特征工程中的「归一化」有什么作用?
38 个回答

不少答主都解释了为什么消除量纲可以加速优化过程,直观角度可以参考 @忆臻的回答(他的最高票回答指的不是我的答案)。我想在大家回答上补充一些内容:
- 数据缩放的本质是什么
- 不同数据缩放的区别
- 如何选择适合的缩放方法
在这个回答下,我们对一维数据的缩放有如下定义:
- 归一化(normalization): \frac{X_i-X_{min}}{X_{max}-X_{min}}
- 标准化(standardization): \frac{X_i-\mu}{\sigma}
其中 \mu 和 \sigma 代表样本的均值和标准差, X_{max} 为最大值, X_{min} 为最小值。
1. 归一化和标准化本质上都是一种线性变换
先看归一化,在数据给定的前提下,令常数 \alpha={X_{max}-X_{min}} ,常数 \beta=X_{min} ,那么归一化的新的形式就是 \frac{X_i-\beta}{\alpha} 。在这种改写后下,易发现和标准化形式 \frac{X_i-\mu}{\sigma} 类似,因为在数据给定后 \mu 和 \sigma 也可看做常数。
因此可以再稍微变形一下:\frac{X_i-\beta}{\alpha}=\frac{X_i}{\alpha}-\frac{\beta}{\alpha}=\frac{X_i}{\alpha}-c (公式1)
就发现事实上就是对向量 X按照比例压缩\alpha再进行平移 c。所以归一化和标准化的本质就是一种线性变换。
举个简单的例子:
- 原始数据: X=[1,2,5,3,4] ,其中 \alpha={X_{max}-X_{min}}=4 , \beta=X_{min}=1, c=\frac{\beta}{\alpha}=\frac{1}{4}
- 归一化:代入公式1,将 X 压缩4倍并平移 \frac{1}{4} ,得到\frac{1}{\alpha} X-c=[\frac{1}{4},\frac{2}{4},\frac{5}{4},\frac{3}{4},\frac{4}{4}]-\frac{1}{4} ,最终有 [0,\frac{1}{4},1,\frac{2}{4},\frac{3}{4}]
- 标准化:与归一化类似,略
2. 线性变化的性质
线性变换有很多良好的性质,这些性质决定了为什么对数据进行改变后竟然不会造成“失效”,反而还能提高数据的表现。拿其中很重要的一个性质为例,线性变化不改变原始数据的数值排序。
感兴趣的朋友可以试试下面的代码,就会发现这两种处理方法都不会改变数据的排序。对于很多模型来说,这个性质保证了数据依然有意义,顺序性不变,而不会造成了额外的影响。

from sklearn import preprocessing
from scipy.stats import rankdata
x = [[1], [3], [34], [21], [10], [12]]
std_x = preprocessing.StandardScaler().fit_transform(x)
norm_x = preprocessing.MinMaxScaler().fit_transform(x)
# print(std_x)
# print(norm_x)
print('原始顺序 :', rankdata(x))
print('标准化顺序:', rankdata(std_x))
print('归一化顺序:', rankdata(norm_x))说白了,只是因为线性变换保持线性组合与线性关系式不变,这保证了特定模型不会失效,忘记的朋友需要翻翻高数课本。
3. 归一化和标准化的区别
我们已经说明了它们的本质是缩放和平移,但区别是什么呢?在不涉及线性代数的前提下,我们给出一些直觉的解释:归一化的缩放是“拍扁”统一到区间(仅由极值决定),而标准化的缩放是更加“弹性”和“动态”的,和整体样本的分布有很大的关系。值得注意:
- 归一化:缩放仅仅跟最大、最小值的差别有关。
- 标准化:缩放和每个点都有关系,通过方差(variance)体现出来。与归一化对比,标准化中所有数据点都有贡献(通过均值和标准差造成影响)。
当数据较为集中时, \alpha 更小,于是数据在标准化后就会更加分散。如果数据本身分布很广,那么 \alpha 较大,数据就会被集中到更小的范围内。
从输出范围角度来看, \frac{X_i-X_{min}}{X_{max}-X_{min}} 必须在0-1间。对比来看,显然 \sigma\leq X_{max}-X_{min} ,甚至在极端情况下 \sigma=0 ,所以标准化的输出范围一定比归一化更广。
- 归一化: 输出范围在0-1之间
- 标准化:输出范围是负无穷到正无穷
4. 什么时候用归一化?什么时候用标准化?
我们已经从第三部分得到了一些性质,因此可以得到以下结论:
- 如果对输出结果范围有要求,用归一化
- 如果数据较为稳定,不存在极端的最大最小值,用归一化
- 如果数据存在异常值和较多噪音,用标准化,可以间接通过中心化避免异常值和极端值的影响
一般来说,我个人建议优先使用标准化。在对输出有要求时再尝试别的方法,如归一化或者更加复杂的方法。很多方法都可以将输出调整到0-1,如果我们对于数据的分布有假设的话,更加有效方法是使用相对应的概率密度函数来转换。让我们以高斯分布为例,我们可以首先计算高斯误差函数(Gaussian Error Function),此处定为 erfc(\cdot) ,那么可用下式进行转化:
max\left\{ 0, erfc\left( \frac{x-\mu}{\sigma\cdot\sqrt{2}} \right) \right\}
具体讨论可参考我的文章 机器学习「输出概率化」:一种无监督的方法。


为什么要进行归一化处理,下面从寻找最优解这个角度给出自己的看法。
例子
假定为预测房价的例子,自变量为面积,房间数两个,因变量为房价。
那么可以得到的公式为:
y=\theta _{1}x_{1} +\theta _{2}x_{2}
其中 x_{1} 代表面积, x_{2} 代表房间数变量。
首先我们祭出两张图代表数据是否均一化的最优解寻解过程。
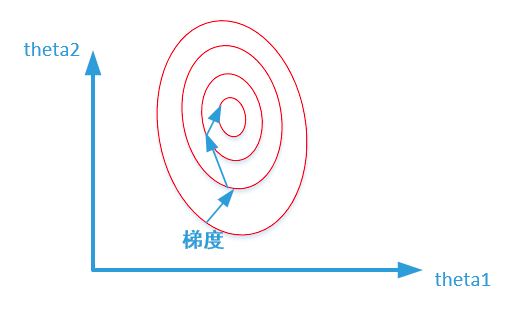
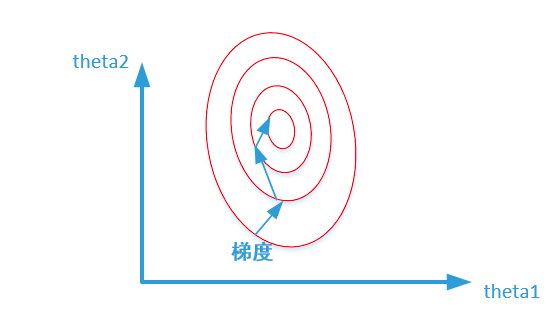
未归一化:

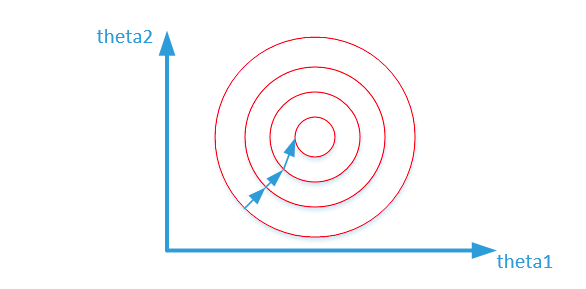
归一化之后

为什么会出现上述两个图,并且它们分别代表什么意思。
我们在寻找最优解的过程也就是在使得损失函数值最小的theta1,theta2。
上述两幅图代码的是损失函数的等高线。
我们很容易看出,当数据没有归一化的时候,面积数的范围可以从0~1000,房间数的范围一般为0~10,可以看出面积数的取值范围远大于房间数。
影响
这样造成的影响就是在画损失函数的时候,
数据没有归一化的表达式,可以为:
J=(600\theta _{1}+ 3\theta _{2}-y_{correct} )^{2}
造成图像的等高线为类似椭圆形状,最优解的寻优过程就是像下图所示:

而数据归一化之后,损失函数的表达式可以表示为:
J=(0.55\theta _{1}+ 0.5\theta _{2}-y_{correct} )^{2}
其中变量的前面系数几乎一样,则图像的等高线为类似圆形形状,最优解的寻优过程像下图所示:


从上可以看出,数据归一化后,最优解的寻优过程明显会变得平缓,更容易正确的收敛到最优解。
这也是数据为什么要归一化的一个原因。
上面的梯度方向都应该和等高线方向,因为找不到原图,文字进行修正一下。