哈希表、字典、二维数组的区别是什么?
14 个回答


哈希表可以理解为一维数组。因为只是单一的坐标。当然如果考虑到哈希碰撞,理解为二维数组也无不可。
至于下标1跟10001,这个问题很好。你观察到了,这样的数组会有大量的空洞。这是一种常见的现象。
一维的这种数组叫做稀疏数组,二维的这种数组叫做稀疏矩阵。而对稀疏数组跟稀疏矩阵都有专门的保存算法。
从数学角度,哈希表可能是个稀疏数组,或者如果你认为它是二维的话,那就是个稀疏矩阵,如果这样的话,在存取时,它往往需要用专门的办法优化其存储占用。
不过,在实际的工程中,一个好的散列函数会尽可能的让其存储均匀分布,不褪变成稀疏数组而是保持成为普通数组,如此一来,可以通过选择良好的散列函数避免存储稀疏数组的开销,这也算是散列函数选择的技巧了。

现在给你一个班级所有人的名字和期末考试成绩,现在让你写一个程序能够查询班级中一个人在班级里考试的排名(成绩降序)。这时你就能想到一个方法:将成绩和名字作为键值对存到一个数组里,然后按照成绩降序排序,再按照某种方式把名字作为下标,存入其所对应的排名存进去。代码的话大概是这个样子:
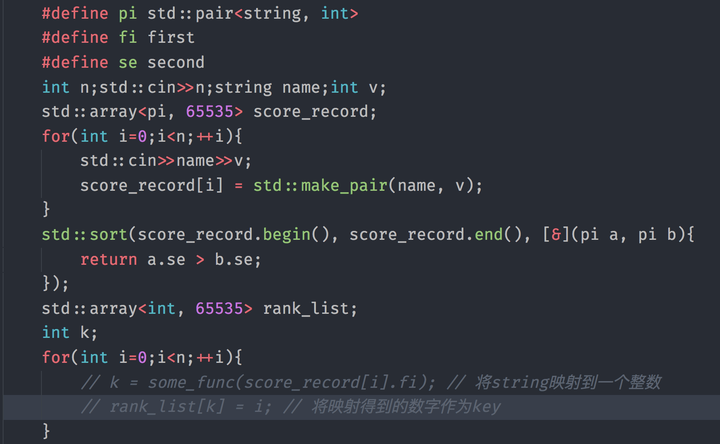

至于some_func()这个Hash函数如何实现这里不进行讨论,我们主要关注得到Hash之后的故事。这时题主可能会发现一个问题,现在这个rank_list最多能够存储65535组K-V对,因此some_func()在最后一定会为了防止下标越界,返回Hash值对小于等于65535的数取模的结果(不考虑这个模数是不是好的选择的话) 。这时问题来了:如果score_record中的元素数量比65535还大怎么办?一定会在某次记录数据的时候出现要存入的位置已经有数据了(这被称为哈希碰撞 Hash Collision)。这时,扩大array存储元素的数量在数据不大的情况下确实是个办法,但是如果数据到了亿级别,就要另外考虑方法了。一种解决办法就是将rank_list开成二维的:std::array<std::array<pi, 65535>, 65535> rank_list;这样一来,如果遇到碰撞,我们只需要在这个Hash所对应的列表后面添加一个新元素并记录一下新元素对应的name(Hash相同,Hash之前的数据不一定相同)即可(存在pair里)。
但是仔细想想,这和直接将rank_list开成65535*65535在内存方面没有任何区别...只不过变成了二维的。那么有什么方法能够很好的解决内存的问题呢?回想一下《数据结构》这本书所讲的第一个数据结构——链表。这个就是为了解决变长列表存储的一个线性数据结构,因此我们可以将rank_list改为std::array<linkedlist<pi>, 65535>,每次添加元素就在Hash之后所对下标的链表添加一个元素即可。这就是哈希表解决哈希冲突的一种方式。可以看出,哈希表的作用就是将一些键值对映射到一个数组中,在这种实现方式下比二维数组更省内存。题主提到的两个Key计算出来的Hash中间空着很多slot肯定会有的,因为哈希表就是这种空间换时间的数据结构。但是更简单地来讲,一个简单的映射就可以被看做是哈希:例如最短路算法中用于记录某个结点是否被访问过(vis数组) 就是Hash思想的一种体现; BFS(广度优先搜索)中记录某个状态是否被访问过也是一种Hash。Generally: 哈希表和二维数组做哈希,时间复杂度上区别不大,但是二维数组更消耗内存; 哈希表是基于数组实现的
题主所说的字典,如果是Python中的字典的话,本质上就是哈希,但是PyDict的Hash是开放寻址法解决哈希碰撞(遇到碰撞继续哈希直到找到空slot),这种方法能够最大化利用一个哈希表的空槽位(这里没有链表,只有一个一维数组)。
C++中有一个map可以作为字典使用,但是map的实现和哈希表有本质上的区别:map是用平衡树实现的;map中所存储的Key必须是comparable的数据类型(或被指定用于compare的函数 / 重载运算符),这是因为在旋转(防止退化成链)的时候要比较Key的大小。这种实现方式比哈希表节省空间,但是在查询时更耗时。哈希表在理想情况 / 平均下可以 O(1) 查询,但C++中的map 由于是平衡树实现的,因此均摊查询复杂度是 O(logn) ....所以STL中的字典速度是要比哈希表慢的...