如何理解Transformer论文中的positional encoding,和三角函数有什么关系?
28 个回答

10.21 更新:昨天回答了编码相加融入词序信息的问题,在回答与讨论中学到了很多,现在对原回答做一定的补充。
题主的问题:
- 如何理解 Transformer 中的 positional encoding
- 为什么是三角函数,具体解释论文中的正弦和余弦公式
- 为什么这样就可以引入位置信息了
为什么 Transformer 需要 positional encoding ?
在没有 Position embedding 的 Transformer 模型并不能捕捉序列的顺序,交换单词位置后 attention map 的对应位置数值也会进行交换,并不会产生数值变化,即没有词序信息。所以这时候想要将词序信息加入到模型中。
那么接下来的问题就是如何生成词序信息以及如何加入到模型中去?
以往大多根据任务训练出来的向量(如 Convolutional Sequence to Sequence Learning),而 Transformer 采用公式生成,避免了训练得到的位置向量固定长度的尴尬,提供了相对位置信息。不过后来的 BERT 中使用的是训练得到的位置向量,我乎上也有相关问题提出,个人觉得还是由于实验效果的对比,并且由于需要适应各种下游任务而不仅仅是 NMT 任务,所以可以说是庞大的数据集足够训练好位置向量,多样的下游任务需求也需要训练得到的位置向量。
关于如何生成词序信息的问题,可能让人迷惑的是词序信息是什么呢?这里以情感分析 sentiment analysis 为例:
I like this movie because it doesn't have an overhead history. Positive
I don't like this movie because it has an overhead history. Negative.don’t 的位置不同,决定了这两句话的情感取向是一正一负的,但在传统词袋模型中,这两句话得到的句子表征却是一致的,可见单词的位置对句子含义很重要。并且在本例子中, don't 和 like 的相对位置对句子含义而言起了关键作用,这里可以联想词向量中的分布语义假设“You shall know a word by the company it keeps” :词的含义可由其上下文词的分布进行表示,进行理解。
词序信息的表示方法很丰富,但究其根本,需要的是对不同维度的不同位置生成合理的数值表示。这里的合理,理解为不同位置的同一维度的位置向量之间,含有相对位置信息,而相对位置信息可以通过函数的周期性实现。
Transformer 使用的解决方案是三角函数实现相对位置信息的表示。原回答已经对论文中的公式做了细致的解释,实质上就是对不同维度使用不同频率的正/余弦公式进而生成不同位置的高维位置向量。
不过这里有一点需要解释,为什么奇偶维度之间需要作出区分,分别使用 sin 和 cos 呢?
个人觉得主要是因为三角函数的积化和差公式,公式 (2)(3) 给出了一定解释。不过也正如tensor2tensor 的作者对其简洁版本公式的解释那样,奇偶区分可以通过全连接层帮助重排坐标,所以可以直接简单地分为两段(前 256 维使用 sin,后 256 维使用 cos)。
那么我们如何加入到模型中去呢?
fairseq 和 Transformer 都是直接把词向量和位置向量直接相加的方式,让人感到疑惑的是为什么不进行拼接?
[W1 W2][e; p] = W1e + W2p,W(e+p)=We+Wp,就是说求和相当于拼接的两个权重矩阵共享(W1=W2=W),所以拼接总是不会比相加差的。
词向量 E 和位置向量 P 相加再经过后续的线性变换,可以理解为 W(E+P) = W \ E + W \ P ;而当两个向量拼接后经过后续的线性变换,可以理解为 [W_1\ W_2][E; P] = W_1\ E + W_2\ P ,那么当 W_1 = W_2 时,二者的效果是等价的。我们可以由此发现,拼接总是不会比相加差的,但是由于参数量的增加,其学习难度也会进一步上升。
无论拼接还是相加,最终都要经过多头注意力的各个头入口处的线性变换,进行特征重新组合与降维,其实每一维都变成了之前所有维向量的线性组合。所以这个决定看上去是根据效果决定的,参数少效果好的相加自然成了模型的选择。
在这里看到说拼接的效果有时积极有时消极,不过没有给出相关链接,如果了解的知友还请告知。
首先解释下论文中的公式,并给出对应代码,Positional Encoding 的公式如下[1]:
\begin{equation} \begin{cases} PE(pos, 2i)=\sin \left(pos / 10000^{2 i / d_{model}}\right) \\ PE(\text {pos}, 2 i+1)=\cos \left(pos / 10000^{2 i / d_{model}}\right) \end{cases} \end{equation} \\ \tag{1}
其中,pos 即 position,意为 token 在句中的位置,设句子长度为 L ,则 pos = 0,1,...,L-1 ;i 为向量的某一维度,例如 d_{model}=512 时, i = 0,1,...,255 。
对应代码实现如下[2]:
class PositionalEncoding(nn.Module):
"Implement the PE function."
def __init__(self, d_model, dropout, max_len=5000):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout)
# Compute the positional encodings once in log space.
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2) *
-(math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0)
self.register_buffer('pe', pe)
def forward(self, x):
x = x + Variable(self.pe[:, :x.size(1)],
requires_grad=False)
return self.dropout(x)借助上述公式,我们可以得到一个特定位置的 d_{model} 维的位置向量,并且借助三角函数的性质
\begin{cases} sin(α+β)=sinαcosβ+cosαsinβ \\ cos(α+β)=cosαcosβ−sinαsinβ \\ \end{cases} \tag{2}
我们可以得到:
\begin{cases} PE(pos + k,2i) = PE(pos,2i) \times PE(k,2i+1) + PE(pos, 2i+1) \times PE(k,2i) \\ PE(pos + k,2i+1) = PE(pos,2i+1) \times PE(k,2i+1) - PE(pos, 2i) \times PE(k,2i) \end{cases} \tag{3}
可以看出,对于 pos+k 位置的位置向量某一维 2i 或 2i+1 而言,可以表示为,pos 位置与 k 位置的位置向量的2i 与 2i+1维的线性组合,这样的线性组合意味着位置向量中蕴含了相对位置信息。
接着,我们需要将位置向量与词向量相结合。一般来说,可以使用向量拼接或直接相加的方式将二者结合起来。最后,@小莲子 的答案中,提到了 tensor2tensor 的最初版本只是简单地分了两段(前 256 维使用 sin,后 256 维使用 cos),并且作者解释是因为后面的全连接层可以帮助重排坐标。这里所说的全连接层,应该是指词向量与位置向量相加后,进入到 Multi-Head Attention 模块时的第一步—— Linear 层的线性转换。
我们以 KQV 中的 K 为例,其 Linear 层的参数矩阵为 W^K \in \mathbb{R}^{d_{\text{model}} \times d_k} ,输入向量的矩阵为 E \in \mathbb{R}^{L \times d_{\text{model}}} ,其中 L 为句子长度。那么 E W^K \in \mathbb{R}^{L \times d_{\text{k}}} ,我们可以将其视为,E 的每一行与矩阵 W^K 相乘,即:


可以直观的看到,句子中的每个词向量都经过了矩阵W^K作了线性变换。这就是作者解释中的“帮助重排坐标”。
参考
- ^《Attention is All You Need》 https://arxiv.org/pdf/1706.03762.pdf
- ^The Annotated Transformer http://nlp.seas.harvard.edu/2018/04/03/attention.html



自从2017年Transformer模型被提出以来,它已经从论文最初的机器翻译领域,转向图像,语音,视频等等方面的应用(实现作者们在论文结论里的大同之梦)。原论文的篇幅很紧密,不看代码的话,缺乏了很多细节描述。我的学历经历大概是两周啃paper+代码 => 两周挖细节=>未来这个模型还有很多值得端详。在Transformer系列的笔记里,我把模型拆成了各个零件进行学习,最后把这些零件组装成Transformer,涵盖内容如下:
- Positional Encoding (位置编码)
- Self-attention(自注意力机制)
- Batch Norm & Layer Norm(批量标准化/层标准化)
- ResNet(残差网络)
- Subword Tokenization(子词分词法)
- 组装:Transformer
这是Transformer系列的第一篇,这一篇来探索位置编码。
一、什么是位置编码


在transformer的encoder和decoder的输入层中,使用了Positional Encoding,使得最终的输入满足:
input = input_embedding + positional_encoding
这里,input_embedding是通过常规embedding层,将每一个token的向量维度从vocab_size映射到d_model,由于是相加关系,自然而然地,这里的positional_encoding也是一个d_model维度的向量。(在原论文里,d_model = 512)
那么,我们为什么需要position encoding呢?在transformer的self-attention模块中,序列的输入输出如下(不了解self-attention没关系,这里只要关注它的输入输出就行):


在self-attention模型中,输入是一整排的tokens,对于人来说,我们很容易知道tokens的位置信息,比如:
(1)绝对位置信息。a1是第一个token,a2是第二个token......
(2)相对位置信息。a2在a1的后面一位,a4在a2的后面两位......
(3)不同位置间的距离。a1和a3差两个位置,a1和a4差三个位置....
但是这些对于self-attention来说,是无法分辩的信息,因为self-attention的运算是无向的。因为,我们要想办法,把tokens的位置信息,喂给模型。
二、构造位置编码的方法 /演变历程
2.1 用整型值标记位置
一种自然而然的想法是,给第一个token标记1,给第二个token标记2...,以此类推。
这种方法产生了以下几个主要问题:
(1)模型可能遇见比训练时所用的序列更长的序列。不利于模型的泛化。
(2)模型的位置表示是无界的。随着序列长度的增加,位置值会越来越大。
2.2 用[0,1]范围标记位置
为了解决整型值带来的问题,可以考虑将位置值的范围限制在[0, 1]之内,其中,0表示第一个token,1表示最后一个token。比如有3个token,那么位置信息就表示成[0, 0.5, 1];若有四个token,位置信息就表示成[0, 0.33, 0.69, 1]。
但这样产生的问题是,当序列长度不同时,token间的相对距离是不一样的。例如在序列长度为3时,token间的相对距离为0.5;在序列长度为4时,token间的相对距离就变为0.33。
因此,我们需要这样一种位置表示方式,满足于:
(1)它能用来表示一个token在序列中的绝对位置
(2)在序列长度不同的情况下,不同序列中token的相对位置/距离也要保持一致
(3)可以用来表示模型在训练过程中从来没有看到过的句子长度。
2.3 用二进制向量标记位置
考虑到位置信息作用在input embedding上,因此比起用单一的值,更好的方案是用一个和input embedding维度一样的向量来表示位置。这时我们就很容易想到二进制编码。如下图,假设d_model = 3,那么我们的位置向量可以表示成:


这下所有的值都是有界的(位于0,1之间),且transformer中的d_model本来就足够大,基本可以把我们要的每一个位置都编码出来了。
但是这种编码方式也存在问题:这样编码出来的位置向量,处在一个离散的空间中,不同位置间的变化是不连续的。假设d_model = 2,我们有4个位置需要编码,这四个位置向量可以表示成[0,0],[0,1],[1,0],[1,1]。我们把它的位置向量空间做出来:


如果我们能把离散空间(黑色的线)转换到连续空间(蓝色的线),那么我们就能解决位置距离不连续的问题。同时,我们不仅能用位置向量表示整型,我们还可以用位置向量来表示浮点型。
2.4 用周期函数(sin)来表示位置
回想一下,现在我们需要一个有界又连续的函数,最简单的,正弦函数sin就可以满足这一点。我们可以考虑把位置向量当中的每一个元素都用一个sin函数来表示,则第t个token的位置向量可以表示为:
PE_t = [sin(\frac{1}{2^0}t),sin(\frac{1}{2^1}t)...,sin(\frac{1}{2^{i-1}}t), ...,sin(\frac{1}{2^{d_{model}-1}}t)]\\
结合下图,来理解一下这样设计的含义。图中每一行表示一个 PE_t ,每一列表示 PE_t 中的第i个元素。旋钮用于调整精度,越往右边的旋钮,需要调整的精度越大,因此指针移动的步伐越小。每一排的旋钮都在上一排的基础上进行调整(函数中t的作用)。通过频率 \frac{1}{2^{i-1}} 来控制sin函数的波长,频率不断减小,则波长不断变大,此时sin函数对t的变动越不敏感,以此来达到越向右的旋钮,指针移动步伐越小的目的。 这也类似于二进制编码,每一位上都是0和1的交互,越往低位走(越往左边走),交互的频率越慢。

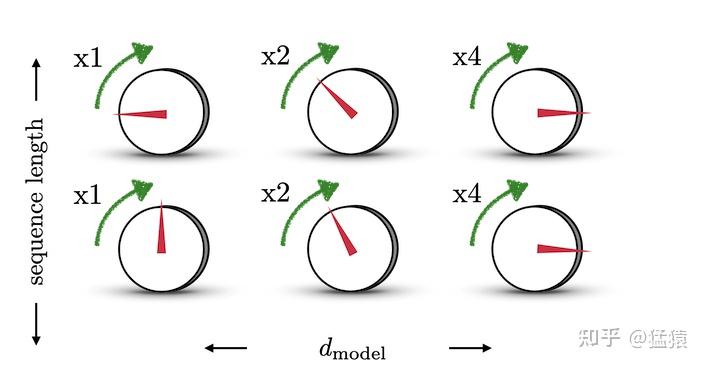

由于sin是周期函数,因此从纵向来看,如果函数的频率偏大,引起波长偏短,则不同t下的位置向量可能出现重合的情况。比如在下图中(d_model = 3),图中的点表示每个token的位置向量,颜色越深,token的位置越往后,在频率偏大的情况下,位置响亮点连成了一个闭环,靠前位置(黄色)和靠后位置(棕黑色)竟然靠得非常近:

为了避免这种情况,我们尽量将函数的波长拉长。一种简单的解决办法是同一把所有的频率都设成一个非常小的值。因此在transformer的论文中,采用了 \frac{1}{10000^{i/(d_{model}-1)}} 这个频率(这里i其实不是表示第i个位置,但是大致意思差不多,下面会细说)
总结一下,到这里我们把位置向量表示为:
PE_t = [sin(w_0t),sin(w_1t)...,sin(w_{i-1}t), ...,sin(w_{d_{model}-1}t)]\\
其中, w_{i} = \frac{1}{10000^{i/(d_{model}-1)}}
2.5 用sin和cos交替来表示位置
目前为止,我们的位置向量实现了如下功能:
(1)每个token的向量唯一(每个sin函数的频率足够小)
(2)位置向量的值是有界的,且位于连续空间中。模型在处理位置向量时更容易泛化,即更好处理长度和训练数据分布不一致的序列(sin函数本身的性质)
那现在我们对位置向量再提出一个要求,不同的位置向量是可以通过线性转换得到的。这样,我们不仅能表示一个token的绝对位置,还可以表示一个token的相对位置,即我们想要:
PE_{t+\bigtriangleup t} = T_{\bigtriangleup t} * PE_{t} \\
这里,T表示一个线性变换矩阵。观察这个目标式子,联想到在向量空间中一种常用的线形变换——旋转。在这里,我们将t想象为一个角度,那么 \bigtriangleup t就是其旋转的角度,则上面的式子可以进一步写成:
\begin{pmatrix} \sin(t + \bigtriangleup t)\\ \cos((t + \bigtriangleup t) \end{pmatrix}=\begin{pmatrix} \cos\bigtriangleup t&\sin\bigtriangleup t \\ -\sin\bigtriangleup t&\cos\bigtriangleup t \end{pmatrix}\begin{pmatrix} \sin t\\ \cos t \end{pmatrix} \\
有了这个构想,我们就可以把原来元素全都是sin函数的 PE_t 做一个替换,我们让位置两两一组,分别用sin和cos的函数对来表示它们,则现在我们有:
PE_t = [sin(w_0t),cos(w_0t), sin(w_1t),cos(w_1t),...,sin(w_{\frac{d_{model}}{2}-1}t), cos(w_{\frac{d_{model}}{2}-1}t)]
在这样的表示下,我们可以很容易用一个线性变换,把 PE_t 转变为 PE_{t + \bigtriangleup t} :
PE_{t+\bigtriangleup t} = T_{\bigtriangleup t} * PE_{t} =\begin{pmatrix} \begin{bmatrix} cos(w_0\bigtriangleup t)& sin(w_0\bigtriangleup t)\\ -sin(w_0\bigtriangleup t)& cos(w_0\bigtriangleup t) \end{bmatrix}&...&0 \\ ...& ...& ...\\ 0& ...& \begin{bmatrix} cos(w_{\frac{d_{model}}{2}-1 }\bigtriangleup t)& sin(w_{\frac{d_{model}}{2}-1}\bigtriangleup t)\\ -sin(w_{\frac{d_{model}}{2}-1}\bigtriangleup t)& cos(w_{\frac{d_{model}}{2}-1}\bigtriangleup t) \end{bmatrix} \end{pmatrix}\begin{pmatrix} sin(w_0t)\\ cos(w_0t)\\ ...\\ sin(w_{\frac{d_{model}}{2}-1}t)\\ cos(w_{\frac{d_{model}}{2}-1}t) \end{pmatrix} = \begin{pmatrix} sin(w_0(t+\bigtriangleup t))\\ cos(w_0(t+\bigtriangleup t))\\ ...\\ sin(w_{\frac{d_{model}}{2}-1}(t+\bigtriangleup t))\\ cos(w_{\frac{d_{model}}{2}-1}(t+\bigtriangleup t)) \end{pmatrix}
三、Transformer中位置编码方法:Sinusoidal functions
3.1 Transformer 位置编码定义
有了上面的演变过程后,现在我们就可以正式来看transformer中的位置编码方法了。
定义:
- t是这个token在序列中的实际位置(例如第一个token为1,第二个token为2...)
- PE_t\in\mathbb{R}^d 是这个token的位置向量, PE_{t}^{(i)} 表示这个位置向量里的第i个元素
- d_{model} 是这个token的维度(在论文中,是512)
则 PE_{t}^{(i)} 可以表示为:
PE_{t}^{(i)} = \left\{\begin{matrix} \sin(w_it),&if\ k=2i \\ \cos(w_it),&if\ k = 2i+1 \end{matrix}\right.\\
这里:
w_i = \frac{1}{10000^{2i/d_{model}}}\\
i = 0,1,2,3,...,\frac{d_{model}}{2} -1\\
看得有点懵不要紧,这个意思和2.5中的意思是一模一样的,把512维的向量两两一组,每组都是一个sin和一个cos,这两个函数共享同一个频率 w_i ,一共有256组,由于我们从0开始编号,所以最后一组编号是255。sin/cos函数的波长(由 w_i 决定)则从 2\pi 增长到 2\pi * 10000
3.2 Transformer位置编码可视化
下图是一串序列长度为50,位置编码维度为128的位置编码可视化结果:


可以发现,由于sin/cos函数的性质,位置向量的每一个值都位于[-1, 1]之间。同时,纵向来看,图的右半边几乎都是蓝色的,这是因为越往后的位置,频率越小,波长越长,所以不同的t对最终的结果影响不大。而越往左边走,颜色交替的频率越频繁。
3.3 Transformer位置编码的重要性质
让我们再深入探究一下位置编码的性质。
(1) 性质一:两个位置编码的点积(dot product)仅取决于偏移量 \bigtriangleup t ,也即两个位置编码的点积可以反应出两个位置编码间的距离。
证明:
\begin{aligned} PE_{t}^{T}*PE_{t+\bigtriangleup t} &= \sum_{i = 0}^{\frac{d_{model}}{2}-1} [sin(w_it)sin(w_i(t+\bigtriangleup t) + cos(w_it)cos(w_i(t+\bigtriangleup t)]\\ &= \sum_{i = 0}^{\frac{d_{model}}{2}-1}cos(w_i(t-(t+\bigtriangleup t)))\\ & = \sum_{i = 0}^{\frac{d_{model}}{2}-1}cos(w_i\bigtriangleup t) \end{aligned}
(2) 性质二:位置编码的点积是无向的,即 PE_{t}^{T}*PE_{t+\bigtriangleup t} = PE_{t}^{T}*PE_{t-\bigtriangleup t}
证明:
由于cos函数的对称性,基于性质1,这一点即可证明。
我们可以分别训练不同维度的位置向量,然后以某个位置向量 PE_t 为基准,去计算其左右和它相距 \bigtriangleup t 的位置向量的点积,可以得到如下结果:

这里横轴的k指的就是 \bigtriangleup t ,可以发现,距离是对成分布的,且总体来说, \bigtriangleup t 越大或者越小的时候,内积也越小,可以反馈距离的远近。也就是说,虽然位置向量的点积可以用于表示距离(distance-aware),但是它却不能用来表示位置的方向性(lack-of-directionality)。
当位置编码随着input被喂进attention层时,采用的映射方其实是:
PE_t^TW_Q^TW_KPE_{t+k}\\
这里 W_Q^T 和 W_K 表示self-attention中的query和key参数矩阵,他们可以被简写成 W 表示attention score的矩阵,到这里看不懂也没事,在self-attention的笔记里会说明的)。我们可以随机初始化两组 W_1,W_2 ,然后将 PE_t^TW_1PE_{t+k} , PE_t^TW_2PE_{t+k} 和 PE_t^TPE_{t+k} 这三个内积进行比较,得到的结果如下:

绿色和黄色即是 W_1 和 W_2 的结果。可以发现,进入attention层之后,内积的距离意识(distance-aware)的模式也遭到了破坏。更详细的细节,可以参见复旦大学这一篇用transformer做NER的论文中。
在Transformer的论文中,比较了用positional encoding和learnable position embedding(让模型自己学位置参数)两种方法,得到的结论是两种方法对模型最终的衡量指标差别不大。不过在后面的BERT中,已经改成用learnable position embedding的方法了,也许是因为positional encoding在进attention层后一些优异性质消失的原因(猜想)。Positional encoding有一些想象+实验+论证的意味,而编码的方式也不只这一种,比如把sin和cos换个位置,依然可以用来编码。关于positional encoding,我也还在持续探索中。