学习java应该如何理解反射?
93 个回答

针对题主,重新修改下答案!首先看书要理解反射,很难完全理解,这关系到Java的语言特性,jvm的内存细节,当初我看反射,就像高票答案那样,照着写一遍,结果是你并没有理解,你只是照猫画虎,要想真正理解,我建议题主,不断深入探究,当你踩得足够深回过头来,你会柳暗花明!
这里我不打算像别的答案上来就上代码,给你讲怎么用,是啥是啥,老实说那样比较像培训java程序员的感觉,一点对知识的好奇心都没有,如果是想速成反射的,大家看别的答案吧。
写答案,可能会有默认知识现象,就是有些知识点,我知道,但你不知道,可以评论!这里我试着简单粗暴地解释一波!
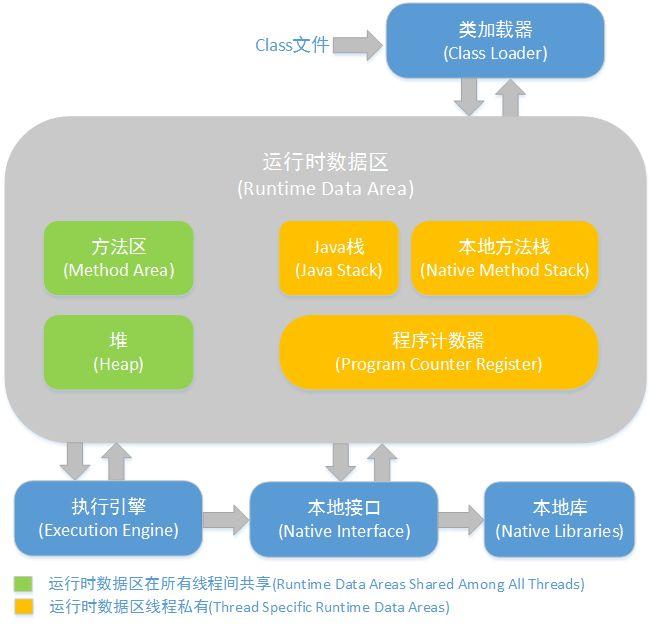

首先我们了解一下JVM,什么是JVM,Java的虚拟机,java之所以能跨平台就是因为这个东西,你可以理解成一个进程,程序,只不过他的作用是用来跑你的代码的。上图是java的内存模型,我们关注的点,一个方法区,一个栈,一个堆,初学的时候老师不深入的话只告诉你java的内存分为堆和栈,易懂点吧!
假如你写了一段代码:Object o=new Object();
运行了起来!
首先JVM会启动,你的代码会编译成一个.class文件,然后被类加载器加载进jvm的内存中,你的类Object加载到方法区中,创建了Object类的class对象到堆中,注意这个不是new出来的对象,而是类的类型对象,每个类只有一个class对象,作为方法区类的数据结构的接口。jvm创建对象前,会先检查类是否加载,寻找类对应的class对象,若加载好,则为你的对象分配内存,初始化也就是代码:new Object()。
上面的流程就是你自己写好的代码扔给jvm去跑,跑完就over了,jvm关闭,你的程序也停止了。
为什么要讲这个呢?因为要理解反射必须知道它在什么场景下使用。
题主想想上面的程序对象是自己new的,程序相当于写死了给jvm去跑。假如一个服务器上突然遇到某个请求哦要用到某个类,哎呀但没加载进jvm,是不是要停下来自己写段代码,new一下,哦启动一下服务器,(脑残)!
反射是什么呢?当我们的程序在运行时,需要动态的加载一些类这些类可能之前用不到所以不用加载到jvm,而是在运行时根据需要才加载,这样的好处对于服务器来说不言而喻,举个例子我们的项目底层有时是用mysql,有时用oracle,需要动态地根据实际情况加载驱动类,这个时候反射就有用了,假设 com.java.dbtest.myqlConnection,com.java.dbtest.oracleConnection这两个类我们要用,这时候我们的程序就写得比较动态化,通过Class tc = Class.forName("com.java.dbtest.TestConnection");通过类的全类名让jvm在服务器中找到并加载这个类,而如果是oracle则传入的参数就变成另一个了。这时候就可以看到反射的好处了,这个动态性就体现出java的特性了!举多个例子,大家如果接触过spring,会发现当你配置各种各样的bean时,是以配置文件的形式配置的,你需要用到哪些bean就配哪些,spring容器就会根据你的需求去动态加载,你的程序就能健壮地运行。
答案比较粗糙,点到为止!
更新一个实例辅助更好地理解
在使用Spring写业务代码的时候,我们经常会用到注解来进行类的实例化,我们自定义一个注解
GPService
@Target({ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface GPService {
String value() default "";
}我们的业务类QuerySerivce,这里就是模拟Spring的Service注解,我们用一个自定义注解。
@GPService
public class QuerySerivce implements IQueryService {
public String query(String name) {
return "query service result";
}
}然后我们在容器初始化的时候,我们需要扫描标有service注解的类,然后实例化后放进容器内。大概的代码如下:
//拿到全类名,用于定位类,这一步一般Spring是通过扫描项目路径来获取,这一步是动态获取的,反射的作用其实就在这里,思考下如果不用反射,我们要怎么实例化,不可能一个类一个类去定位,然后实例化
String className = "com.demo.QueryService";
//反射获取类的Class对象
Class<?> clazz=Class.forName(className);
//如果该类标注有GPService注解,我们就实例化这个类
if(clazz.isAnnotationPresent(GPService.class){
Object instance = clazz.newInstance();
//用map来模拟容器
map.put(clazz.getSimpleName(),instance);
}

单单是问反射有什么用,其实最常用的就两个:
- 根据类名创建实例(类名可以从配置文件读取,不用new,达到解耦)
- 用Method.invoke执行方法
但是这些其实不难理解,难的是反射本身。如果有兴趣可以往下看:
由于反射本身确实抽象(说是Java中最抽象的概念也不为过),所以我当初写作时也用了大量的比喻。但是比喻有时会让答案偏离得更远。前阵子看了些讲设计模式的文章,把比喻都用坏了。有时理解比喻,竟然要比理解设计模式本身还费劲...那就南辕北辙了。所以,这一次,能不用比喻就尽量不用,争取用最实在的代码去解释。
主要内容:
- JVM是如何构建一个实例的
- .class文件
- 类加载器
- Class类
- 反射API
JVM是如何构建一个实例的
下文我会使用的名词及其对应关系
- 内存:即JVM内存,栈、堆、方法区啥的都是JVM内存,只是人为划分
- .class文件:就是所谓的字节码文件,这里称.class文件,直观些
假设main方法中有以下代码:
Person p = new Person();很多初学者会以为整个创建对象的过程是下面这样的
javac Person.java
java Person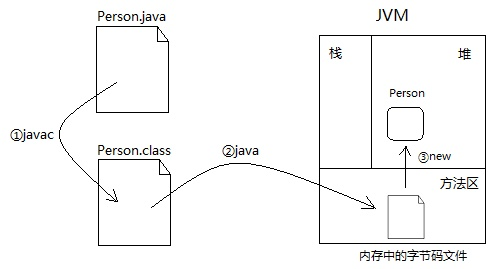

不能说错,但是粗糙了一点。
稍微细致一点的过程可以是下面这样的
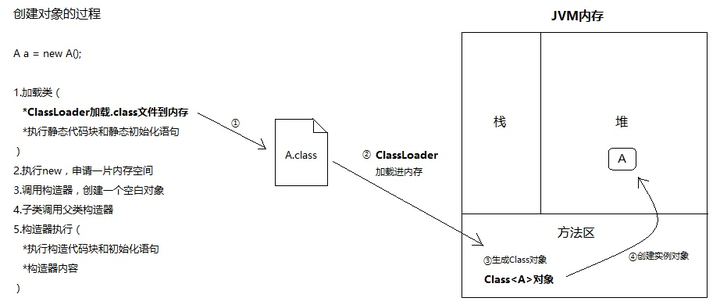

通过new创建实例和反射创建实例,都绕不开Class对象。
.class文件
有人用编辑器打开.class文件看过吗?
比如我现在写一个类

用vim命令打开.class文件,以16进制显示就是下面这副鬼样子:
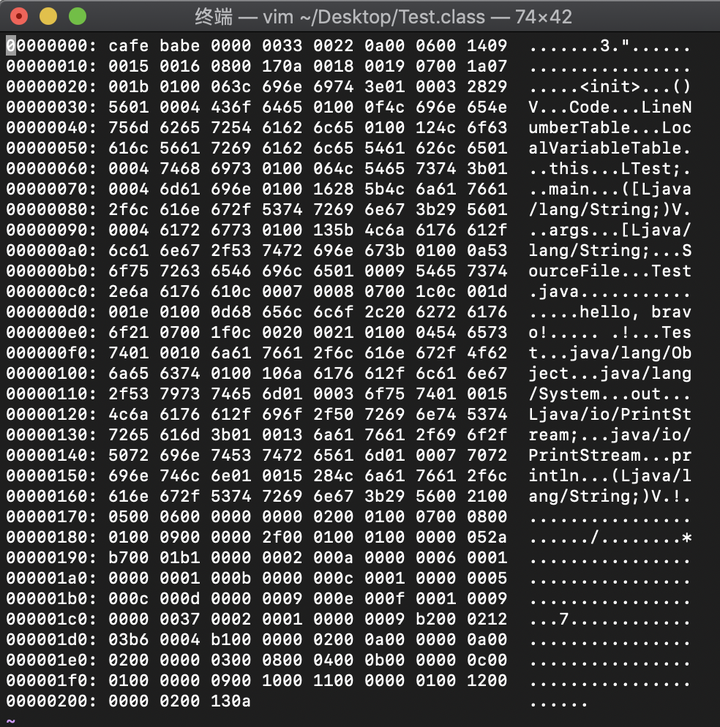

在计算机中,任何东西底层保存的形式都是0101代码。
.java源码是给人类读的,而.class字节码是给计算机读的。根据不同的解读规则,可以产生不同的意思。就好比“这周日你有空吗”,合适的断句很重要。
同样的,JVM对.class文件也有一套自己的读取规则,不需要我们操心。总之,0101代码在它眼里的样子,和我们眼中的英文源码是一样的。

类加载器
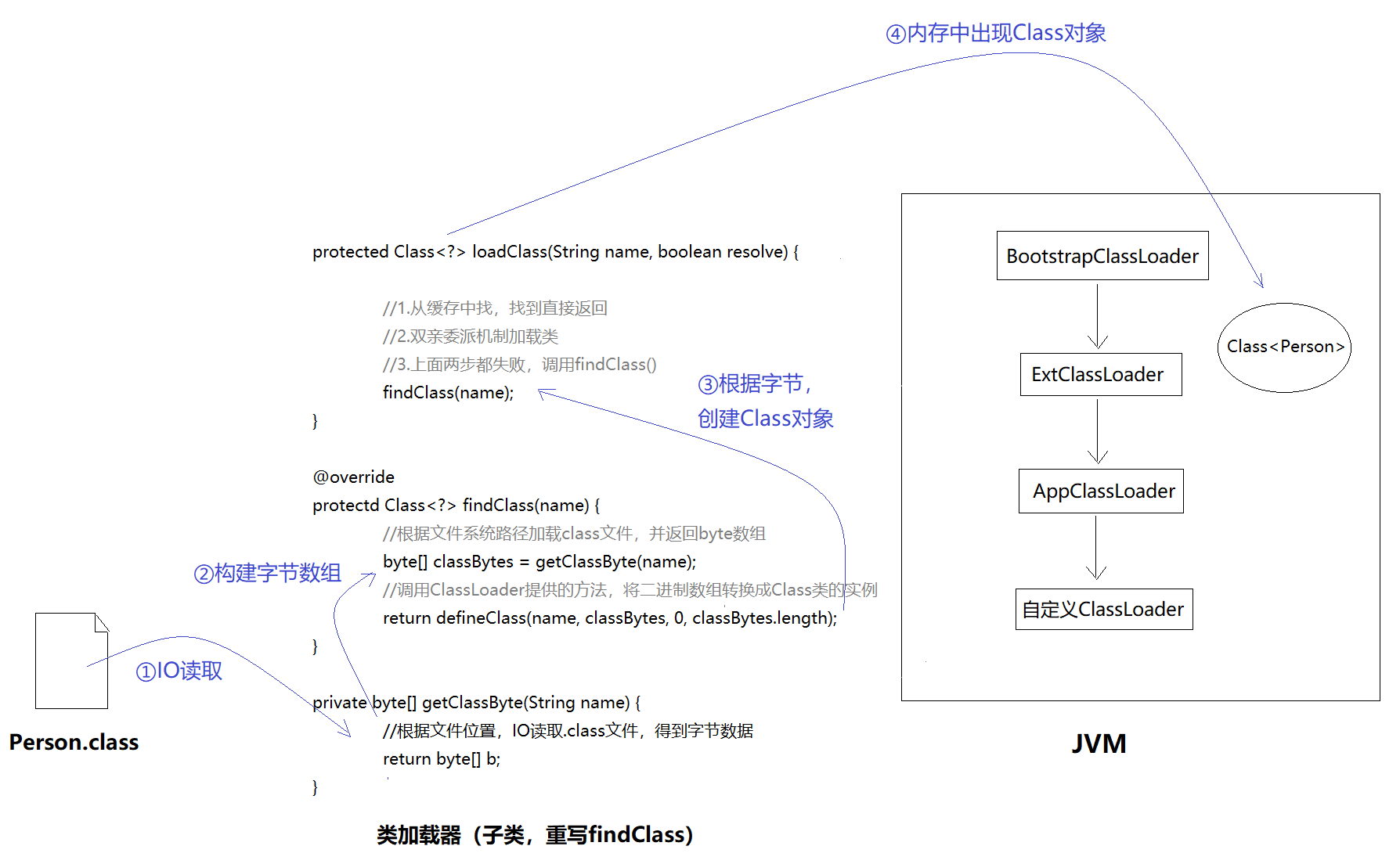
在最开始复习对象创建过程时,我们了解到.class文件是由类加载器加载的。关于类加载器,如果掰开讲,是有很多门道的,可以看看 @请叫我程序猿大人 写的好怕怕的类加载器。但是核心方法只有loadClass(),告诉它需要加载的类名,它会帮你加载:
protected Class<?> loadClass(String name, boolean resolve)
throws ClassNotFoundException
{
synchronized (getClassLoadingLock(name)) {
// 首先,检查是否已经加载该类
Class<?> c = findLoadedClass(name);
if (c == null) {
long t0 = System.nanoTime();
try {
// 如果尚未加载,则遵循父优先的等级加载机制(所谓双亲委派机制)
if (parent != null) {
c = parent.loadClass(name, false);
} else {
c = findBootstrapClassOrNull(name);
}
} catch (ClassNotFoundException e) {
// ClassNotFoundException thrown if class not found
// from the non-null parent class loader
}
if (c == null) {
// 模板方法模式:如果还是没有加载成功,调用findClass()
long t1 = System.nanoTime();
c = findClass(name);
// this is the defining class loader; record the stats
sun.misc.PerfCounter.getParentDelegationTime().addTime(t1 - t0);
sun.misc.PerfCounter.getFindClassTime().addElapsedTimeFrom(t1);
sun.misc.PerfCounter.getFindClasses().increment();
}
}
if (resolve) {
resolveClass(c);
}
return c;
}
}
// 子类应该重写该方法
protected Class<?> findClass(String name) throws ClassNotFoundException {
throw new ClassNotFoundException(name);
}加载.class文件大致可以分为3个步骤:
- 检查是否已经加载,有就直接返回,避免重复加载
- 当前缓存中确实没有该类,那么遵循父优先加载机制,加载.class文件
- 上面两步都失败了,调用findClass()方法加载
需要注意的是,ClassLoader类本身是抽象类,而抽象类是无法通过new创建对象的。所以它的findClass()方法写的很随意,直接抛了异常,反正你无法通过ClassLoader对象调用。也就是说,父类ClassLoader中的findClass()方法根本不会去加载.class文件。
正确的做法是,子类重写覆盖findClass(),在里面写自定义的加载逻辑。比如:
@Override
public Class<?> findClass(String name) throws ClassNotFoundException {
try {
/*自己另外写一个getClassData()
通过IO流从指定位置读取xxx.class文件得到字节数组*/
byte[] datas = getClassData(name);
if(datas == null) {
throw new ClassNotFoundException("类没有找到:" + name);
}
//调用类加载器本身的defineClass()方法,由字节码得到Class对象
return defineClass(name, datas, 0, datas.length);
} catch (IOException e) {
e.printStackTrace();
throw new ClassNotFoundException("类找不到:" + name);
}
}defineClass()是ClassLoader定义的方法,目的是根据.class文件的字节数组byte[] b造出一个对应的Class对象。我们无法得知具体是如何实现的,因为最终它会调用一个native方法:
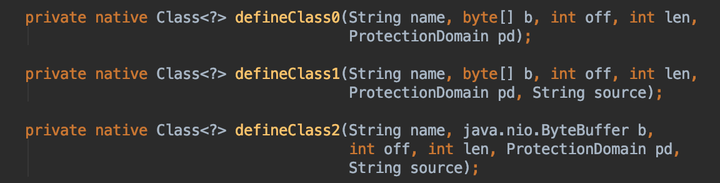
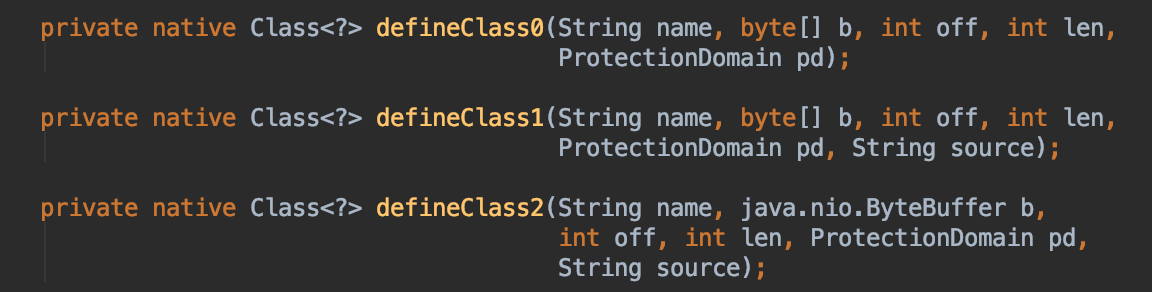
反正,目前我们关于类加载只需知道以下信息:

Class类
现在,.class文件被类加载器加载到内存中,并且JVM根据其字节数组创建了对应的Class对象。所以,我们来研究一下Class对象。
Class对象是Class类的实例,我们将在这一小节一步步分析Class类的结构。
但是,在看源码之前,我想问问聪明的各位,如果你是JDK源码设计者,你会如何设计Class类?
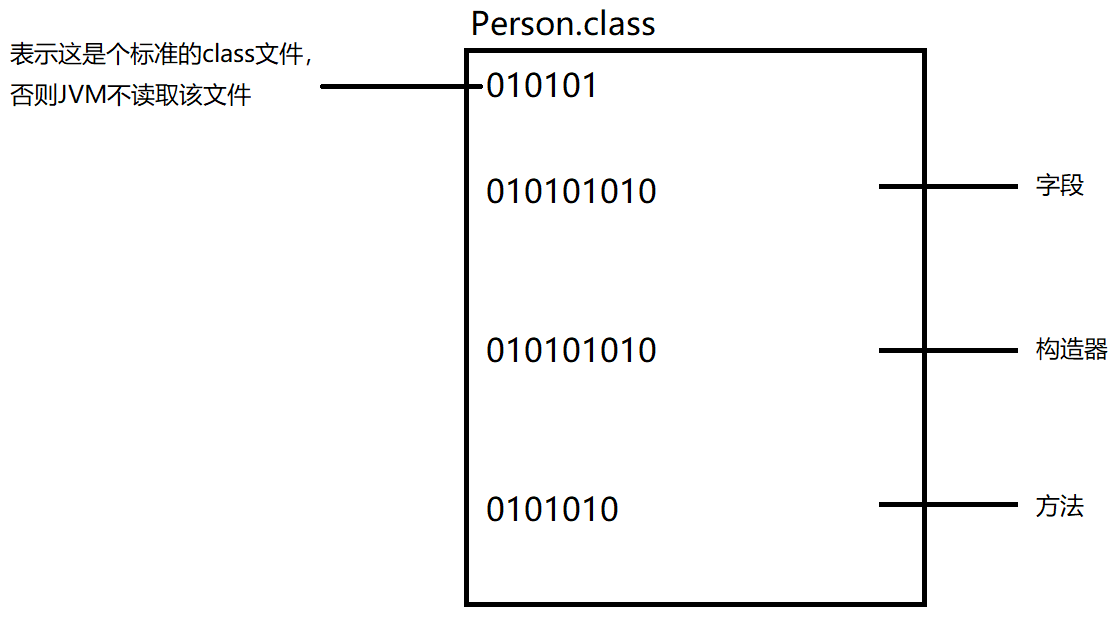
假设现在有个BaseDto类
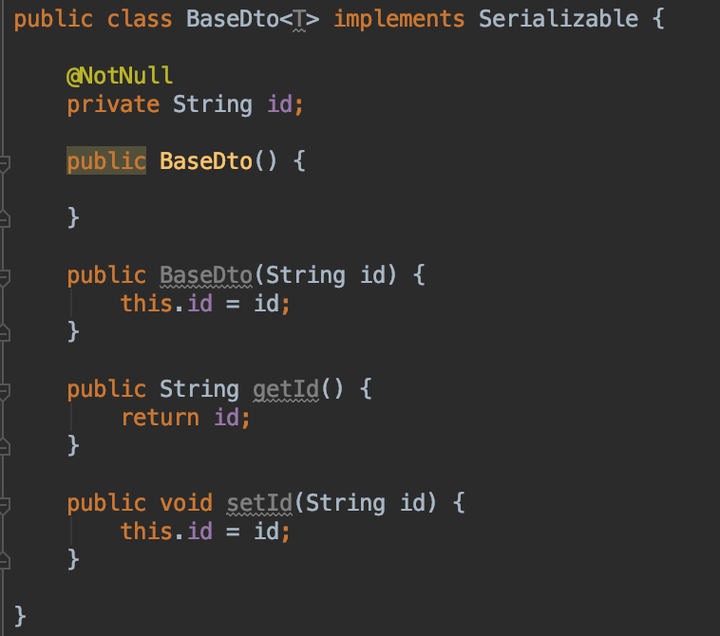

上面类至少包括以下信息(按顺序):
- 权限修饰符
- 类名
- 参数化类型(泛型信息)
- 接口
- 注解
- 字段(重点)
- 构造器(重点)
- 方法(重点)
最终这些信息在.class文件中都会以0101表示:
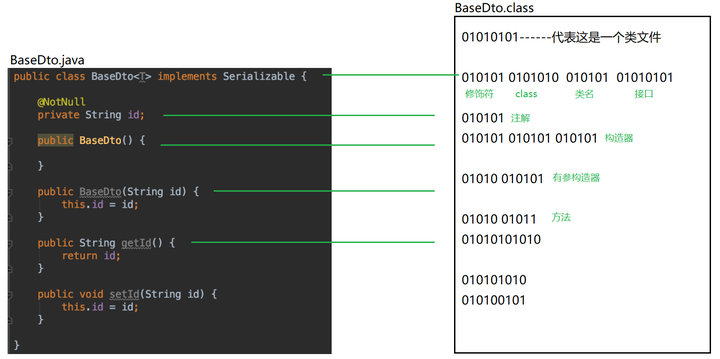

整个.class文件最终都成为字节数组byte[] b,里面的构造器、方法等各个“组件”,其实也是字节。
所以,我猜Class类的字段至少是这样的:
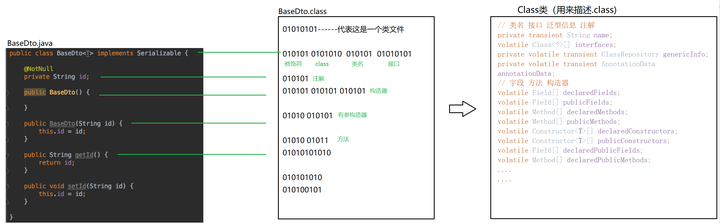

好了,看一下源码是不是如我所料:
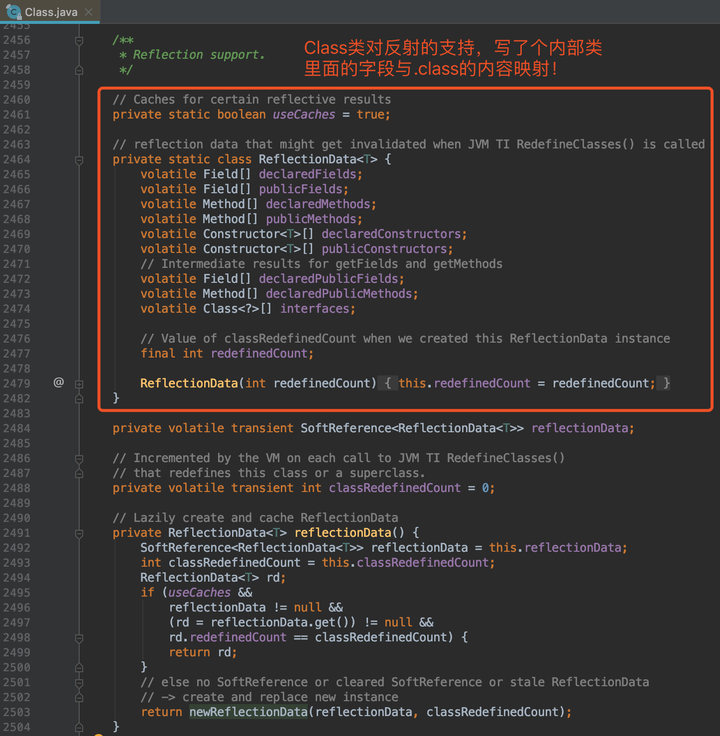





等等。
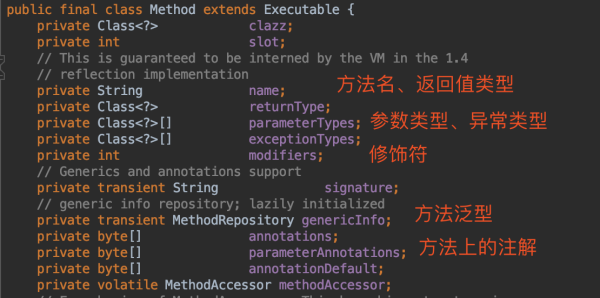
而且,针对字段、方法、构造器,因为信息量太大了,JDK还单独写了三个类,比如Method类:
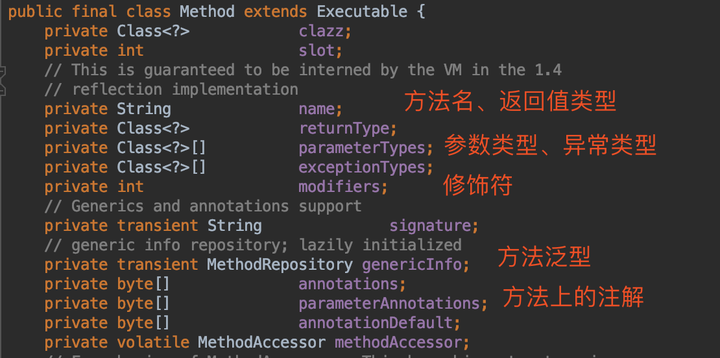

也就是说,Class类准备了很多字段用来表示一个.class文件的信息,对于字段、方法、构造器等,为了更详细地描述这些重要信息,还写了三个类,每个类里面都有很详细的对应。
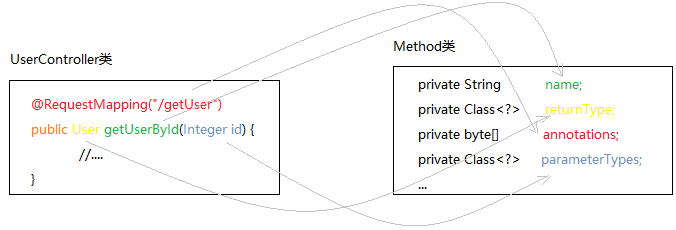

也就是说,原本UserController类中所有信息,都被“解构”后保存在Class类、Method类等的字段中。
大概了解完Class类的字段后,我们看看Class类的方法。
- 构造器
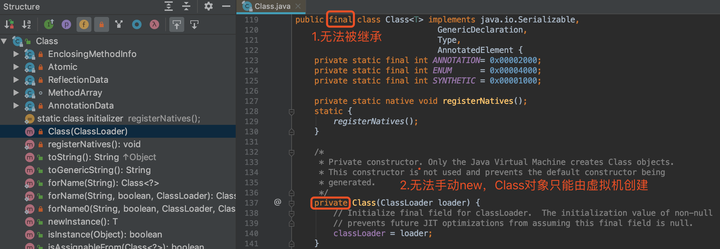
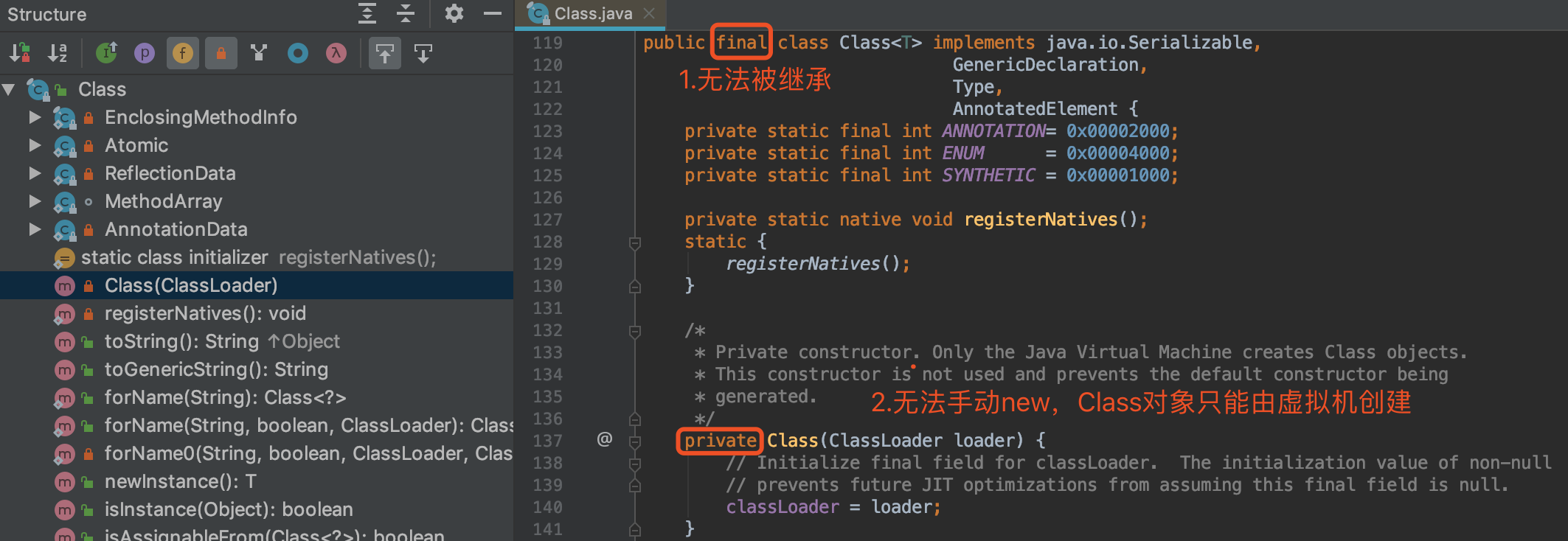
可以发现,Class类的构造器是私有的,我们无法手动new一个Class对象,只能由JVM创建。JVM在构造Class对象时,需要传入一个类加载器,然后才有我们上面分析的一连串加载、创建过程。
- Class.forName()方法
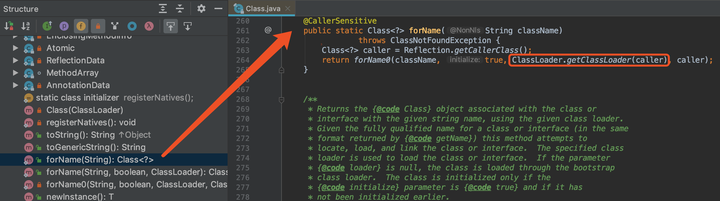

反正还是类加载器去搞呗。
- newInstance()
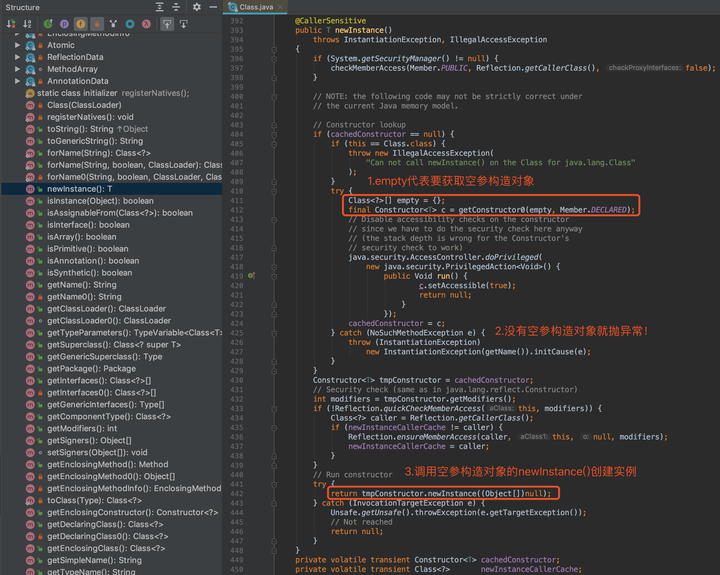

也就是说,newInstance()底层就是调用无参构造对象的newInstance()。
所以,本质上Class对象要想创建实例,其实都是通过构造器对象。如果没有空参构造对象,就无法使用clazz.newInstance(),必须要获取其他有参的构造对象然后调用构造对象的newInstance()。
反射API
没啥好说的,在日常开发中反射最终目的主要两个:
- 创建实例
- 反射调用方法
创建实例的难点在于,很多人不知道clazz.newInstance()底层还是调用Contructor对象的newInstance()。所以,要想调用clazz.newInstance(),必须保证编写类的时候有个无参构造。
反射调用方法的难点,有两个,初学者可能会不理解。
再此之前,先来理清楚Class、Field、Method、Constructor四个对象的关系:
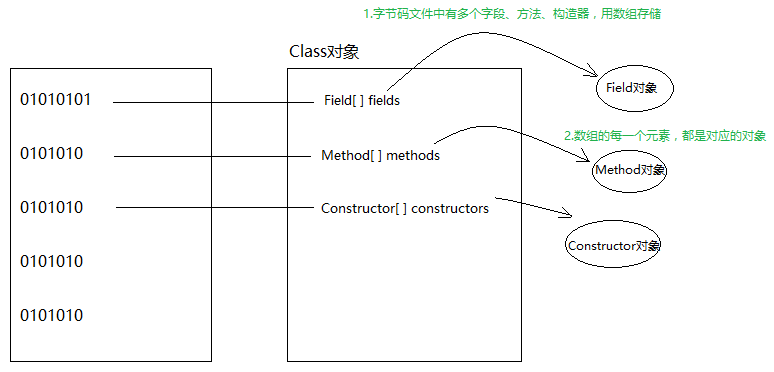

Field、Method、Constructor对象内部有对字段、方法、构造器更详细的描述:

OK,理清关系后我们继续来看看反射调用方法时的两个难点。
- 难点一:为什么根据Class对象获取Method时,需要传入方法名+参数的Class类型
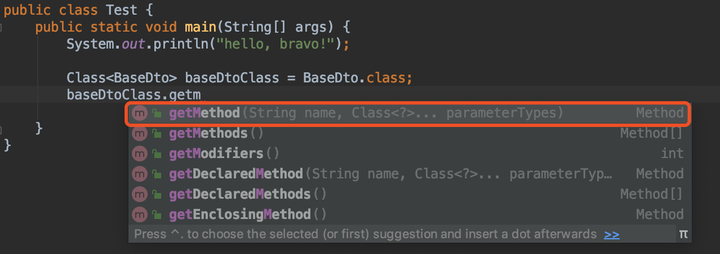

为什么要传name和ParameterType?
因为.class文件中有多个方法,比如


所以必须传入name,以方法名区分哪个方法,得到对应的Method。
那参数parameterTypes为什么要用Class类型,我想和调用方法时一样直接传变量名不行吗,比如userName, age。
答案是:我们无法根据变量名区分方法
User getUser(String userName, int age);
User getUser(String mingzi, int nianling);这不叫重载,这就是同一个方法。只能根据参数类型。
我知道,你还会问:变量名不行,那我能不能传String, int。
不好意思,这些都是基本类型和引用类型,类型不能用来传递。我们能传递的要么值,要么对象(引用)。而String.class, int.class是对象,且是Class对象。
实际上,调用Class对象的getMethod()方法时,内部会循环遍历所有Method,然后根据方法名和参数类型匹配唯一的Method返回。
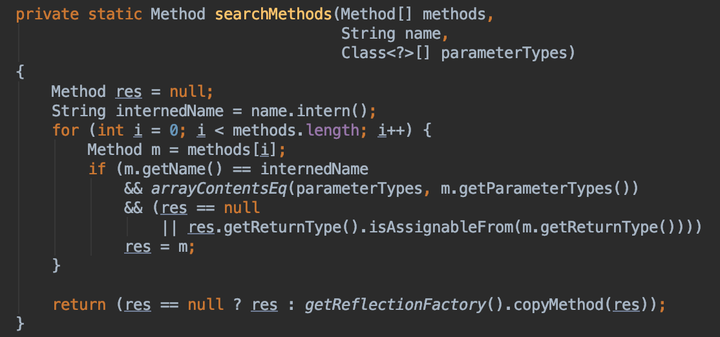

难点二:调用method.invoke(obj, args);时为什么要传入一个目标对象?
上面分析过,.class文件通过IO被加载到内存后,JDK创造了至少四个对象:Class、Field、Method、Constructor,这些对象其实都是0101010的抽象表示。
以Method对象为例,它到底是什么,怎么来的?我们上面已经分析过,Method对象有好多字段,比如name(方法名),returnType(返回值类型)等。也就是说我们在.java文件中写的方法,被“解构”以后存入了Method对象中。所以对象本身是一个方法的映射,一个方法对应一个Method对象。
我在专栏的另一篇文章中讲过,对象的本质就是用来存储数据的。而方法作为一种行为描述,是所有对象共有的,不属于某个对象独有。比如现有两个Person实例
Person p1 = new Person();
Person p2 = new Person();对象 p1保存了"hst"和18,p2保存了"cxy"和20。但是不管是p1还是p2,都会有changeUser(),但是每个对象里面写一份太浪费。既然是共性行为,可以抽取出来,放在方法区共用。
但这又产生了一个棘手的问题,方法是共用的,JVM如何保证p1调用changeUser()时,changeUser()不会跑去把p2的数据改掉呢?
所以JVM设置了一种隐性机制,每次对象调用方法时,都会隐性传递当前调用该方法的对象参数,方法可以根据这个对象参数知道当前调用本方法的是哪个对象!
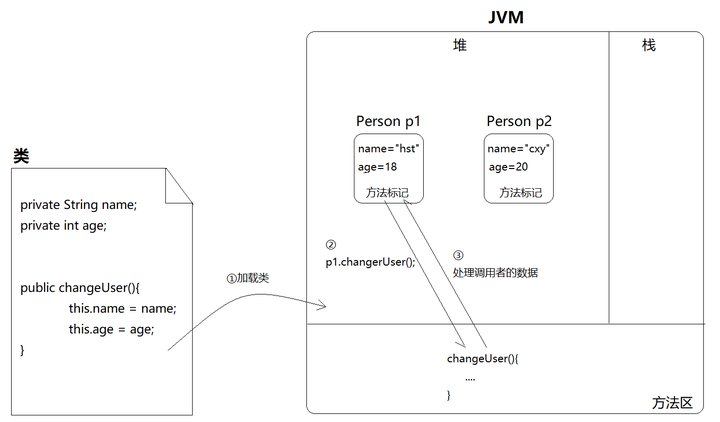

同样的,在反射调用方法时,本质还是希望方法处理数据,所以必须告诉它执行哪个对象的数据。
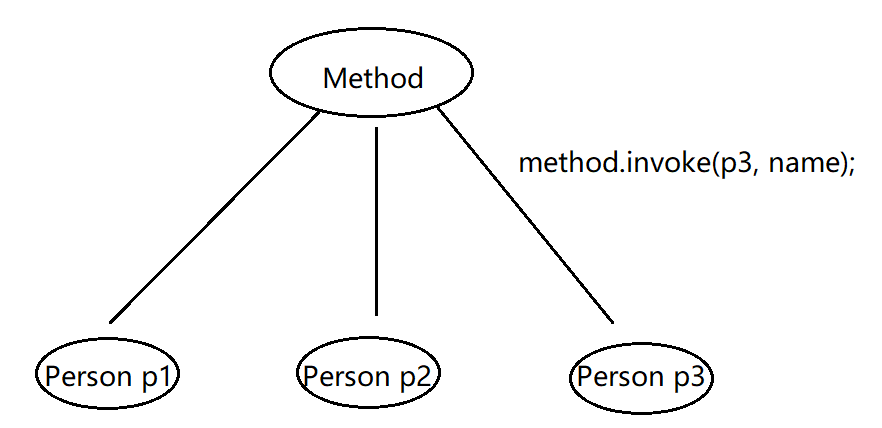

所以,把Method理解为方法执行指令吧,它更像是一个方法执行器,必须告诉它要执行的对象(数据)。
当然,如果是invoke一个静态方法,不需要传入具体的对象。因为静态方法并不能处理对象中保存的数据。
2019-5-24 18:00:00
更多文章请移步: