主流的垃圾回收机制都有哪些?
45 个回答

前面有不少回答了,其中有部分靠谱的内容,感觉要补充也挺麻烦的,俺就放个俺推荐的书单吧:
[Garbage Collection][垃圾回收][自动无用内存单元回收]相关读物《The Garbage Collection Handbook》非常开眼界,能完美回答题主的问题。
不想买书的话从这个网站开始学习也行:
Introduction to memory management也欢迎关注这个HLLVM群组的论坛,
高级语言虚拟机我以前发过一些帖,例如说介绍copying GC的基础实现:
HotSpot VM Serial GC的一个问题以及G1 GC的实现:
[HotSpot VM] 请教G1算法的原理以及几种GC的比较:
并发垃圾收集器(CMS)为什么没有采用标记引用计数与tracing GC的讨论俺也就放个传送门好了:
垃圾回收机制中,引用计数法是如何维护所有对象引用的? - RednaxelaFX 的回答=======================================================
另外对问题描述吐个槽:
无意中看到JavaScript V8和Python中也是使用引用计数和标记清除作为垃圾回收的基础方法,想问问 是否还有其他的垃圾回收算法?
(C)Python是用引用计数为主、mark-sweep为备份没错。
但是V8的GC并不是单纯基于mark-sweep的。
最初发布的时候,V8还比较简单,采用分两代的GC,其中new space用copying GC,然后global GC根据碎片化状况选择性使用mark-sweep或mark-compact。
其抽象思路可以看这个入口函数:
v8/mark-compact.cc at 0.1 · v8/v8 · GitHubvoid MarkCompactCollector::CollectGarbage() {
Prepare();
MarkLiveObjects();
SweepLargeObjectSpace();
if (compacting_collection_) {
EncodeForwardingAddresses();
UpdatePointers();
RelocateObjects();
RebuildRSets();
} else {
SweepSpaces();
}
Finish();
}
后来V8逐渐进化,GC的实现越来越复杂。目前的默认实现是new space还是用copying GC,而global GC则默认用incremental marking + lazy sweeping为主,mark-compact为备份。

看大家科普差不多了,我来个角度刁钻的
python的垃圾收集,你能找到的资料几乎都说是引用计数+标记清除
但是这个“标记清除”跟一般的标记清除还是有点差别的,全名是“局部标记清除”,它基于引用计数
这个算法最早好像是出现在fortran,虽然流程都是“确定根集合->标记->清除”,但是和普通MS算法不同的是,第一步确定根集合是基于引用计数来做的,它不是以“栈、全局变量”之类的东西作为根集合起点,而是随便给个堆上对象的集合都可以根据引用计数算出这个集合的“根”,也就是说根本不需要跟踪或扫描栈和全局区域
具体做法也很简单:对于任何对象集合,我们先弄个表存它们的引用计数的副本,然后把内部引用都拆掉,所谓内部引用是指这个集合中的某个对象引用了另一个本集合内部的对象,拆的过程中减少引用计数,当然是在副本表里面减少
全部拆除后,引用计数依然不为0的,就是根集合,然后开始标记过程,标记其实不需要任何染色,只要逐步恢复引用并增加副本表的引用计数即可
最后,副本表中引用计数为0的,就是垃圾
例如:
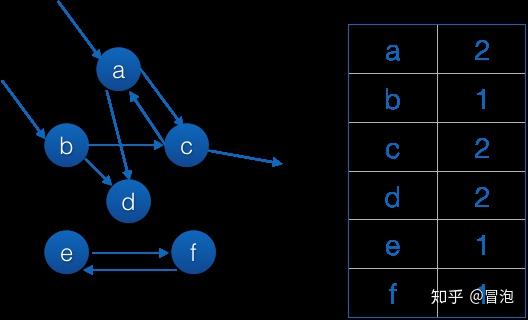

随便抽出6个对象作为一个集合,这个集合有外部进来的连接(到a和b),也有到外部的连接(c引用了外面某个对象),但这个都无所谓,重要的是其内部连接,右边是引用计数表,然后我们拆掉所有内部连接:
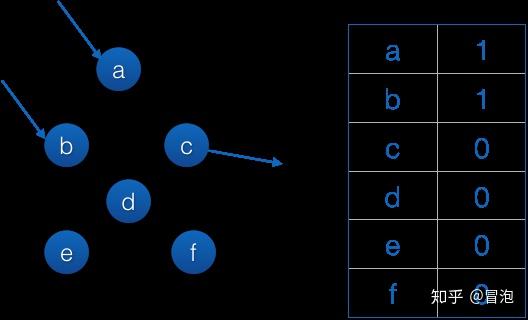

根集合就是a和b了,然后我们开始标记并恢复引用计数:
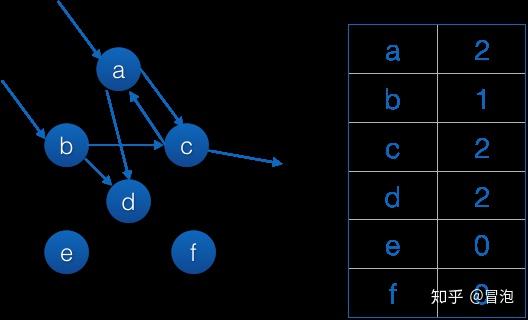

从a和b出发可达的都被回复了,引用计数还是0的就是这个集合内部循环引用的垃圾(e和f)
如果你把所有对象看做一个集合,那么这个算法每次都可以回收所有垃圾,当然,性能是另码事
你也可以将对象划分为一个个小的集合,分别来回收,但这时候的效果就取决于你是否能尽量将循环引用的垃圾划分到每个集合中,集合划分粒度越粗,回收效果越好,但是速度越慢,反之亦然
python的做法是分代,每一代作为一个集合,其他语言的GC中的分代需要额外记录各代之间的引用,但是python基于引用计数,反而不需要了
当然,再说一句,性能是另码事……
=================
补充:这个算法作为引用计数的补充,最大好处就是不需要runtime环境支持栈和全局空间的扫描,譬如说,你在C++中用智能指针配合自己写的对象申请和释放器,理论上讲是可以解决循环引用问题而不需要关心栈和全局区的“根集合”,这样就算智能指针和普通手工申请释放两种机制混合用也没问题,唯一麻烦的地方是,你需要对每个shared_ptr维护的对象实现遍历引用和标记。另一个好处是,虽然你的代码有很多类都会用引用计数来维护,但并不是每个类都是容器类,而非容器类的对象显然不可能出现循环引用,单纯的引用计数就足够了,因此上面算法仅针对容器即可
更进一步地,如果上面这些用一个编译器分析处理,还可以分析出那些类是会进入引用计数管理,给这些类自动生成标记清除的相关方法代码,以及进一步分析哪些类可能形成循环引用,哪些不可能形成,最终这个算法只需要处理必要的类型的对象即可