小目标检测问题中“小目标”如何定义?其主要技术难点在哪?有哪些比较好的传统的或深度学习方法?

手机码字,格式可能有点不好看。
我们来看 MS COCO 数据集是怎么定义小目标的:
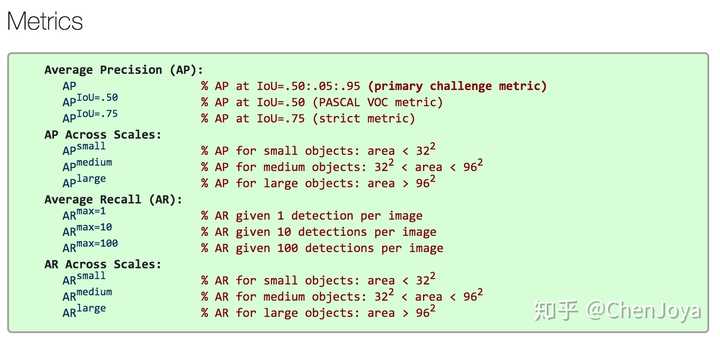

可以看到,对于面积小于 32*32 的物体,MS COCO 就认为它是一个小物体,在评测时,会对这个范围的物体计算 APsmall。
如果你有观察过 state-of-the-art 检测器中关于物体大小 AP 的 report,就会发现 APsmall 永远是最小的那个。目前很少有能在这一项上超过 30 的检测器,而相比起来,APlarge 能够达到 APsmall 的两倍左右。
有大量论文专门讨论以及提升检测器对于小物体的识别能力。为什么对于小物体的检测会这么重要呢?以自动驾驶为例,有许多小的障碍物很难用激光雷达探测到,这个时候就需要计算机视觉的帮助。
如何提升小物体的检测能力?有几个很精彩的讨论贴:
我们可以把方法归类:
(1)scale。最简单粗暴的方法就是放大图片。这就是在尺度上做文章,如FPN(Feature Pyramid Network),SNIP(An Analysis of Scale Invariance in Object Detection – SNIP)都是在做尺度的事情。特征图的分辨率 stride 的设置也算在这个里面。另,如果图像尺寸特别大,可以考虑 YOLT(You only look twice)中切图的方法。
(2)context。小物体需要有更多的周边信息来帮助识别,如何利用这些信息,two stage 可以从 ROI Pooling 上下手,另也有 Jifeng Dai 老师的 Relation Network for Object Detection。
(3)anchor。回归的好不如预设的好,S3FD 做了非常细致的 anchor 的实验,可以帮助我们更合理地设计anchor。
(4)matching strategy。对于小物体不设置过于严格的 IoU threshold,或者借鉴 Cascade R-CNN 的思路。
事实上,单单对于 MS COCO 而言,检测小目标的难点主要就在于定位。在严格的 IoU 段(指 AP75 到 AP95 这一段),小物体在这上面的分数是非常非常低的。
那么,有一个十分简单的方法可以提升小物体的精度,那就是为 bounding box regression 这项损失上,加一个针对于小物体的权重。
以 YOLOv3 为例,默认对于 regression 损失都会上一个 (2-w*h) 的损失,w 和 h 分别是ground truth 的宽和高。如果不减去 w*h,AP 会有一个明显下降。如果继续往上加,如 (2-w*h)*1.5,总体的 AP 还会涨一个点左右(包括验证集和测试集)。当然这大概也有 COCO 中小物体实在太多的原因。
欢迎补充交流指正错误;)