如何评价李纪为的论文Is Word Segmentation Necessary?
9 个回答

中文分词确实是个非常有意思、也很重要的话题,这篇文章尝试抛砖引玉去探究一下这个问题,也希望这一问题获得学术界更广泛的重视。因为之前的工作,分词本身的优缺点并没有详尽地被探讨。鉴于笔者本身的局限性,文章在 intro 的结尾也提到:Instead of making a conclusive (and arrogant) argument that Chinese word segmentation is not necessary, we hope this paper could foster more discussions and explorations on the necessity of the long-existing task of CWS in the community, alongside with its underlying mechanisms.
这个问题涉及到的更本质的问题,就是语言学的structure在深度学习的框架下有多重要 (因为词是一种基本的语言学structure)。这个问题近两年学者有不同的争论,有兴趣的同学可以看 manning 和 lecun的debate https://www.youtube.com/watch?v=fKk9KhGRBdI 。更早的15年,manning 和 andrew ng 就有过讨论,当时 andrew的想法比lecun还要激进,认为如果有足够的训练数据和强有力的算法,哪怕英文都不需要word,char就够了。
附上跟 dan的邮件讨论记录。当然对于这个问题,不同学者一定会有不同的见解。
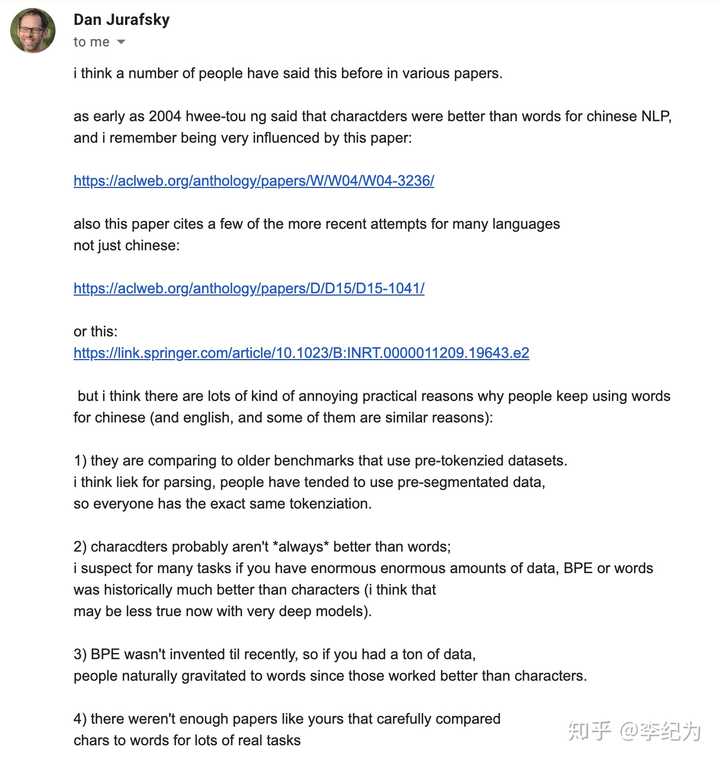



回答@Cyunsiu To 同学的问题: 另外这篇文章在分析分词不work的时候,很大一部分把不work的原因归因于oov太多,我个人不认同,至少分类动不动就能开十万+级别的词表,一方面oov不会太多,另一方面即使oov太多,也应该分析一下哪些oov导致模型不work吧,其实我个人认为根本不是oov的原因造成的。要不然英文里面的word也不会work了
回答:文章提到几个方面,OOV是其中一个方面,但并不是所有。除了OOV之外, data sparsity也是一个重要原因。从文章的图2上看,在同样的数据集上,对于不同OOV的frequency bar (意思是 frequency 小于1算作OOV,还是frequency 小于5算作OOV),实验结果是先升再降的。这个其实也比较好理解,如果frequency bar小,对于那些infrequent的词会单独认为是词,而不是OOV。因为data sparsity的问题,会使学习不充分,从而影响了效果。 从这个角度,char模型比word模型会学习得更充分。

我最近在升级分词,异常痛苦...看到这篇文章中了 ACL-2019,就简单翻了翻。
文章说得没有错,中文 NLP 中的分词确实是个非常麻烦的模块。一方面,虽然常用汉字只有2W,但分词后10W都装不下,在有限的词表容量下会产生大量的 OOV。另一方面,训练语料的量不足,又不是100%正确标注的,再加上歧义和新词,导致分词效果堪忧。
char-model 比 word-model,确实可以避免上述两个问题。根据论文结果,char > sub-word > word。
个人认为,在工业界 sub-word 仍然是最优选择。并不是不再分词,而是用更小的粒度来换取更广的覆盖。
一方面,char-model 会导致序列成倍地变长,decoder 场景下严重拖慢计算速度;
另一方面,大多数的实际应用,都依赖“词汇”作为有独立语义的实体,来完成关键词类的功能;
最后,sub-word 已经显著地缓解了 OOV的问题。其他的词太长尾,实际应用并不关心。