为什么Transformer 需要进行 Multi-head Attention?

原论文中说的是,将模型分为多个头,形成多个子空间,可以让模型去关注不同方面的信息,然而仔细想想,这真的可能吗?或者说,Multi-Head的作用真的是去关注“不同方面”的特征吗?
首先,我们知道Transformer的更新公式是这样的:
Q_i=QW^Q_i,K_i=KW^K_i,V_i=VW^V_i,\quad i=1,\cdots,8\\ \text{head}_i=\text{Attention}(Q_i,K_i,V_i),\quad i=1,\cdots,8\\ \text{MultiHead}(Q,K,V)=\text{Concat}(\text{head}_1,\cdots,\text{head}_8)W^O
这里,我们假设 Q,K,V\in\mathbb{R}^{512},W^Q_i,W^K_i,W^V_i\in\mathbb{R}^{512\times 64},W^O\in\mathbb{R}^{512\times 512} ,从而, \text{head}_i\in\mathbb{R}^{64} 。
如果Multi-Head的作用是去关注句子的不同方面,那么我们认为,不同的头就不应该去关注一样的Token。当然,也有可能关注的pattern相同,但内容不同,也即 V_i 不同,这是有可能的。但是有大量的paper表明,Transformer,或Bert的特定层是有独特的功能的,底层更偏向于关注语法,顶层更偏向于关注语义。既然在同一层Transformer关注的方面是相同的,那么对该方面而言,不同的头关注点应该也是一样的。但是我们发现,同一层中,总有那么一两个头独一无二,和其他头的关注pattern不同,比如下图:
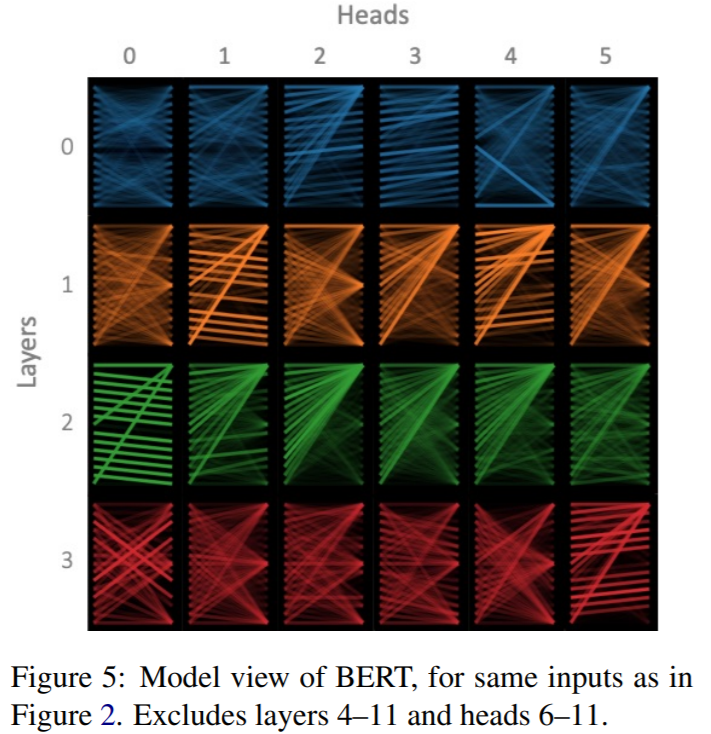

如果要说不同的头关注的方面不一样,但同一层中的多数头的关注模式是一样的(比如第3层的1234头);如果说一样吧,又总有那么一两个头与众不同(比如第2层的0头)。这种模式是很普遍的,为什么会出现这种情况?
不清楚。
我们首先来看看这个过程是怎样的。首先,所有的参数随机初始化,然后用相同的方法前传,在输出端得到相同的损失,用相同的方法后传,更新参数。在这一条线中,唯一不同的地方在于初始值的不同。设想一下,如果我们把同一层的所有参数(这里的参数都是指的W^Q_i,W^K_i,W^V_i )初始化成一样的(不同层可以不同),那么在收敛的时候,同一层的所有参数仍然是一样的,自然它们的关注模式也一样。那么,关注模型的不一样就来自于初始化的不一样。
好了,现在问题来了:
- 在一层中,不同头之间的差距有多少(用 h_i 去度量),这个差距的作用是什么?
- 同一层中,不同的头数量是否对 h_i 有影响。
- h_i 是否随着层数的变化而变化。
- 初始化如何影响 h_i 。
- 能否通过控制初始化去控制 h_i 。
如果我们能回答上面五个问题,那么Multi-head 的作用就可以得到解释。遗憾的是,现在没有专门的论文去解释上面的问题,但已经有一些文章提到了一点或几点。
比如,https://arxiv.org/pdf/1906.04341v1.pdf 实际上可视化了第一个问题的前半部分和第三个问题。如下图所示,不同的颜色代表不同的层,同一颜色的分布代表了同一层的头差距。我们可以先看看第一层,也就是深蓝色。在左边出现了一个点,右边和下边都有点出现,分布是比较稀疏的。再看看第六层浅蓝色的点,相对来说分布比较密集了。再看看第十二层,深红色,基本全部集中在下方,分布非常密集。
如果这种方法是可信的,那么我们可以推论:头之间的差距随着所在层数变大而减少。换句话说,头之间的方差随着所在层数的增大而减小。


但遗憾的是,这种差距有什么作用至今还没有得到解释。一种可能的解释是,它类似一种noise,或者dropout,而不是去关注不同的方面。也就是说,无论多少层,既然都会出现与众不同的头,那么这个(些)头就是去使得模型收敛(效果最优)的结果,反过来说,模型可能认为,全部一样的头不会使效果最优(至少在梯度下降的方法上)。这样的话,把这个(些)头解释为模型的一种“试探”,或者噪声,是可能合理的。
为此,我们可以drophead,以概率 p 随机选取一些层,再以概率 q 随机选取一些头,把它们抹掉,看看效果。
另外一种解释是,Transformer对初始化比较敏感,一些初始化点必然导致不同的头,但这样解释就很难从直觉上解释了。
另外,也有一些文章开始讨论初始化对Transformer的影响了。比如最近的https://arxiv.org/pdf/1908.11365.pdf 就讨论了初始化对Transformer各层方差的影响,最终缓解梯度消失的问题。从这个角度讲,Transformer底层的头方差大是因为Transformer存在的梯度消失问题,也就是说,并不是模型自己觉得底层的方差大是好的,而是自己没有办法让它变好。所以,合理的初始化应该可以减少底层头的方差,提高效果。


最后来看看Transformer原论文中的结果,我们主要看base那一行和(A)组。对于PPL和BLEU,确是8个头/16个头最好,1个头最差,4个和32个头稍微差一点,但是差的不多。从这里来看,head也不是越多越好或者越少越好。


================9.9更新================
在看https://arxiv.org/pdf/1909.00015.pdf的时候看到了Related Work中关于Multi-Head的一篇文章:
这篇文章探究了四个问题:
- 翻译的质量在何种程度上依赖单个头?
- 头的模型是否一致?其中对翻译最重要的是什么模式?
- 哪种Attention(encoder self-attention, decoder self-attention, encoder-decoder self-attention)对头的数量和所在层数最敏感?(这个问题我们不讨论)
- 能否去掉一些头而不失效果?
然后本文给出的结论是:
- 只有一小部分头对翻译而言是重要的,其他的头都是次要的(可以丢掉)。
- 重要的头有一种或多种专有的关注模式。
第一,作者使用了自信度和LRP(Layer-wise Relevance Propagation)来描述头的重要度。结果见图1a,1b,2a,2c。
第二,作者考虑了不同头的功能(functions)。头的功能可以分为三类:
- 关注左右的Token(紫色)
- 关注语法(绿色)
- 关注罕见词(橙色)
结果见图1c,2b,2d,3,4,5。主要结论是:
- Positional Heads和高confidence和LRP的头相符合
- 一些头的确编码了语法信息
- 在所有模型的第一层,总有一个头去关注rare words
第三,点两点表明了一些头具有一定的模式和具有可解释性,但是并没有探索头之间的关系。它们是否也有相同的模式,是否是多余的。为此,作者对头进行剪枝。
具体来说,对某一层的共h个头,作者使用图6的分布对头进行剪枝,注意这里剪枝的顺序是模型自己学习的。然后加入一个正则项 L_C(\phi)=\sum_{i=1}^h(1-P(g_i=0|\phi_i)) ,当头以高概率被剪去的时候 P(g_i=0|\phi)\approx 1 ,这个正则项的意思是所有头不被剪掉的概率和,然后用下述的目标去训练剪枝后的Transformer。在inference的时候也是用剪枝的模型。
L(\theta,\phi)=L_\text{cross-entropy}(\theta,\phi)+\lambda L_C(\phi)
- 剪枝encoder。图7展示了对encoder剪枝的结果,结果表明剪去大部分头并不会怎么影响结果,剪掉太多才会迅速破坏效果,但这可能是参数量的减少带来的。图8是剪枝后的头的作用分布,可以看到,无论头是多少,这几种功能的头分布是大致相同的,大概都是一个rare words头,2:1的语法:位置头,还有一些不明意义的头。而且,这些不明意义的头是优先被剪去的。
- 剪枝encoder和decoder。图9,10和表2展示了剪枝后的效果。


















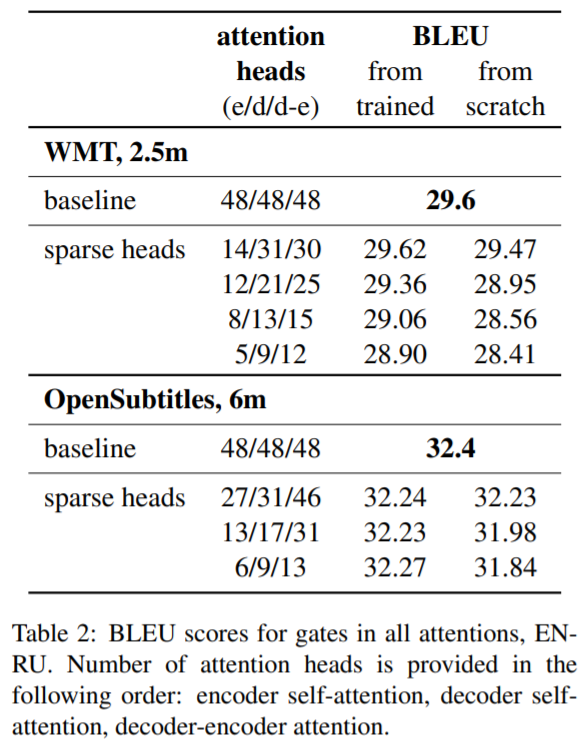

好,现在回到问题,为什么需要有Multi-Head。从这篇文章的结果来看,Multi-Head其实不是必须的,去掉一些头效果依然有不错的效果(而且效果下降可能是因为参数量下降),这是因为在头足够的情况下,这些头已经能够有关注位置信息、关注语法信息、关注罕见词的能力了,再多一些头,无非是一种enhance或noise而已。