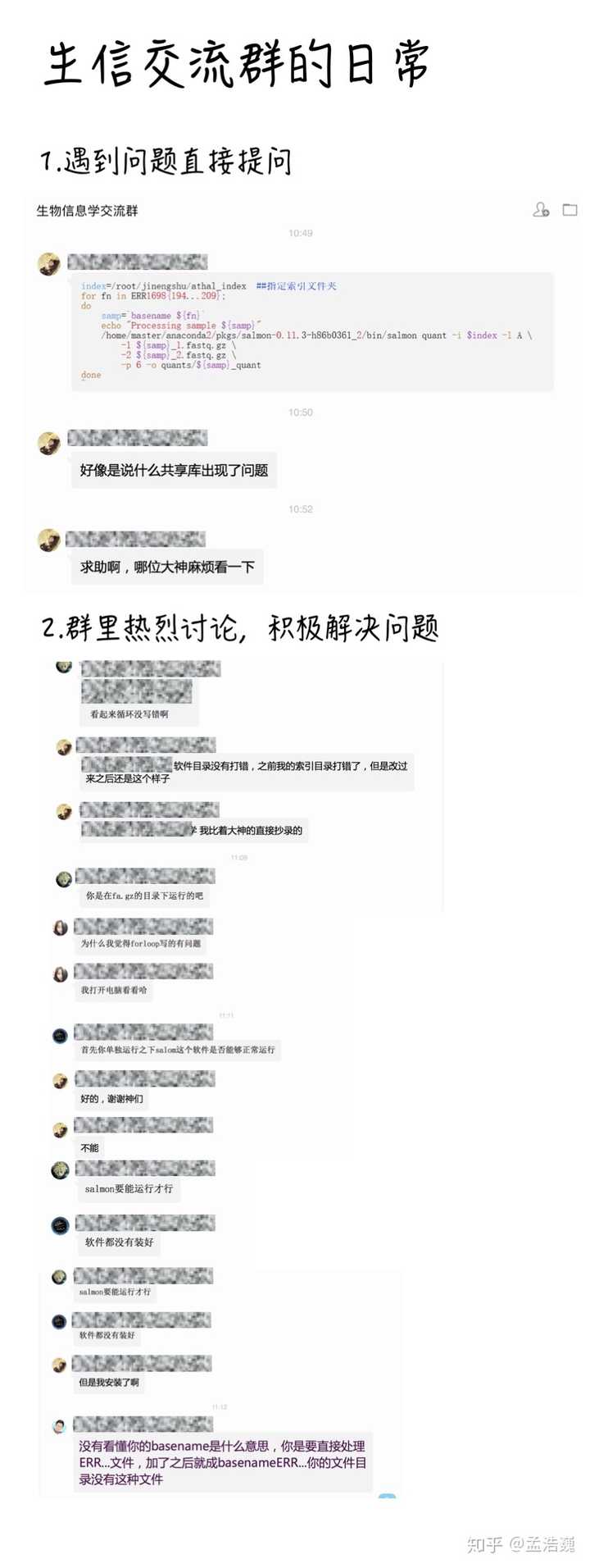
如何自学生物信息学?

谢谢邀请!
其实这个问题一直想回答,但是很多时候打开又不知道要说什么。静了静心,仔细回忆起自己学习生信这7年的时间,走过的路,踩过的坑,有一些感慨,今天也分享给大家,全当给大家提供一些经验~
1. 在正式回答之前,我们需要回答一个问题,你想自学生物信息学到什么程度?
在我目前的认知中,我把生物信息学的学习分成4个层次,不同的层次,学习到不同的程度时间,经历,和对资质的要求当然是不同的。
第1层,从小白入门到能够做一名生物信息学技术员,大概1年左右的时间就够了。成为技术员的要求大概是,对于成熟的生物信息学流程要能用,会用;要能够处理流程出现的各种bug;会写一些小的脚本。只要大家肯花时间,肯用心,都能够达到这个level。
第2层,从一名生物信息学技术员成长成这个领域的小专家,大概需要再耗费2~3年左右的时间。我觉得,对于这个层次的要求,应该是在能够解决日常的问题的基础上,重点突出自主推动和承担课题或者项目的能力。大概相当于优秀的研究生,或者是高年级的博士生。
第3层,从某一个领域小专家成长为专精的小牛,这大概还需要在某个具体的领域再深耕2~3年。到这个层次,已经是一个公司的技术扛把子,也有可能是某些学校的青年PI。
第4层,从小牛成长为能够引领潮流,开创领域的,指导学科发展的大牛。除了资源,时间,努力以外,还需要天资。
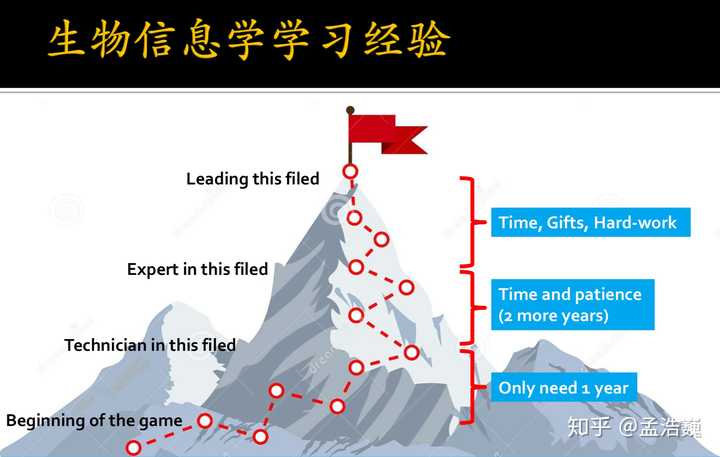

所以,我们要把生信到什么样子呢?这个问题,只要你自己知道。
2. 生物信息学的理解
下面我们简单聊聊什么是生物信息学。其实,我认为,生物信息学最简单的定义就是用信息的手段去研究生物问题的学科——信息是手段,生物问题是核心。千万不要搞错问题,不要太过执着追求于某一个信息技术的细节,而是应该把重点放到解决生物问题上。
已故的统计物理学家郝柏林院士曾经在生物信息学领域做出过非常突出的贡献,他也是我们国家第一代生信人。郝院士对生物信息学有4句话,我在这里分享给大家。


也是因为“生物是物,生物有理,生物有数,生物有形”我们才能够用统计学,信息学的办法去研究生物问题。


所以,再次强调,生物信息学是我们手里的锤子,生物问题是我们周围的钉子,我们要做的就是用锤子去钉钉子。而入门生物信息学,学习生物信息学就可以分成两个层面来进行,一方面要把我们的锤子炼硬(信息技术),另一方面要锻炼找钉子的能力(科学思维训练)。
3. 生物信息学要解决的问题 (2019-10-04更新)
现在我们可以讨论一下,生物信息学都要解决哪些问题了。
从传统的生物信息学来说,那个时候的生物信息学,主要还是低通量的解决一些重要的问题,构建一些基础算法,在低通量的水平挖掘一些序列中有价值的信息,比如寻找蛋白的序列的功能结构域,寻找一些DNA序列中的motif等等。
但是自从2006年Illumina公司正式发布了第二代测仪以后,这一切都发生了变化,生物数据的数据量成几何倍数在进行增长,生物信息学也第1次面临了高通量这个挑战。(当然,真正成熟应用的二代测序仪要等到2008年左右。)
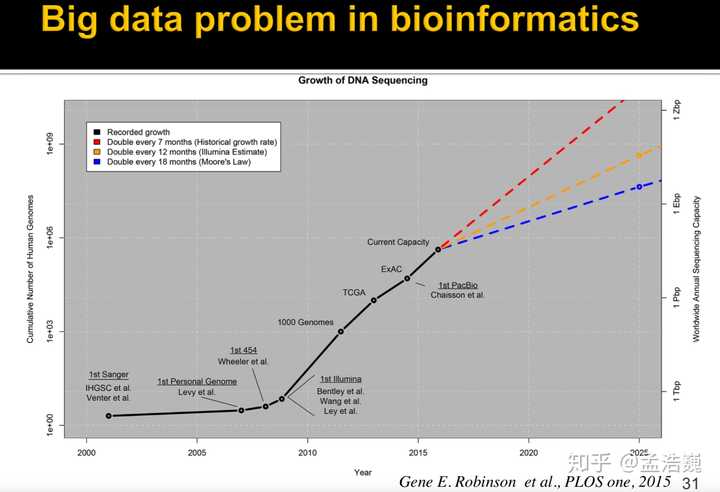

上图横轴是年份,纵轴是与人类相关的基因组数据积累量,蓝色虚线代表摩尔定律,即每18个月整体数据量翻一番;而真实的生物数据是红色的虚线,也就是每7个月生物数据的数据量就要整体翻一番。
这有多可怕呢,我可以换一种说法:从今年1月份到今年7月份这7个月新产生的生物数据的数据量,等于之前产生的所有生物数据。
那么,也就基于此,当前生物信息学最主要的问题,全部都是围绕测序数据展开的。
所以,如果硬要给现在的生物信息学主要解决的问题分分类,大概可以分成下面几个方向:
- 开发、改进新的算法(如改进比对算法);
- 针对某种特定的问题,发开好用的流程与工具(如ChIP-Seq有各种分析注释的工具);
- 开发、改进新的数据库(如开发自己领域内有价值的数据库,可以发到NAR特刊哟~);
- 深度挖掘现有的公共数据(如挖掘TCGA,GTEx等公共数据);
- 定制分析数据并设计生物学实验(如很多干湿结合的实验室);
- 新技术催生的系列分析(如单细胞,宏基因组,三维基因组…… )
- 利用数学建模或者物理模型解决生物问题(其实更偏系统生物学);
所以,结合要解决的问题和我们想要达到的level才知道我们的终点在哪里,也才知道我们一些东西,我们在入门的时候要不要重点考虑。
比如,很多临床医生朋友,就是想画个炫一点的图,那研究半天背后的统计原理就不是一个性价比很高的入门策略。再比如,想做独立成长为可以独当一面的生物信息学分析专家,那么很多时候,一些比较重要的算法和统计学知识是不可或缺的。
也许,我们的目标不同,终点不同,但是我还是希望能够按照下面的分类给出一些几乎是做生信必须要会的内容,供大家参考。
4. 生物信息学入门的6个方面
4.1 从Windows到Linux
无论以后是做偏算法的计算生物学(computation biology),还是做生物数据的挖掘(biological data mining)工作,基本上都是在Linux平台或类Unix平台(MacOS)下完成计算与分析的。一个比较重要的原因是,Linux或者类Unix平台(下面用Linux代指)下有非常完善的开源体系,基本上所有的生物信息学软件在设计之初都首先考虑Linux平台。
因此,学习使用Linux可以说是生物信息学入门的第0课,是最最基础的内容。说到这里,很多老铁可能会有畏难情绪了,会问:Linux是不是很难学习啊?我看Linux都是命令行,会不会特别麻烦?
我的看法是,如果你能够熟练使用Windows系统,对文件进行复制, 粘贴,移动,重命名,压缩,解压缩那么你就完全没问题。因为在Windows里,上述操作只不过是变成了鼠标的操作,Linux也仅仅是把鼠标操作变成命令行操作,没有任何任务内容上的不同,仅仅是鼠标点图形界面与命令行操作的不同。
那么,还有的老铁会说:“我看大家推荐的《鸟哥的Linux私房菜》是一本很厚的书,Linux是不是需要学的内容特别多?”
对于这个问题,我的回答是:相信我,如果你去找一本详细介绍Windows的书,一定比《鸟哥的Linux私房菜》要厚得多。Linux操作系统确实是博大精深,但是我们既然是入门,能够上手使用是第一要务,领会精神,把握重点才是首要的事情。
而关于资料的推荐,推荐10本资料等于没有推荐,因为没有重点。
在这里,我推荐1份10页左右的资料,1份动手操作的课程,1本参考书。
首先是1份资料,就像我们平时用Windows电脑,也不会去用到Windows的所有功能,我们用Linux做生物信息学分析也是一样的,平常能够用到的Linux命令也就不超过30个,北京大学生物信息学中心的创始人之一罗静初老师在自己的网站上总结过一份资料,这份资料包括小部分的内容,分别是《Linux十大常用命令》《Unix十大实用命令》《Unix十大高级命令》,能够熟练掌握这30个命令,你做生物信息学的Linux部分基本问题不大了。
然后是1个动手课程,我非常推荐实验楼的动手课程,里面的Linux入门是免费课程,基本上能够交互式的完成相关的内容。省去了小白自己装Linux系统的麻烦。
最后是一本参考书级别的《鸟哥的Linux私房菜》,私房菜是Linux领域的经典,但是里面的内容繁多,不太适合简明扼要的学习,而适合当做系统学习,或者是学习之余的参考资料。因此,我建议大家把这本书当做一个参考书,不会了好好读读相关章节就行。


这个部分提到的课程网址如下,另外资料也放到了对应的baidu盘,大家取需。
实验楼Linux入门课程地址: Linux 基础入门(新版)_Linux - 实验楼
链接: https://pan.baidu.com/s/1Vcv3h9olITXpDF1gl2YIWQ 提取码: h8tg
如果很想买纸质版,我推荐第3版比较便宜;第4版比较贵,但是内容新,购买链接。
4.2 电脑推荐
目前来说,生物信息学主要是和高通量测序数据打交道,大量运算的任务基本上是交给服务器来进行,但是运算完以后的结果需要进行统计,绘图,整理,这个过程一般是在本地进行。考虑到实际使用情况和便捷情况,目前主流的有两个选择,1个是选择苹果系统(MacOS),一个是选择Windows系统。
就我个人的使用习惯,我觉得MacOS(苹果操作系统)非常适合做生物信息学,一方面是能够与Linux的命令行保持一致,另一方面能够有非常多的常用软件支持。要知道目前Linux下是没有QQ,Microsoft Office等常用软件的,但是在Mac下这个完全不是问题。
当然,Mac也是有缺点的,缺点就是贵。而且如果要想把Mac当主力机器使用,需要至少16~32GB的运行内存,就这个配置的苹果电脑基本上都是1W大几千以上了。所以,如果“穷且志坚”可以试试黑苹果。黑苹果的意思是,自己组装和挑选配置,最后安装MacOS的操作系统,实现和正版苹果电脑一样的功能。基本上用过黑苹果的同学,都不会再换回到Windows平台下做生物信息学。
如果,非要用Windows去做生物信息,当做主力机器,也不是不可以。只不过有一些配套的软件可能和服务器衔接的不够好。
无论是选择Windows还是Mac,亦或是黑苹果我都推荐如下的配置;
CPU:i7-8700 、i7-9700
内存:16GB以上,32GB或者64GB更好
固态硬盘:最好是NVMe接口,250GB以上,用于安装操作系统及快速读取数据
机械硬盘:普通机械硬盘即可,容量4TB以上
显卡:根据自己的实力选择即可,如果后期需要做机器学习和深度学习,可能需要好一点的显卡。我在这里打一个小广告
如果大家想买黑苹果,可以私信联系我,我和一位淘宝金牌卖家共同为大家定制了适合做生物信息学的黑苹果配置,价格从5000到1W+都有。同时,如果大家在这家店购买了黑苹果,我会送上我自己的系统配置,省去了很多新手配置的麻烦。
4.3 学一门编程语言
学习生信,永远都跳不过学习编程这个问题。
关于这个问题,我给出一个比较中肯的意见:如果你的实验室师兄师姐都在用一门编程语言,你就跟他们保持一致,这样代码使用起来比较方便,更有利于你自己的学习氛围。
目前,在生信中应用比较多的编程语言除了啥都能干的C++和Java以外,做字符串处理非常方便的就是Python和Perl。如果你做的工作对运算速度没有特别极致的要求,亦或者是不会去开发非常大型的软件,而你又没有什么编程基础,那么你可以首先就排除C++和Java了。
至于Perl和Python的选择,我个人还是倾向于Python,虽然有的时候用Perl会有更简洁的代码。但Python的工具包非常多,也有非常完善的教程,入门起来和很方便。更关键的是,现在做生信,多多少少都会用点机器学习的东西,Python做机器学习几乎都是首选语言了。
关于Python的教程,我比较推荐 @廖雪峰 老师的教程,简明扼要地把知识的主干都理清楚了。能够让你快速地抓住Python这门语言的特点,极力推荐。
另外,如果你非要想买一本书来学习Python的话,我推荐《跟老齐学Python》,这本书语言比较风趣,像是在与你做对话。
廖雪峰老师的Python教程链接: 廖雪峰Python教程
跟老齐学Python的网络版链接:《跟老齐学Python》gitbook版 · GitBook (Legacy)
某宝链接(欢迎下单哟~)


当然,如果你还是想看一个语音教程的话,也可以试试我的知乎live,里面除了一些基础编程内容外,还从生信的角度挑选了几个问题,带着大家一起编程。
4.4 R语言与统计知识
我没有把R语言放到4.3这个章节,主要是觉得如果把R语言算做一门非常严谨的编程语言,有点不大合适。在我这么长时间的使用过程中,我更习惯把R语言当做一门统计语言来对待,这门语言就真的是为统计而生的,而学生信必然要学统计。因此,统计,R语言我们都要面对。
先说说统计。很多朋友,一提到数学就头大,好像从小到大一直在被数学虐。但其实,我觉得还是要放轻松,因为生物信息学里面比较初步的一些统计知识,还是比较好懂的。如果大学里学过《概率论和数理统计》这么课,就太好不过了。基本上这门课就涵盖了我们生信入门需要的绝大多数的统计知识。
那为什么,很多时候即便是本科学习过这门课,真的在使用统计学处理生物信息学问题的时候还是觉得力不从心呢?最主要的原因是本科更强调按照教学大纲去教授你几乎所有的知识点,但是没有根据生物信息学的实际需要进行扩充和增减。
比如,生信里比较重要的分布是Poisson分布,在《概统》这么课你可能只会在概率论部分的离散部分中知道有这么个分布。但是在生信中,如何用Poisson分布去检测富集信号,怎么去call peak就不甚了解了。
再比如,你在概统里肯定学习过t检验(t-test),但是你拿到数据的时候你直接就用t-test可能就会得到与事实相反的结果。这是因为,在教学的时候不会强调t-test的适用条件,即数据分布服从正态分布且方差相等。但是真实数据,很多时候你不进行log2处理就不会服从正态分布,或者是方差就是不相等,这个时候你又需要怎么办呢?这个时候,你可能需要做一定的数据变换,也有可能需要做Wilcox秩和检验,从而代替t-test。
上面我举的两个例子都还是非常典型的,那么怎么解决这个问题呢?我的建议是,对自己的统计知识进行回炉重造,如果想要扎扎实实地学好统计学,那么我还是非常建议你去跟一门MOOC课程,比如浙江大学的《概率论和数理统计》的MOOC就非常不错。此外,我还建议去看一本《医学统计学》,因为《医学统计学》更加偏重实际应用,能够用最简单的语言给你讲清楚概念,同时弱化公式推导,一切以应用为导向。等你在实际的项目中,能够熟练,正确地应用这些知识以后,再学习那些理论,公式的推导你会有豁然开朗的感觉。
当然,我自己开了一门统计入门课,里面主要介绍了2个内容,1个是做生信统计学到底怎么学,另一方面是把生信中最常见的若干种统计问题全部给大家讲清楚,有兴趣的老铁可以支持一下我的课程。
然后我再谈谈R语言。我每一年在R里至少下写下5W~10W行以上的代码,就我的经验来说,R语言的学习一定要按照下面的这个步骤:
基础知识 -> 实际应用 -> 进阶知识 -> 实际应用 ... ...这个就是我反复跟大家强调的,R语言其实是一门非常偏应用的工具,你一定要实际把它用起来。一味地强调基础理论的学习,到最后你还是什么都不会。一定要在稍微学习一点知识以后,学着照葫芦画瓢,先把R语言用上,画点好看的图再说。
那么,针对R语言的学习很多人推荐《R语言入门》或者是英文名《R For Beginners》我不是很推荐。我推荐另外1本书,然后再推荐我的1个知乎Live,这本书呢就是《R语言编程艺术》,这本书从入门到精通可以一直陪着你。在最初入门的时候,只需要看前9章的内容(全书的一半都不到)。某宝,某东的书籍链接:


我的知乎Live主要为大家介绍R的基础语言结构,并带领大家学习常用图的绘制(boxplot,histogram,heatmap,scatter plot等等),还为大家介绍了R的基础绘图系统,里面有我的视频教程,一行一行带着大家去学习。
4.5 生物学与生物信息学基础
我在上述内容中,一直在不断强调,生物信息学其最核心的内核还是去解决生物的问题。因此,想要学习生物信息学,并能够进一步推动课题的进展,就需要理解生命过程。那么生物学相关最核心的课程其实就2门,一门名曰《细胞生物学》,另一门名曰《分子生物学》,这两门课在国外的很多课程里都是揉在一起讲的。
我特别推荐的是MIT教授Eric Lander老爷子讲的生物学基础,非常值得一看。如果你之前的生物水平还停留在高中,那么看完这个视频之后,你就对目前生物学的基础概念有了一个比较清楚的认识。
4.6 重复1篇领域内的经典论文paper
写到这里,你也看到了这里。如果说上面的内容都是把生信拆解成各个部分,让你分头击破,那么这里我们需要做的就是生物信息学入门的最后一个部分——把之前的学习内容都综合应用一遍。
具体说来,在我眼里什么叫做真的可以做生物信息学入门了呢?
就是1个标准,选择一篇你所关注的研究领域,选择一篇比较重要的文章,最好是和你以后的研究用类似的研究方法的文章。把文章读懂,再把文章的数据下载下来,重复出文章的主要结论,并模仿文章的figure把每一个主要的figure都绘制出来。
文章读懂的含义是,能够理解文章的行文逻辑,实验设计,以及文章可能存在的不足,要思考为什么这篇文章能够发表,并能够获得大家广泛的关注;
重复文章的结论的含义是,不要求100%能够算出和文章完全一致的结果,比如文章的计算结果是上调50%,你算出上调55%或者上调45%就好,只要主要结论保持一致就行,这基本证明了你对文章数据分析的理解是没有错误的。
重复文章figure的意义是,你只有真的把数据绘制出figure来,你才能够真的体会到,从数据的产生,到数据的收集,再到数据的挖掘,分析,整理,最后再把数据以图表的方式展示出来的完整过程是怎么样的。
只要你能把这个问题解决,那么你就可以非常骄傲地说:你已经生物信息学入门了,不再是生物信息学的小白了。
出了生信的“新手村”,外面的世界会更精彩!
老铁,祝你好运!
经典文献推荐(待续...)
最后,希望大家多多支持我们的生物信息学入门知乎Live,无论是购买哪一场生信入门知乎Live,都可以加入我们的讨论群。目前讨论群人数已经超过2500人,会定期推送经典文献,分享经典代码,群上限3000,人满就不再加人咯!
购买其中任意1次生物信息学知乎Live都可以加入到我们的生物信息学交流群!
注意!入群的时候需要提交1个申请信息,申请信息的内容在每次生信知乎Live的最最下面!
P.S. 平时生信交流群的讨论截图