数据挖掘中常见的「异常检测」算法有哪些?
72 个回答

一般情况下,可以把异常检测看成是数据不平衡下的分类问题。因此,如果数据条件允许,优先使用有监督的异常检测[6]。实验结果[4]发现直接用XGBOOST进行有监督异常检测往往也能得到不错的结果,没有思路时不妨一试。
而在仅有少量标签的情况下,也可采用半监督异常检测模型。比如把无监督学习作为一种特征抽取方式来辅助监督学习[4,8],和stacking比较类似。这种方法也可以理解成通过无监督的特征工程对数据进行预处理后,喂给有监督的分类模型。
但在现实情况中,异常检测问题往往是没有标签的,训练数据中并未标出哪些是异常点,因此必须使用无监督学习。从实用角度出发,我们把文章的重点放在无监督学习上。
本文结构如下:1. 介绍常见的无监督异常算法及实现; 2. 对比多种算法的检测能力; 3. 对比多种算法的运算开销; 4. 总结并归纳如何处理异常检测问题。5. 代码重现步骤。
1. 无监督异常检测
如果归类的话,无监督异常检测模型可以大致分为:
- 统计与概率模型(statistical and probabilistic and models):主要是对数据的分布做出假设,并找出假设下所定义的“异常”,因此往往会使用极值分析或者假设检验。比如对最简单的一维数据假设高斯分布,然后将距离均值特定范围以外的数据当做异常点。而推广到高维后,可以假设每个维度各自独立,并将各个维度上的异常度相加。如果考虑特征间的相关性,也可以用马氏距离(mahalanobis distance)来衡量数据的异常度[12]。不难看出,这类方法最大的好处就是速度一般比较快,但因为存在比较强的“假设”,效果不一定很好。稍微引申一点的话,其实给每个维度做个直方图做密度估计,再加起来就是HBOS。
- 线性模型(linear models):假设数据在低维空间上有嵌入,那么无法、或者在低维空间投射后表现不好的数据可以认为是离群点。举个简单的例子,PCA可以用于做异常检测[10],一种方法就是找到k个特征向量(eigenvector),并计算每个样本再经过这k个特征向量投射后的重建误差(reconstruction error),而正常点的重建误差应该小于异常点。同理,也可以计算每个样本到这k个选特征向量所构成的超空间的加权欧氏距离(特征值越小权重越大)。在相似的思路下,我们也可以直接对协方差矩阵进行分析,并把样本的马氏距离(在考虑特征间关系时样本到分布中心的距离)作为样本的异常度,而这种方法也可以被理解为一种软性(Soft PCA) [6]。同时,另一种经典算法One-class SVM[3]也一般被归类为线性模型。
- 基于相似度衡量的模型(proximity based models):异常点因为和正常点的分布不同,因此相似度较低,由此衍生了一系列算法通过相似度来识别异常点。比如最简单的K近邻就可以做异常检测,一个样本和它第k个近邻的距离就可以被当做是异常值,显然异常点的k近邻距离更大。同理,基于密度分析如LOF [1]、LOCI和LoOP主要是通过局部的数据密度来检测异常。显然,异常点所在空间的数据点少,密度低。相似的是,Isolation Forest[2]通过划分超平面来计算“孤立”一个样本所需的超平面数量(可以想象成在想吃蛋糕上的樱桃所需的最少刀数)。在密度低的空间里(异常点所在空间中),孤例一个样本所需要的划分次数更少。另一种相似的算法ABOD[7]是计算每个样本与所有其他样本对所形成的夹角的方差,异常点因为远离正常点,因此方差变化小。换句话说,大部分异常检测算法都可以被认为是一种估计相似度,无论是通过密度、距离、夹角或是划分超平面。通过聚类也可以被理解为一种相似度度量,比较常见不再赘述。
- 集成异常检测与模型融合:在无监督学习时,提高模型的鲁棒性很重要,因此集成学习就大有用武之地。比如上面提到的Isolation Forest,就是基于构建多棵决策树实现的。最早的集成检测框架feature bagging[9]与分类问题中的随机森林(random forest)很像,先将训练数据随机划分(每次选取所有样本的d/2-d个特征,d代表特征数),得到多个子训练集,再在每个训练集上训练一个独立的模型(默认为LOF)并最终合并所有的模型结果(如通过平均)。值得注意的是,因为没有标签,异常检测往往是通过bagging和feature bagging比较多,而boosting比较少见。boosting情况下的异常检测,一般需要生成伪标签,可参靠[13, 14]。集成异常检测是一个新兴但很有趣的领域,综述文章可以参考[16, 17, 18]。
- 特定领域上的异常检测:比如图像异常检测 [21],顺序及流数据异常检测(时间序列异常检测)[22],以及高维空间上的异常检测 [23],比如前文提到的Isolation Forest就很适合高维数据上的异常检测。
不难看出,上文提到的划分标准其实是互相交织的。比如k-近邻可以看做是概率模型非参数化后的一种变形,而通过马氏距离计算异常度虽然是线性模型但也对分布有假设(高斯分布)。Isolation Forest虽然是集成学习,但其实和分析数据的密度有关,并且适合高维数据上的异常检测。在这种基础上,多种算法其实是你中有我,我中有你,相似的理念都可以被推广和应用,比如计算重建误差不仅可以用PCA,也可以用神经网络中的auto-encoder。另一种划分异常检测模型的标准可以理解为局部算法(local)和全局算法(global),这种划分方法是考虑到异常点的特性。想要了解更多异常检测还是推荐看经典教科书Outlier Analysis [6],或者综述文章[15]。
虽然一直有新的算法被提出,但因为需要采用无监督学习,且我们对数据分布的有限了解,模型选择往往还是采用试错法,因此快速迭代地尝试大量的算法就是一个必经之路。在这个回答下,我们会对比多种算法的预测能力、运算开销及模型特点。如无特别说明,本文中的图片、代码均来自于开源Python异常检测工具库Pyod。文中实验所使用的17个数据集均来自于(ODDS - Outlier Detection DataSets)。
本文中所对比的算法(详见PyOD介绍(英文)):
- PCA [10]
- MCD: Minimum Covariance Determinant [11, 12]
- OCSVM: One-Class Support Vector Machines [3]
- LOF: Local Outlier Factor [1]
- kNN: k Nearest Neighbors [19, 20]
- HBOS: Histogram-based Outlier Score [5]
- FastABOD: Fast Angle-Based Outlier Detection using approximation [7]
- Isolation Forest [2]
- Feature Bagging [9]
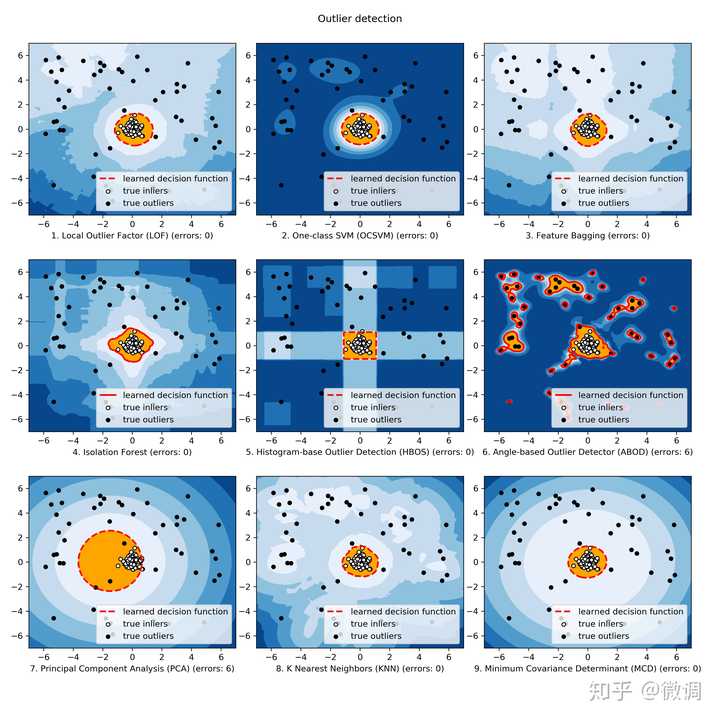
先来看一下这九种算法在人工生成的数据上的表现(正常点由高斯分布生成,异常点由均匀生成)。在这种简单数据上,我们发现大部分算法的表现都不错,值得关注的有几点:
- PCA(图7)和MCD(图9)的决策边界(decision boundary)非常相似,我们前文提到过,协方差矩阵可以看做是PCA的软性版本。其实线性模型的决策边界都有共性,图2中的one-class SVM和PCA及MCD的决策边界长得也差不多。而且你会发现这些线性模型的形成的可视化是一圈一圈向外降低的,这恰恰是因为对于数据分布假设的原因。
- HBOS(图5)的分类边界像是多个长方形组合在一起。这和它的原理有关,HBOS全称Histogram-based outlier score,它假设每个维度独立并在每个维度上划分n个区间,每个区间所对应的异常值取决于密度。密度越高,异常值越低,因此也可以看成是一种假设维度独立的密度检测。一定程度上,HBOS和Isolation Forest有一定的相似性,看Isolation Forest(图4)很像是一种加了随机性的HBOS(有相似处但不是)。
- ABOD(图6)中的决策边界非常复杂,显然存在一定程度上的过拟合,效果也不是太好,具体原因我们稍后再分析。
通过这个toy example我们想给大家看一下算法间的联系。

2. 模型检测效果
我们采用ROC和Precision@Rank n(prn)作为衡量标准。ROC大家很熟悉了,而后者指的是在假设有n个异常点时的精度(precision),和推荐系统中的precision @k 是一样的。异常检测因为数据不平衡,一般不适合用准确度(误分率)来进行评估。
在下面的结果图表中,最优(次优)模型均用黑体加粗,最差用红色字体标出。


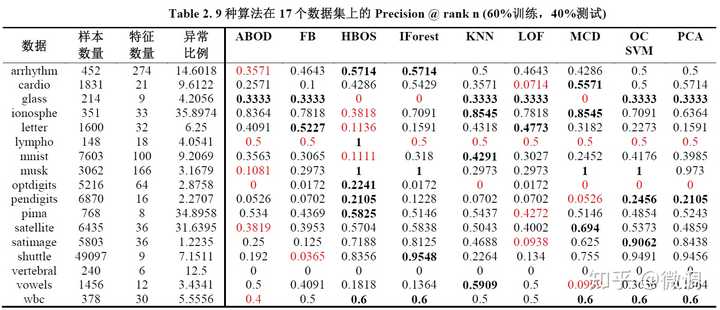

对以上结果进行初步分析:
- 总体来看,没有任何模型表现持续最好。Isolation Forest和KNN的表现非常稳定,分别在ROC和PRN上有比较优秀的表现。
- KNN等模型基于距离度量,因此受到数据维度的影响比较大,当维度比较低时表现很好。如果异常特征隐藏在少数维度上时,KNN和LOF类的效果就不会太好,此时该选择Isolation Forest。
- 部分模型较不稳定,受到数据变化的影响较大,如HBOS在8个数据上表现优异,但也在3个数据上变现最差。
- 简单模型的表现不一定差,比如KNN和MCD的原理都不复杂,但表现均不错。
- ABOD综合来看效果最差,应该避免。这个实验中所用的ABOD版本是FastABOD并用10个近邻进行近似,可能精准版的ABOD效果会好一些,但运算复杂度会大幅度上升(O(n^3))。
3. 模型运算开销
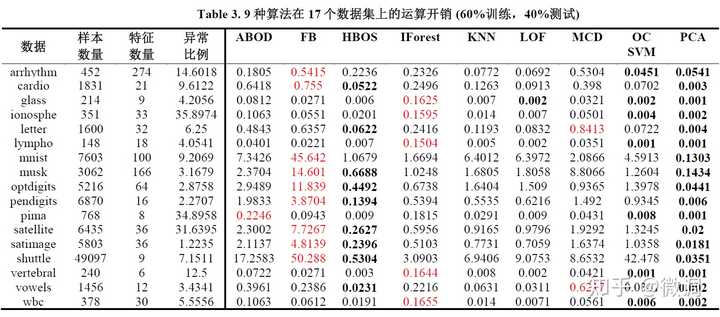

结合分析模型的运算开销,我们可以得到一些结论:
- Feature Bagging的运算开销很高,这个是可以理解的,因为它训练了10个LOF作为子模型,可以观察一下它的速度差不多比LOF慢十倍。但值得注意的是Feature Bagging其实是一个模型框架,子模型可以用任何模型,比如HBOS等,因此效果可以提升。
- HBOS和PCA的运算效率都很高,这个主要是因为模型比较简单。但也要值得注意PCA中需要逆矩阵,随着维度增加或者实现不够高效可能很慢,所以和工具库的实现方法关系很大。同理,MCD和PCA虽然比较相似,但前者比后者慢很多。
- LOF和KNN的表现相近,运算开销都相对较高,但在中小数据集上基本可以忽略这一点。
- Isolation Forest的表现较差,但这个并不意外,因为我们测试的主要是中小数据集。随着数据量和维度的上升,Isolation Forest会比较有优势。
- ABOD的运算效率很低,大部分情况下比KNN和LOF还慢,应该避免。
4. 总结
首先我们要意识到这个实验的局限性:
- 选用的数据集普遍偏小(最大的不过50000条数据),因此不能完全反应出在极大数据量下的情况,比如Isolation Forest更适合的高维空间。我们也没有测试稀疏数据上的表现,这个有待验证。
- 为了实验的可重复性,固定了训练集和测试集(random_state=42)。但考虑到准确性,应该随机多次划分数据并求平均。
- 测试的模型有限,如果Pyod中引进了新的模型会更新这个结果。
- 算法的实现基础各不相同,比如有的底层是用C实现并经过优化,有的模型未经优化,因此比较起来可能不大公平。
- 所有模型均未调参,均是模型实现中的默认值。可能部分模型在经过精调以后有卓越的效果。
但即使这样,实验结果也带来很多异常检测模型选择时的思路:
- 不存在普遍意义上的最优模型,但有不少模型比较稳定,建议中小数据集上使用KNN或者MCD,中大型数据集上使用Isolation Forest。
- 模型效果和效率往往是对立的,比如PCA和MCD原理相似,但前者很快却效果一般,后者较慢但效果更好,因为后者比前者所考虑计算的更多,前者可以被认为是后者的简化版本。
- 因为异常检测往往是无监督的,稳定有时候比忽高忽低的性能更重要。所以即使HBOS运算速度很快,但因为效果时好时坏依然不是首选。
- 简单的模型不一定表现不好,比如KNN和MCD都属于非常简单的模型,但表现出众。
所以面对一个全新的异常检测问题,我个人认为可以遵循以下步骤分析:
- 我们对于数据有多少了解,数据分布是什么样的,异常分布可能是什么样的。在了解这点后可根据假设选择模型。
- 我们解决的问题是否有标签,如果有的话,我们应该优秀使用监督学习来解决问题。标签信息非常宝贵,不要浪费。
- 如果可能的话,尝试多种不同的算法,尤其是我们对于数据的了解有限时。
- 可以根据数据的特点选择算法,比如中小数据集低维度的情况下可以选择KNN,大数据集高维度时可以选择Isolation Forest。如果Isolation Forest的运算开销是个问题的话,也可以试试HBOS,在特征独立时可能有奇效。
- 无监督异常检测验证模型结果并不容易,可以采用半自动的方式:置信度高的自动放过,置信度低的人工审核。
- 意识到异常的趋势和特征往往处于变化过程中。比如明天的欺诈手段和今天的可能不同,因此需要不断的重新训练模型及调整策略。
- 不要完全依赖模型,尝试使用半自动化的策略:人工规则+检测模型。很多经验总结下来的人工规则是很有用的,不要尝试一步到位的使用数据策略来代替现有规则。
5. 复现实验步骤(可选)
1. 文中toy example的实验均直接取自开发者的Github(代码,Jupyter Notebooks)。
2. 文中的对比实验也来自于开发者的Github(Jupyter Notebooks)。
3. 开发者提供了在线Jupyter Notebooks可以直接运行,无需安装(但我发现比较慢),步骤:
- 点击Binder (beta)
- 等待Notebook初始化和载入,大概需要3-5分钟左右。
- 之后会默认进入根目录,有docs,examples,notebooks等文件夹,进入notebooks文件夹:
- 运行 Compare All Models.ipynb
- 运行 Benchmark.ipynb
运行过程中遇到问题可以在Github上像开发者提issue,而本文只是工具库及实验的使用和总结,具体内容请像开发者咨询。
[1] Breunig, M.M., Kriegel, H.P., Ng, R.T. and Sander, J., 2000, May. LOF: identifying density-based local outliers. In ACM SIGMOD Record, pp. 93-104. ACM.
[2] Liu, F.T., Ting, K.M. and Zhou, Z.H., 2008, December. Isolation forest. In ICDM '08, pp. 413-422. IEEE.
[3] Ma, J. and Perkins, S., 2003, July. Time-series novelty detection using one-class support vector machines. In IJCNN' 03, pp. 1741-1745. IEEE.
[4] Micenková, B., McWilliams, B. and Assent, I. 2015. Learning Representations for Outlier
Detection on a Budget. arXiv Preprint arXiv:1507.08104.
[5] Goldstein, M. and Dengel, A., 2012. Histogram-based outlier score (hbos): A fast unsupervised anomaly detection algorithm. InKI-2012: Poster and Demo Track, pp.59-63.
[6] Aggarwal, C.C., 2015. Outlier analysis. InData mining(pp. 237-263). Springer, Cham.
[7] Kriegel, H.P. and Zimek, A., 2008, August. Angle-based outlier detection in high-dimensional data. InKDD '08, pp. 444-452. ACM.
[8] Zhao,Y. and Hryniewicki, M.K. 2018. XGBOD: Improving Supervised Outlier Detection
with Unsupervised Representation Learning. IJCNN. (2018).
[9] Lazarevic, A. and Kumar, V., 2005, August. Feature bagging for outlier detection. In KDD '05. 2005.
[10] Shyu, M.L., Chen, S.C., Sarinnapakorn, K. and Chang, L., 2003. A novel anomaly detection scheme based on principal component classifier. MIAMI UNIV CORAL GABLES FL DEPT OF ELECTRICAL AND COMPUTER ENGINEERING.
[11] Rousseeuw, P.J. and Driessen, K.V., 1999. A fast algorithm for the minimum covariance determinant estimator. Technometrics, 41(3), pp.212-223.
[12] Hardin, J. and Rocke, D.M., 2004. Outlier detection in the multiple cluster setting using the minimum covariance determinant estimator. Computational Statistics & Data Analysis, 44(4), pp.625-638.
[13] Rayana, S. and Akoglu, L. 2016. Less is More: Building Selective Anomaly Ensembles. TKDD. 10, 4 (2016), 1–33.
[14] Rayana, S.,Zhong, W. and Akoglu, L. 2017. Sequential ensemble learning for outlier
detection: A bias-variance perspective. ICDM. (2017), 1167–1172.
[15] Chandola, V., Banerjee, A. and Kumar, V., 2009. Anomaly detection: A survey.ACM computing surveys, 41(3), p.15.
[16] Aggarwal, C.C., 2013. Outlier ensembles: position paper. ACM SIGKDD Explorations Newsletter, 14(2), pp.49-58. [Download PDF]
[17] Zimek, A., Campello, R.J. and Sander, J., 2014. Ensembles for unsupervised outlier detection: challenges and research questions a position paper. ACM Sigkdd Explorations Newsletter, 15(1), pp.11-22.
[18] Aggarwal, C.C. and Sathe, S., 2017.Outlier ensembles: an introduction. Springer.
[19] Ramaswamy, S., Rastogi, R. and Shim, K., 2000, May. Efficient algorithms for mining outliers from large data sets. ACM Sigmod Record, 29(2), pp. 427-438).
[20] Angiulli, F. and Pizzuti, C., 2002, August. Fast outlier detection in high dimensional spaces. In European Conference on Principles of Data Mining and Knowledge Discovery pp. 15-27.
[21] Akoglu, L., Tong, H. and Koutra, D., 2015. Graph based anomaly detection and description: a survey.Data Mining and Knowledge Discovery, 29(3), pp.626-688.
[22] Gupta, M., Gao, J., Aggarwal, C.C. and Han, J., 2014. Outlier detection for temporal data: A survey.IEEE Transactions on Knowledge and Data Engineering, 26(9), pp.2250-2267.
[23] Zimek, A., Schubert, E. and Kriegel, H.P., 2012. A survey on unsupervised outlier detection in high‐dimensional numerical data.Statistical Analysis and Data Mining: The ASA Data Science Journal, 5(5), pp.363-387.


最近在组内做了一个异常检测的技术分享,搜集了一些关于异常检测资料,所以在这里贴一下这些参考资料。
这个repo很给力,作者给了很多的论文资料,工具,数据集,领域会议等等,作者应该是专业搞异常检测的,我看18年还发了两篇论文,而且最重要的,还把异常检测一些基本方法的封装成了python包pyod,很牛掰了,非常感谢他的分享
https://github.com/yzhao062/anomaly-detection-resources (包括基本的异常检测算法)
pyod: https://pyod.readthedocs.io/en/latest/
还有一些我做ppt时的参考
https://zhuanlan.zhihu.com/p/30169110
https://www.youtube.com/watch?v=5vrY4RbeWkM&t=981s
https://www.youtube.com/watch?v=5vrY4RbeWkM&t=118s
https://www.safaribooksonline.com/library/view/strata-hadoop/9781491976166/video301647.html
https://www.youtube.com/watch?v=12Xq9OLdQwQ&t=2971s
时间序列异常检测:
https://blog.statsbot.co/time-series-anomaly-detection-algorithms-1cef5519aef2
https://www.xenonstack.com/blog/data-science/anomaly-detection-time-series-deep-learning/
https://www.xenonstack.com/blog/data-science/time-series-forecasting-machine-deep-learning/
异常检测工具的汇总: