XGBoost做分类问题时每一轮迭代拟合的是什么?

先说结论,拟合的是概率值。
XGBoost是GBDT的升级版,下面用GBDT来说明处理分类问题时,每一轮迭代的是什么。
XGBoost和GBDT均是基于CART回归树,对GBDT来说,当预测值为连续值时,计算预测值与真实值之间距离的平方和,均方误差(MSE)是最常用的回归损失函数,此时负梯度刚好是残差,当预测值为离散值,或者说处理分类问题时,拟合的也是‘负梯度’,只是要转一道弯。
这道弯是将预测值和真实值转换为类别的概率,迭代过程就是让预测概率不断接近真实概率。
对数损失logloss常用于评估分类器的概率输出,对数损失通过惩罚错误的分类,实现对分类器准确度(Accuracy)的量化。 最小化对数损失基本等价于最大化分类器的准确度。为了计算对数损失,分类器必须提供对输入的所属的每个类别的概率值,不只是最可能的类别。
下面以一个简单二分类为例,选取损失函数为logloss:
L(y_{i},F_{m}(x_{i}))=-(y_{i}logp_{i}+(1-y_{i})log(1-p_{i}) )
其中:
p_{i}=\frac{1}{1+e^{-F_{m(x_{i})}}}
代入后可得:
L(y_{i},F_{m}(x_{i}))=-(y_{i}F_{m(x_{i})}-log(1+e^{F_{m(x_{i})}}))
负梯度在下图可见:


截图来源:Jerome H. Friedman的《Greedy Function Approximation:A Gradient Boosting Machine》
以一个简单的数据集来说明第一步和第二步拟合的是什么。
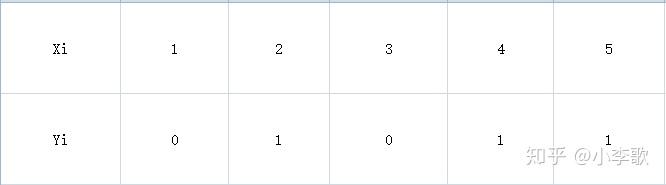

Yi的取值是0,1,其中0和1亦可以表示样本取正值的真实概率,第一步所有样本未分裂,是一个树桩,让损失函数最小,初始化可得:
F_{0(x)}=0.5*log(\frac{\sum_{1}^{N}{y_{i}}}{\sum_{1}^{N}{(1-y_{i})}}) = 0.5*log1.5 =0.088
第一棵树,当m=1时,计算负梯度 \tilde{y_{i}}=y_{i}-\frac{1}{1+e^{-F_{0(x_{i})}}} = y_{i}-0.522
可得:
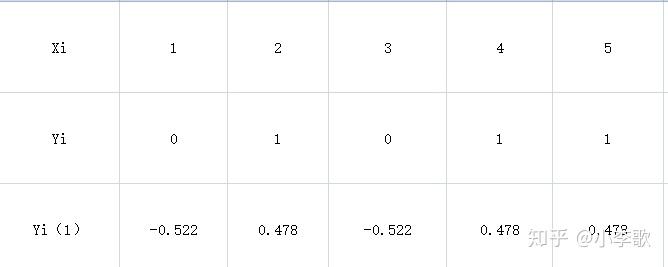

接着,会以 y_{i}(1) 为目标,拟合一颗树。

