欢迎来到 Daily-DearnLearning,原本这是一个为了自己打造的深度学习知识库(⬇️滑到最下面或者看目录,可以看以前的和机器学习、深度学习相关的内容),涵盖计算机基础课程、Python快速入门、数据科学包的使用、机器学习、深度学习、自然语言处理、LLM等。
我在17年的时候就根据Google的《Attention is all you need》做了一些学习、复现,那会已经快毕业了,舍友问我:“你觉得NLP什么时候能成熟?”,我当时信誓旦旦的说:“至少得几十年吧。”,后来阴差阳错没有做算法的工作,跌跌撞撞进了体制内。2018年,Bert刚出现,当时还在想,怎么NLP也要学图像开始做大力出奇迹的事情了吗,再后来Elmo、GPT-2,再到chatGPT的效果出现了爆炸式的提升,我有点按耐不住了,人工智能的斯普特尼克时刻(Sputnik moment)真的要来了吗。打算从头和大家一起学习,回到这个令人兴奋的领域。(24年11、12月开始关注deepseek,结果25年的1月R1发布之后,在全球大火,这个奇点时刻似乎越来越近了)
纠结了一阵子,要不要把Daily-DeepLearning改成Daily-LLM,想了想还是算了吧,反正现在都是基于deeplearning。
出现的背景
要说LLM,大家第一反应应该都是《Attention is all you need》这篇论文了吧。在那之前,因为李飞飞教授推动的ImageNet数据集、GPU算力的提升,那时像CNN刚刚开始流行起来,多少人入门都是用Tensoflow或者Theano写一个手写数字识别。后来开始有人在NLP领域,用word2vec和LSTM的组合,在很多领域里做到SOTA的效果。后来就是2017年,由Google团队提出的这篇里程碑式的论文。
直接看文档
到底创新的什么?
第一个是模型的主体结构不再是CNN、RNN的变种,用了用self-Attention为主的Transformer结构,所以这篇论文的标题才会说这是all you need嘛。这种方法解决了无法并行计算并且长距离捕捉予以的问题。自注意力机制解析
第二个是多头注意力机制Multi-Head Attention,把输入映射到多个不同的空间,并行计算注意力,有点像CV的RGB、进阶版的词向量的感觉,捕捉不同维度的语义信息,比如语法、语意、上下文信息等等。多头注意力机制解析
第三个是用了位置编码Positional Encoding,这个点很巧妙,因为以前RNN、Lstm输入的时候是顺序输入的,虽然慢,但是正是这种序列化的表示。位置编码机制解析
PS:如果对编码不太了解,可以看看以前的编码方式,比如机器学习时期的词袋模型TF-IDF 或者深度学习时期的词向量
Transformer接下来要出现好几年
如果这三个核心点都理解了,我们可以开始看看整个Transformer的结构。如果你以前习惯了RNN/LSTM的结构,对于这种全新的架构会有点懵逼。其实整个结构很干净,没有什么花里胡哨的。用我的理解方式就是,首先有两个部分Encoder和Decoder。Encoder是用来提取输入序列的特征,Decoder是生成输出序列。比如在翻译任务中,Encoder处理源语言,Decoder生成目标语言。(Encoder可以并行处理所有输入,Decoder和Lstm类似,每一步是依赖之前的输出的)Transformer解析
PS:除了核心的创新外,里面还是用到了前馈神经网络、残差连接、层归一化这些以前的技术。
举个栗子
以机器翻译为例
# Encoder
输入序列:["我", "爱", "自然语言处理"]
↓
词嵌入 + 位置编码 → [向量1, 向量2, 向量3]
↓
经过6个编码器层的处理:
每个层包含:
1. 多头自注意力(关注整个输入序列)
2. 前馈神经网络(特征变换)
3. 残差连接 + 层归一化
↓
输出上下文表示:包含"我-爱-处理"关系的综合特征矩阵
# Decoder
已生成部分:["I"]
↓
输入:["<start>", "I"](起始符 + 已生成词)
↓
经过6个解码器层的处理:
每个层包含:
1. 掩码多头注意力(仅关注已生成部分)
2. 编码-解码注意力(连接编码器输出)
3. 前馈神经网络
4. 残差连接 + 层归一化
↓
预测下一个词:"love"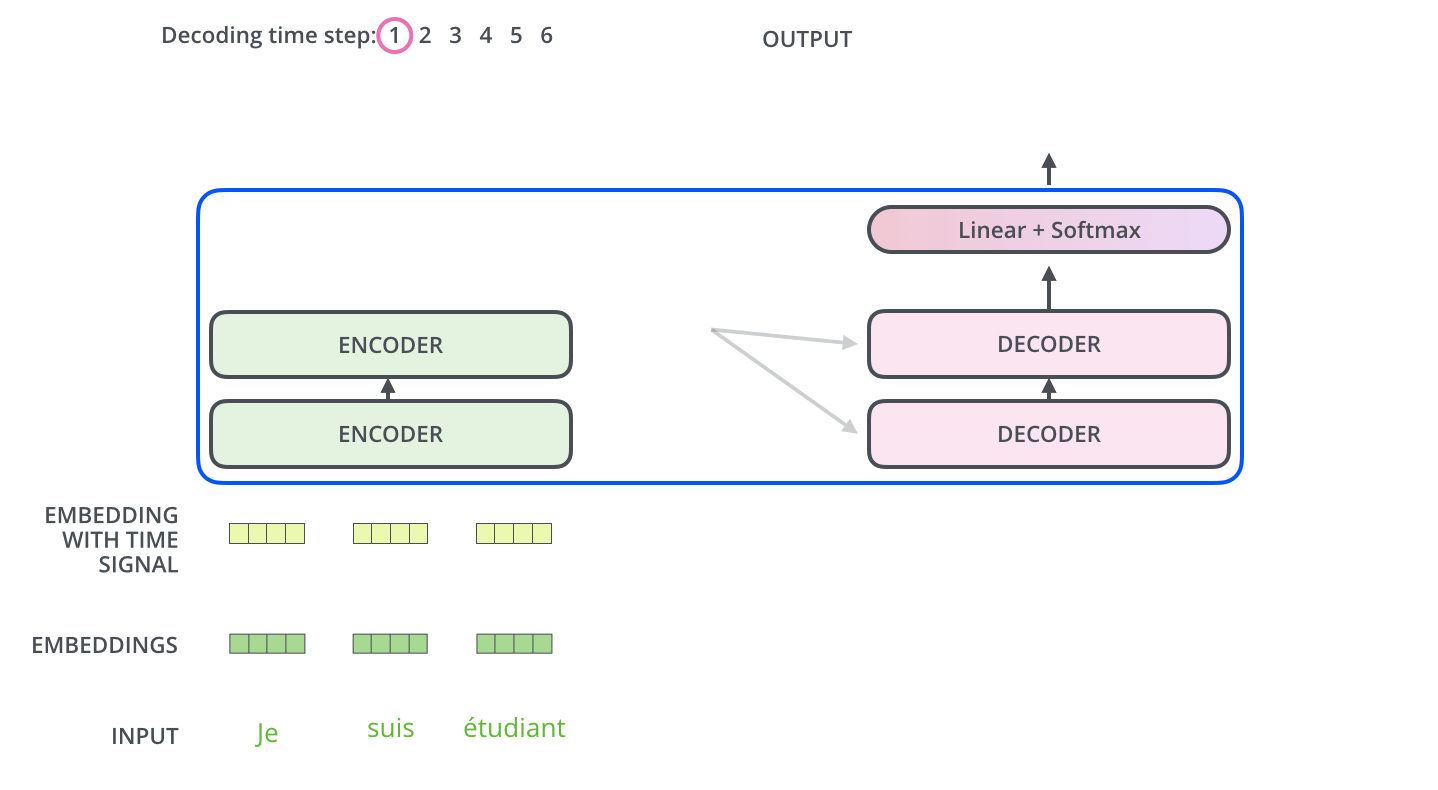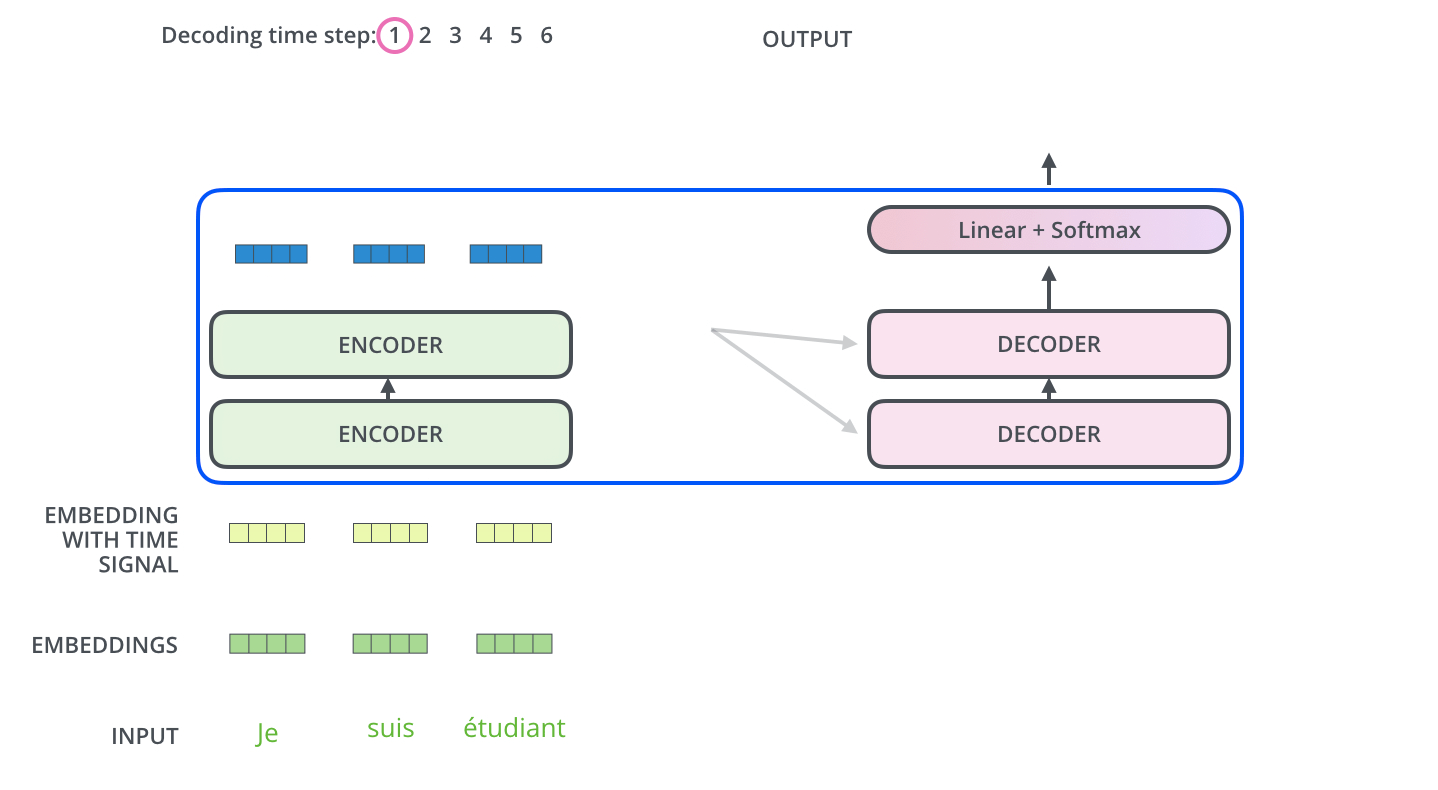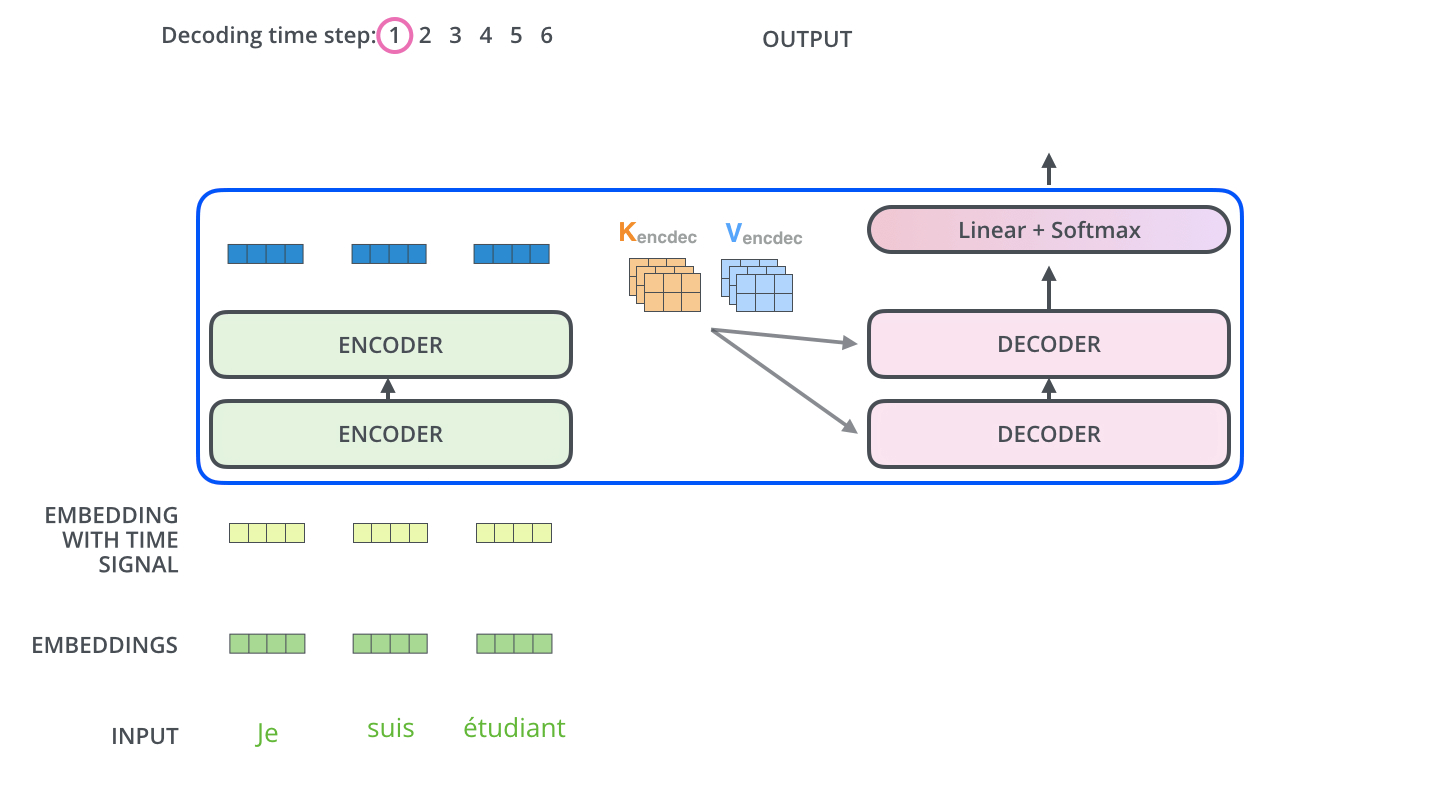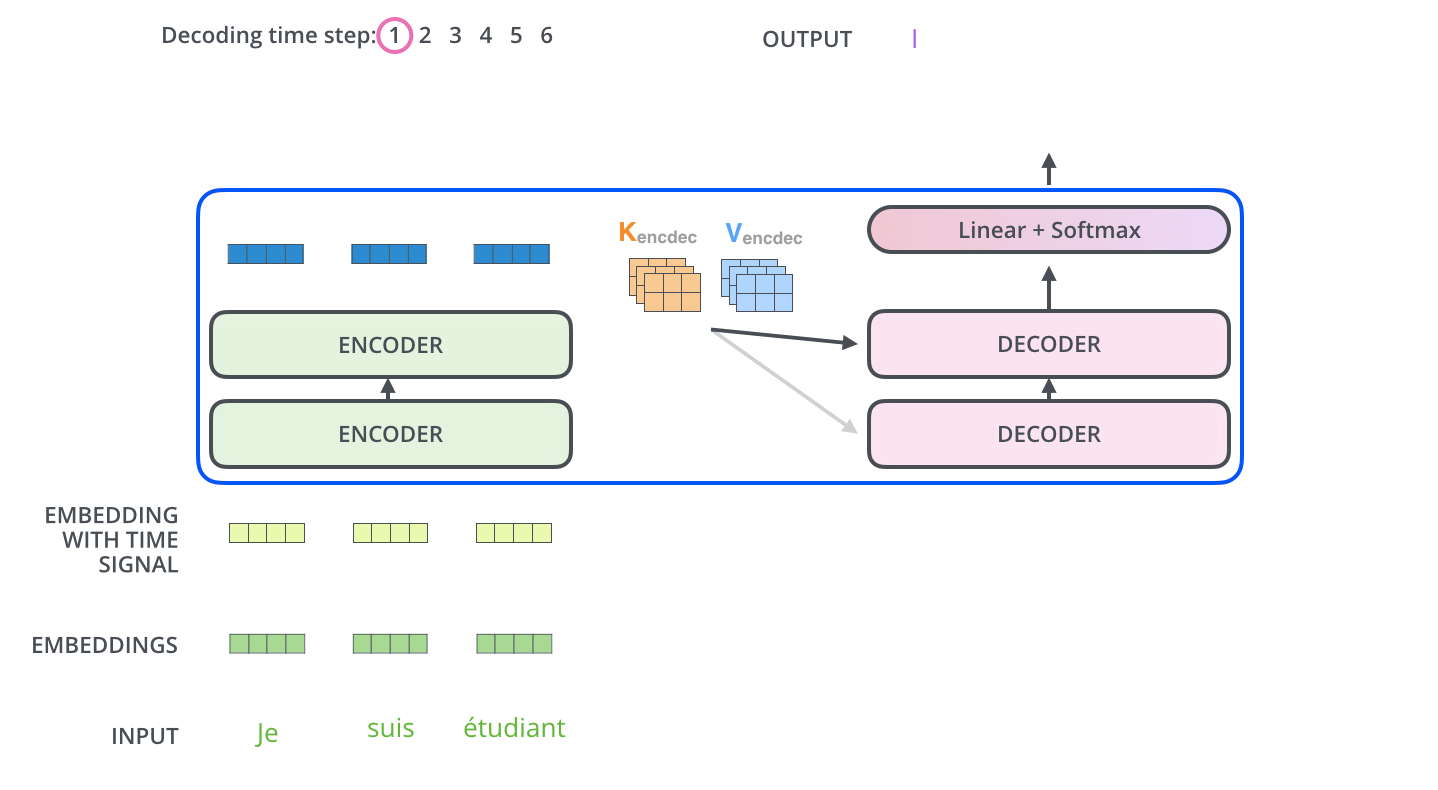
通过这个图,基本上能理解Transformer的90%了,有一个比较特殊的点是Decoder的掩码注意力机制。Decoder在生成目标序列的时候,是自回归的,也就是一个一个词生成的。比如在翻译的时候,先生成第一个词,然后用第一个词生成第二个词,依此类推。这时候在训练的时候,怎么确保解码器不会看到未来的信息呢?比如在预测第三个词的时候,模型不应该知道第三个词之后的正确答案,否则会导致信息泄漏,影响模型的泛化能力。
到底什么是注意力机制
这时候就需要掩码注意力机制了。掩码的作用应该是掩盖掉当前位置之后的位置,使得在计算注意力权重的时候,后面的位置不会被考虑到。具体来说,在自注意力计算的时候,生成一个上三角矩阵,对角线以上的元素设置为负无穷或者一个很小的数,这样在softmax之后,这些位置的权重就会接近零。

比如,对于一个长度为4的序列,掩码矩阵可能如下:
[[0, -inf, -inf, -inf],
[0, 0, -inf, -inf],
[0, 0, 0, -inf],
[0, 0, 0, 0]] # 0表示保留,-inf表示掩盖当计算注意力时,每个位置只能看到自己和前面的位置。例如,第二个位置只能关注第一个和第二个位置,第三个位置可以关注前三个,依此类推。掩码解析
自从Transformer架构提出后,在NLP领域开始涌现出了一系列有意思的工作。
完整的复现推荐这个Harvard NLP PyTorch实现Transformer
我们也可以使用BLEU数据集进行简单的复现Transformer复现
论文戳这里:BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Bert比较特殊的地方在于采用了双向上下文建模,通过掩码语言模型(Masked language Model),同时利用左右两侧上下文,解决传统模型中的单向性问题。还有很重要的一点,从Bert看来是,形成了“预训练+微调”的新范式,统一了多种NLP任务的框架,仅需在预训练模型基础上添加简单任务头即可适配下游任务。当时在11项NLP任务上刷新SOTA,开启了大规模预训练模型(Pre-trained Language Model, PLM)时代。Bert解析
Bert的双向上下文建模改变了文本表示的学习方式,通过Transformer的编码器结构同时捕捉文本中每个词的左右两侧上下文信息,从而更全面地理解语言语义。
输入表示上使用词嵌入(WordPiece) + 位置嵌入(Position) + 段落嵌入(Segment)
整体模型:
输入层 → Embedding → Transformer Encoder × L → 输出层- 输入层:将文本转化成768维向量(BERT-base)
- Encoder层数:BERT-base(L=12)、BERT-large(L=24)
- 输出层:根据任务选择输出形式(如
[CLS]向量用于分类)
单层 Encoder 的详细计算流程:
输入向量 → LayerNorm → 多头自注意力 → 残差连接 → LayerNorm → 前馈网络 → 残差连接 → 输出我们可以使用BLEU数据集进行简单的复现Bert复现
论文戳这里ELMo:Embeddings from Language Models
ELMo这个工作主要还是对词向量的改进,从静态的词向量转变成动态词向量,从而提升各项NLP任务上的性能。虽然和GPT、BERT在同一年的工作,但其实应该放在这两项工作前面的,从马后炮的角度来说,主要用的还是双向LSTM,相较于Transformer这样支持并行计算的架构,再配合上MLM来捕捉双向上下文,现在看起来更像是上一代的产物了。但对比起word2vec、GloVe等静态词向量,还是不知道高到哪里去了。
数据结构
操作系统
计算机网络
Day01: 变量、字符串、数字和运算符
Day02: 列表、元组
Day03: 字典、集合
Day04: 条件语句、循环
Day05: 函数的定义与调用
Day06: 迭代、生成器、迭代器
Day07: 高阶函数、装饰器
Day08: 面向对象编程
Day09: 类的高级特性
Day10: 错误处理与调试
Day11: 文件操作
Day12: 多线程与多进程
Day13: 日期时间、集合、结构体
Day14: 协程与异步编程
Day15: 综合实践
NumPy
Pandas
Matplotlib
理论
- 逻辑回归
- EM 算法
- 集成学习
- 随机森林与 GBDT
- ID3/C4.5 算法
- K-means
- K 最近邻
- 贝叶斯
- XGBoost/LightGBM
- Gradient Boosting
- Boosting Tree
- 回归树
- XGBoost
- GBDT 分类
- GBDT 回归
- LightGBM
- CatBoost
实战
- NumPy 实战:创建 ndarray
- Pandas 实战:加载数据
- Matplotlib 实战:直线图
理论
实战
如果你有任何问题或建议,欢迎通过以下方式联系我们: