Folders and files Name Name Last commit message
Last commit date
parent directory Feb 24, 2023
Aug 16, 2022
Feb 25, 2023
Aug 16, 2022
View all files
01.基础概念介绍
02.常见思路和做法
03.Api调用说明
04.遇到的坑分析
05.其他问题说明
内存缓存:
通过预先消耗应用的一点内存来存储数据,便可快速的为应用中的组件提供数据,是一种典型的以空间换时间的策略。
内存缓存:存储在内存中,如果对象销毁则内存也会跟随销毁。如果是静态对象,那么进程杀死后内存会销毁。
Map,LruCache等等,其实可以想象集合存储的对象,就是一种有生命周期的内存缓存!
缓存的大小有限,当缓存被用满时,哪些数据应该被清理出去,哪些数据应该被保留?这就需要缓存淘汰策略来决定。
常见的策略有三种:先进先出策略 FIFO、最少使用策略 LFU、最近最少使用策略 LRU。
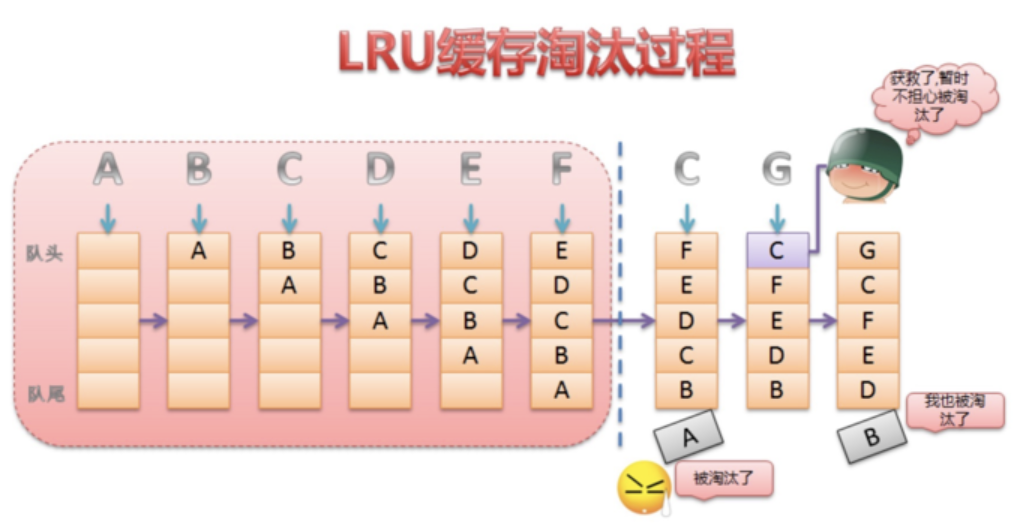
LRU是近期最少使用的算法,它的核心思想是当缓存满时,会优先淘汰那些近期最少使用的缓存对象。
LruCache的淘汰策略简单说明
将LinkedHashMap中的默认顺序设置为访问顺序,每次调用get,则将该对象移到链表的头部,调用put插入新的对象到链表头部。
当内存缓存达到最大值时,就将链表尾部的对象移除。每次put或者remove,都需要判断缓存大小是否足够trimToSize。
LinkedHashMap源码解读
如何度量缓存单元的内存占用?
缓存系统应该实时记录当前的内存占用量,在添加数据时增加内存记录,在移除或替换数据时减少内存记录,这就涉及 “如何度量缓存单元的内存占用” 的问题。
计数 or 计量,这是个问题。比如说:
举例 1: 实现图片内存缓存,如何度量一个图片资源的内存占用?
举例 2: 实现数据模型对象内存缓存,如何度量一个数据模型对象的内存占用?
举例 3: 实现资源内存预读,如何度量一个资源的内存占用?
将这个问题总结为 2 种情况:
1、能力复用使用计数: 这类内存缓存场景主要是为了复用对象能力,对象本身持有的数据并不多。而且,再加上引用复用的因素,很难统计对象实际的内存占用。因此,这类内存缓存场景应该使用计数,只统计缓存单元的个数,例如复用数据模型对象,资源预读等;
2、数据复用使用计量: 这类内存缓存场景主要是为了复用对象持有的数据,数据对内存的影响远远大于对象内存结构对内存的影响,是否度量除了数据外的部分内存对缓存几乎没有影响。因此, 这里内存缓存场景应该使用计量,不计算缓存单元的个数,而是计算缓存单元中主数据字段的内存占用量,例如图片的内存缓存就只记录 Bitmap 的像素数据内存占用。
对象内存结构中的对象头和对齐空间需要计算在内吗?
一般不考虑,因为在大部分业务开发场景中,相比于对象的实例数据,对象头和对齐空间的内存占用几乎可以忽略不计。
使用计数策略
1、Message 消息对象池:最多缓存 50 个对象
2、OkHttp 连接池:默认最多缓存 5 个空闲连接
3、数据库连接池
使用计量策略
最大缓存容量应该设置多大?
网上很多资料都说使用最大可用堆内存的八分之一,这样笼统地设置方式显然并不合理。到底应该设置多大的空间没有绝对标准的做法,而是需要开发者根据具体的业务优先级、用户机型和系统实时的内存紧张程度做决定:
具体该怎么去合理设置
业务优先级: 如果是高优先级且使用频率很高的业务场景,那么最大缓存空间适当放大一些也是可以接受的,反之就要考虑适当缩小;
用户机型: 在最大可用堆内存较小的低端机型上,最大缓存空间应该适当缩小;
内存紧张程度: 在系统内存充足的时候,可以放大一些缓存空间获得更好的性能,当系统内存不足时再及时释放。
讨论一个经典的应用场景,那就是+LRU+缓存淘汰算法。
缓存是一种提高数据读取性能的技术,在硬件设计、软件开发中都有着非常广泛的应用,比如常见的+CPU+缓存、数据库缓存、浏览器缓存、图片缓存等等。
举一个实际案例
假如说,你买了很多本技术书,但有一天你发现,这些书太多了,太占书房空间了,你要做个大扫除,扔掉一些书籍。那这个时候,你会选择扔掉哪些书呢?对应一下,你的选择标准是不是和上面的三种策略神似呢?
可以定义一个缓存系统的基本操作:
操作 1 - 添加数据: 先查询数据是否存在,不存在则添加数据,存在则更新数据,并尝试淘汰数据;
操作 2 - 删除数据: 先查询数据是否存在,存在则删除数据;
操作 3 - 查询数据: 如果数据不存在则返回 null;
操作 4 - 淘汰数据: 添加数据时如果容量已满,则根据缓存淘汰策略一个数据。
那么如何提高缓存中的查询效率:
前 3 个操作都有 “查询” 操作,所以缓存系统的性能主要取决于查找数据和淘汰数据是否高效。
为了实现高效的 LRU 缓存结构,会选择采用双向链表 + 散列表的数据结构,也叫 “哈希链表”,它能够将查询数据和淘汰数据的时间复杂度降低为 O(1)。
查询数据: 通过散列表定位数据,时间复杂度为 O(1);淘汰数据: 直接淘汰链表尾节点,时间复杂度为 O(1)。
如何实现LRU库
在 Java 标准库中,已经提供了一个通用的哈希链表 —— LinkedHashMap。
使用 LinkedHashMap 时,主要关注 2 个 API:
accessOrder 标记位: LinkedHashMap 同时实现了 FIFO 和 LRU 两种淘汰策略,默认为 FIFO 排序,可以使用 accessOrder 标记位修改排序模式。
removeEldestEntry() 接口: 每次添加数据时,LinkedHashMap 会回调 removeEldestEntry() 接口。开发者可以重写 removeEldestEntry() 接口决定是否移除最早的节点(在 FIFO 策略中是最早添加的节点,在 LRU 策略中是最久未访问的节点)。
LruCache 添加数据的过程基本是复用 LinkedHashMap 的添加过程,将过程概括为 6 步:
1、统计添加计数(putCount);
2、size 增加新 Value 内存占用;
3、设置数据(LinkedHashMap#put);
4、size 减去旧 Value 内存占用;
5、数据移除回调(LruCache#entryRemoved);
6、自动淘汰数据:在每次添加数据后,如果当前缓存空间超过了最大缓存容量限制,则会自动触发 trimToSize() 淘汰一部分数据,直到满足限制。
淘汰数据的过程则是完全自定义,将过程概括为 5 步:
1、取最找的数据(LinkedHashMap#eldest);
2、移除数据(LinkedHashMap#remove);
3、size 减去旧 Value 内存占用;
4、统计淘汰计数(evictionCount);
5、数据移除回调(LruCache#entryRemoved);
创建LruCache对象
private SystemLruCache <String , String > lruCache = new SystemLruCache <>(100 );
LruCache常见Api说明
//获取数据
lruCache .get ("lru" );
//判断是否包含数据
lruCache .containsKey ("lru" );
//移除数据
lruCache .remove ("lru" );
//最大的长度
int i = lruCache .maxSize ();
//拷贝一份数据
Map <String , String > snapshot = lruCache .snapshot ();
//清除数据
lruCache .clear ();
//获取健值对
Set <String > keySet = lruCache .keySet ();
如何测量数据单元的内存占用
开发者需要重写 SystemLruCache#sizeOf() 测量缓存单元的内存占用量,否则缓存单元的大小默认视为 1,相当于 maxSize 表示的是最大缓存数量。
使用示例如下所示
private static final int CACHE_SIZE = 4 * 1024 * 1024 ; // 4Mib
SystemLruCache bitmapCache = new SystemLruCache (CACHE_SIZE ){
// 重写 sizeOf 方法,用于测量 Bitmap 的内存占用
@ Override
protected int sizeOf (String key , Bitmap value ) {
return value .getByteCount ();
}
};
淘汰一个最早的节点就足够吗?
标准的 LRU 策略中,每次添加数据时最多只会淘汰一个数据,但在 LRU 内存缓存中,只淘汰一个数据单元往往并不够。
例如在使用 “计量” 的内存图片缓存中,在加入一个大图片后,只淘汰一个图片数据有可能依然达不到最大缓存容量限制。
那么在LRUCache该如何做呢?
在复用 LinkedHashMap 实现 LRU 内存缓存时,前文提到的 LinkedHashMap#removeEldestEntry() 淘汰判断接口可能就不够看了,因为它每次最多只能淘汰一个数据单元。
LruCache是如何解决这个问题
这个地方就需要重写LruCache中的sizeOf()方法,然后拿到key和value对象计算其内存大小。
LruCache策略能否增加灵活性
LruCache 的淘汰策略是在缓存容量满时淘汰,当缓存容量没有超过最大限制时就不会淘汰。除了这个策略之外,还可以增加一些辅助策略,例如在 Java 堆内存达到某个阈值后,对 LruCache 使用更加激进的清理策略。
淘汰灵活性的模仿案例
在 Android Glide 图片框架中就有策略灵活性的体现:Glide 除了采用 LRU 策略淘汰最早的数据外,还会根据系统的内存紧张等级 onTrimMemory(level) 及时减少甚至清空 LruCache。
首先搞清楚一个问题
一个缓存系统往往会在多线程环境中使用,而 LinkedHashMap 与 HashMap 都不考虑线程同步,也会存在线程安全问题。
那么如何保证LruCache的线程安全
在put,get等核心方法中,添加synchronized锁。这里主要是synchronized (this){ put操作 },
锁住的是该对象,类的其中一个实例,当该对象(仅仅是这一个对象)在不同线程中执行这个同步方法时,线程之间会形成互斥。达到同步效果。
但如果不同线程同时对该类的不同对象执行这个同步方法时,则线程之间不会形成互斥,因为他们拥有的是不同的锁。
Android 内存缓存框架 LruCache 的实现原理,手写试试?
You can’t perform that action at this time.

{kind=link}