索范围
[first, last)右侧,即[last, last0)内所有元素(若存在),都大于等于value,其中last0是last的初始值。
再看一遍代码:
def lower_bound(array, first, last, value):
while first < last: # 搜索区间[first, last)不为空
mid = first + (last - first) // 2 # 防溢出
if array[mid] < value: first = mid + 1
else: last = mid
return first # last也行,因为此时重合(图来啦)举个栗子,搜索整个array = [-1, 0, 0, 3, 3, 3, 7, 8, 9],value = 3
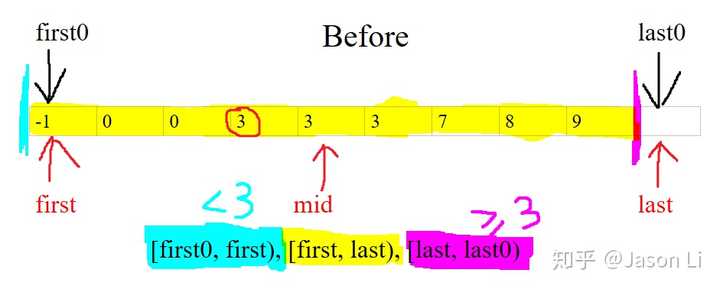

一开始黄色的搜索区间左右(青、紫)都是空的,loop invariants的2和3自然满足。
上图array[mid] >= 3,说明mid属于紫色!
在已知信息下,最大限度合理扩张紫色区间、缩小黄色搜索区间长度的操作是:
把last放到上图中mid的位置,即last = mid :
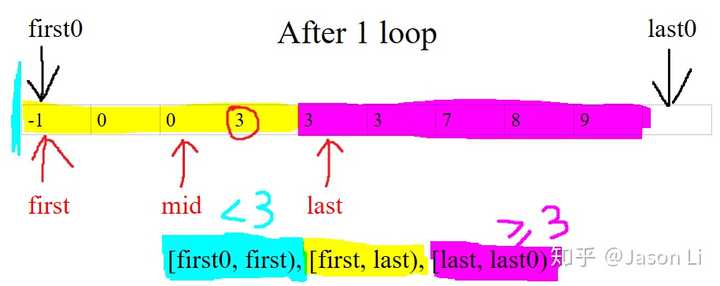

如上图,新的mid满足array[mid] < 3,说明mid属于青色!在已知信息下,最大限度合理扩张青色区间、缩小黄色搜索区间长度的操作是:first = mid + 1:
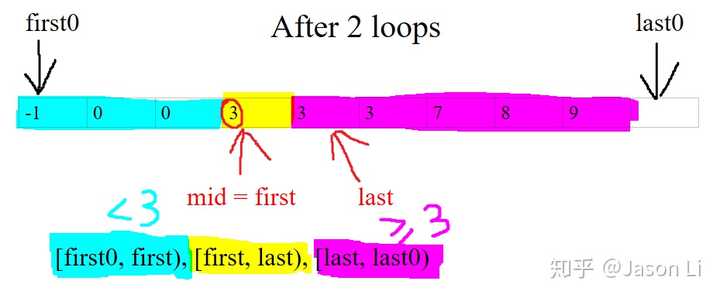

现在搜索区间长度缩短到1了!可以返回first了吗?不行,我们检查过了红圈左边和右边,却没有检查红圈本身。如果红圈是2,那么答案应该是上图的last才对。
之所以更新first或last的时候要最大限度缩小搜索区间(first更新为mid + 1而非弱一点的mid,last更新为mid而非弱一点的mid + 1),主要考虑并不是这个效率efficiency,而是上图区间长度为1的情况!此时mid就是first,mid + 1就是last,于是弱一点的更新等于没有更新,会导致死循环!

最后一步,上图中array[mid] >= 3,mid属于紫色,于是last左移一位,搜索结束:


最后区间[first, last)为空,青区间和紫区间都最大限度扩张了。所以,根据紫区间的定义任意元素 >= 3,已经饱和的它,第一个元素(若存在)的位置last就是答案!若没有满足要求x >= 3的元素,那么紫区间就是空的,停留在初始状态[last0, last0),所以返回的是last0,即初始范围之后的第一个元素,表示“不存在”,无需特殊处理!
皆大欢喜的是,first与last重合,所以完全不需要纠结返回哪个!感谢Dijkstra!

五、C++中的相关函数
C++的lower_bound()搞明白了,那么upper_bound()和equal_range()又是怎么回事呢?
upper_bound() 和 lower_bound()一样是下界搜索,唯一不同的是第四行的if中的判断条件从:
lower_bound() 的 array[mid] < value,即小于,
变成了 upper_bound()的!(value < array[mid]),即array[mid] <= value,(用小于号判断小于等于关系:前面提到小于号是STL唯一的比较函数,且可以自定义)
所以upper_bound()返回的是第一个大于value的位置。
如此一来,[first, last)中与value 等价的元素的范围就是:
[lower_bound(value), upper_bound(value))
它们分别是这个区间的(左闭)下界和(右开)上界,因此得名。equal_range(value)的作用是同时返回这两个位置。
六、理解并使用C++<algorithm> 和Python bisect的二分查找函数
如何用lower_bound/bisect_left和upper_bound/bisect_right在[first, last)完成所有四种binary search (上/下界,开/闭区间)?
lower_bound(value)本身找的是x >= value的下界,若为last则不存在;upper_bound(value)本身找的是x > value的下界,若为last则不存在;
因为区间是离散的,所以:
3. lower_bound(value) - 1 即为x < value的上界,若为first - 1则不存在;
4. upper_bound(value) - 1 即为x <= value的上界,若为first - 1则不存在。
相应代码可以参考 @LightGHLi 的高赞回答末尾。注意实际在C++中调用时,表示位置的first,last以及返回值不是Python代码中的下标int,而是Container<T>::iterator类型。
