Consume double GPU memory while using pytorch built-in amp module starting from the second epoch #610
Comments
|
Hello @tkianai, thank you for your interest in our work! Please visit our Custom Training Tutorial to get started, and see our Jupyter Notebook If this is a bug report, please provide screenshots and minimum viable code to reproduce your issue, otherwise we can not help you. If this is a custom model or data training question, please note Ultralytics does not provide free personal support. As a leader in vision ML and AI, we do offer professional consulting, from simple expert advice up to delivery of fully customized, end-to-end production solutions for our clients, such as:
For more information please visit https://www.ultralytics.com. |
|
@tkianai I can't comment on this as I don't often employ multi-gpu, but I believe excess device 0 memory consumption has been common for a while. I don't know if this is specific to this repository or pytorch DDP in general. I would probably not classify as a bug. |
|
@glenn-jocher Hi, thanks for your explanation. I just wonder My environment(ubuntu18.04, pytorch 1.6.0, cuda 10.2, TitanXp) Compared to commit 0/299 1.77G 0.08957 0.08007 0.08078 0.2504 23 640: 100%|██████████████| 925/925 [05:11<00:00, 2.97it/s]
Class Images Targets P R mAP@.5 mAP@.5:.95: 100%|████| 40/40 [01:25<00:00, 2.14s/it]
all 5e+03 3.63e+04 0.0609 0.00288 0.00829 0.00234
Epoch gpu_mem GIoU obj cls total targets img_size
1/299 8.31G 0.0737 0.07986 0.06731 0.2209 21 640: 100%|██████████████| 925/925 [05:01<00:00, 3.07it/s]
Class Images Targets P R mAP@.5 mAP@.5:.95: 100%|████| 40/40 [01:20<00:00, 2.00s/it]
all 5e+03 3.63e+04 0.126 0.0581 0.0457 0.0168
Epoch gpu_mem GIoU obj cls total targets img_size
2/299 8.36G 0.07015 0.07251 0.06002 0.2027 188 640: 3%|▍ | 26/925 [00:09<04:55, 3.04it/s]+-----------------------------------------------------------------------------+
| NVIDIA-SMI 440.82 Driver Version: 440.82 CUDA Version: 10.2 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 TITAN Xp Off | 00000000:04:00.0 Off | N/A |
| 45% 74C P2 231W / 250W | 8609MiB / 12196MiB | 73% Default |
+-------------------------------+----------------------+----------------------+
| 1 TITAN Xp Off | 00000000:06:00.0 Off | N/A |
| 51% 82C P2 95W / 250W | 5413MiB / 12196MiB | 99% Default |
+-------------------------------+----------------------+----------------------+
| 2 TITAN Xp Off | 00000000:07:00.0 Off | N/A |
| 49% 79C P2 95W / 250W | 5423MiB / 12196MiB | 97% Default |
+-------------------------------+----------------------+----------------------+
| 3 TITAN Xp Off | 00000000:08:00.0 Off | N/A |
| 52% 83C P2 261W / 250W | 5415MiB / 12196MiB | 75% Default |
+-------------------------------+----------------------+----------------------+
| 4 TITAN Xp Off | 00000000:0C:00.0 Off | N/A |
| 50% 80C P2 100W / 250W | 5415MiB / 12196MiB | 83% Default |
+-------------------------------+----------------------+----------------------+
| 5 TITAN Xp Off | 00000000:0D:00.0 Off | N/A |
| 41% 70C P2 240W / 250W | 5413MiB / 12196MiB | 74% Default |
+-------------------------------+----------------------+----------------------+
| 6 TITAN Xp Off | 00000000:0E:00.0 Off | N/A |
| 50% 81C P2 90W / 250W | 5413MiB / 12196MiB | 74% Default |
+-------------------------------+----------------------+----------------------+
| 7 TITAN Xp Off | 00000000:0F:00.0 Off | N/A |
| 52% 84C P2 249W / 250W | 5413MiB / 12196MiB | 99% Default |
+-------------------------------+----------------------+----------------------+ |
|
@tkianai oh that's odd. In our experiments we found native amp with 1.6 to use a little less GPU ram, which allowed us to increase batch size maybe 10%, allowing for a bit of speed up (maybe 5%-10%). We have not tested on multi-gpu however. It looks like you see similar GPU memory reduction as we saw, perhaps this would allow you to up your batch size some. I don't know if there is anything you can do about the device 0 mem usage, but that seems to be a separate issue, which may or may not have a solution. You might want to raise an issue on the pytorch repo for that one. |
|
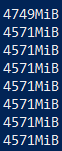
A bit excess device 0 should be expected (<1-2GB). I think this is related to the I did my own quick test using your command. Numbers taken at second epoch.
@tkianai , I recommend using Edit: See below comment for better visuals. The above table may be skewed. |
|
One minor cause is the EMA, which is resident on device 0, but this should only be a few hundred MB at most. For v5x, with 90M parameters, even as FP32 that would be 4 bytes * 90M = 360MB. The rest I'm not really sure. Testing is device 0, but once the test.py function exits all the cuda variables should be cleared there and no longer consuming memory. If @tkianai is saying that epoch 0 is different from epoch >0 though, then the call to test.py could be the differentiator. In that sense it is suspect. |
|
@NanoCode012 Yes, using multi-gpu training with the same |
Oh I see!
On 1.6,
@glenn-jocher , hope this provides better visualization. @tkianai , do you get the same results? Edit: Add table |






|
@glenn-jocher @NanoCode012 Hi, It seems the
The printed logs listed as follows: Starting training for 300 epochs...
Epoch gpu_mem GIoU obj cls total targets img_size
0/299 2.9G 0.08759 0.0743 0.08098 0.2429 10 640: 100%|██████████████████| 925/925 [06:14<00:00, 2.47it/s]
Epoch gpu_mem GIoU obj cls total targets img_size
1/299 2.94G 0.07263 0.07433 0.06655 0.2135 9 640: 100%|██████████████████| 925/925 [06:03<00:00, 2.55it/s]
Epoch gpu_mem GIoU obj cls total targets img_size
2/299 2.94G 0.06974 0.07265 0.0598 0.2022 153 640: 7%|█▍ | 69/925 [00:28<05:34, 2.56it/s]+-----------------------------------------------------------------------------+
| NVIDIA-SMI 440.82 Driver Version: 440.82 CUDA Version: 10.2 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 TITAN Xp Off | 00000000:04:00.0 Off | N/A |
| 45% 72C P2 214W / 250W | 3457MiB / 12196MiB | 79% Default |
+-------------------------------+----------------------+----------------------+
| 1 TITAN Xp Off | 00000000:06:00.0 Off | N/A |
| 53% 83C P2 206W / 250W | 3423MiB / 12196MiB | 97% Default |
+-------------------------------+----------------------+----------------------+
| 2 TITAN Xp Off | 00000000:07:00.0 Off | N/A |
| 51% 80C P2 232W / 250W | 3423MiB / 12196MiB | 90% Default |
+-------------------------------+----------------------+----------------------+
| 3 TITAN Xp Off | 00000000:08:00.0 Off | N/A |
| 53% 83C P2 213W / 250W | 3423MiB / 12196MiB | 96% Default |
+-------------------------------+----------------------+----------------------+
| 4 TITAN Xp Off | 00000000:0C:00.0 Off | N/A |
| 52% 82C P2 128W / 250W | 3423MiB / 12196MiB | 83% Default |
+-------------------------------+----------------------+----------------------+
| 5 TITAN Xp Off | 00000000:0D:00.0 Off | N/A |
| 43% 69C P2 96W / 250W | 3423MiB / 12196MiB | 87% Default |
+-------------------------------+----------------------+----------------------+
| 6 TITAN Xp Off | 00000000:0E:00.0 Off | N/A |
| 53% 83C P2 157W / 250W | 3423MiB / 12196MiB | 82% Default |
+-------------------------------+----------------------+----------------------+
| 7 TITAN Xp Off | 00000000:0F:00.0 Off | N/A |
| 53% 83C P2 231W / 250W | 3423MiB / 12196MiB | 88% Default |
+-------------------------------+----------------------+----------------------+
The printed logs listed as follows: Starting training for 300 epochs...
0/299 1.77G 0.08925 0.08011 0.0807 0.2501 23 640: 100%|██████████████████| 925/925 [05:16<00:00, 2.93it/s]
Epoch gpu_mem GIoU obj cls total targets img_size
1/299 5.2G 0.07356 0.07901 0.06713 0.2197 33 640: 100%|██████████████████| 925/925 [05:06<00:00, 3.01it/s]
Epoch gpu_mem GIoU obj cls total targets img_size
2/299 5.2G 0.07061 0.07835 0.06183 0.2108 222 640: 10%|█▊ | 89/925 [00:32<04:31, 3.08it/s]+-----------------------------------------------------------------------------+
| NVIDIA-SMI 440.82 Driver Version: 440.82 CUDA Version: 10.2 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 TITAN Xp Off | 00000000:04:00.0 Off | N/A |
| 46% 73C P2 166W / 250W | 5637MiB / 12196MiB | 90% Default |
+-------------------------------+----------------------+----------------------+
| 1 TITAN Xp Off | 00000000:06:00.0 Off | N/A |
| 53% 83C P2 211W / 250W | 5603MiB / 12196MiB | 83% Default |
+-------------------------------+----------------------+----------------------+
| 2 TITAN Xp Off | 00000000:07:00.0 Off | N/A |
| 51% 80C P2 212W / 250W | 5413MiB / 12196MiB | 100% Default |
+-------------------------------+----------------------+----------------------+
| 3 TITAN Xp Off | 00000000:08:00.0 Off | N/A |
| 53% 83C P2 194W / 250W | 5413MiB / 12196MiB | 64% Default |
+-------------------------------+----------------------+----------------------+
| 4 TITAN Xp Off | 00000000:0C:00.0 Off | N/A |
| 52% 82C P2 259W / 250W | 5415MiB / 12196MiB | 99% Default |
+-------------------------------+----------------------+----------------------+
| 5 TITAN Xp Off | 00000000:0D:00.0 Off | N/A |
| 44% 70C P2 221W / 250W | 5413MiB / 12196MiB | 77% Default |
+-------------------------------+----------------------+----------------------+
| 6 TITAN Xp Off | 00000000:0E:00.0 Off | N/A |
| 53% 82C P2 263W / 250W | 5413MiB / 12196MiB | 97% Default |
+-------------------------------+----------------------+----------------------+
| 7 TITAN Xp Off | 00000000:0F:00.0 Off | N/A |
| 57% 84C P2 285W / 250W | 5413MiB / 12196MiB | 83% Default |
+-------------------------------+----------------------+----------------------+It eliminates the gpu memory from 5400Mb to 3400Mb, which works well. But, it looks like using a little much longer time to train(5 minutes to 6 minutes per epoch) |
|
@tkianai @NanoCode012 I'm updating this issue with comments from a recent PR.
And my own observations was no additional GPU memory consumption on device 2 when using 2 GPU training, during either training or testing on epoch 0 or any subsequent epochs:
|
I have encountered this problem while running
python -m torch.distributed.launch --nproc_per_node 8 train.py --batch-size 128 --data coco.yaml --cfg yolov5s.yaml --weights ''with the code of the latest version.The logs printed as follows:
Epoch gpu_mem GIoU obj cls total targets img_size 0/299 3.54G 0.0874 0.0744 0.081 0.2428 10 640: 100%|█████████████████| 925/925 [05:45<00:00, 2.68it/s] Class Images Targets P R mAP@.5 mAP@.5:.95: 100%|███████| 40/40 [01:31<00:00, 2.28s/it] all 5e+03 3.63e+04 0.0336 0.00589 0.00874 0.00232 Epoch gpu_mem GIoU obj cls total targets img_size 1/299 8.08G 0.07261 0.0743 0.06651 0.2134 37 640: 100%|█████████████████| 925/925 [05:41<00:00, 2.71it/s] Class Images Targets P R mAP@.5 mAP@.5:.95: 100%|███████| 40/40 [01:18<00:00, 1.95s/it] all 5e+03 3.63e+04 0.143 0.0414 0.0393 0.0145 Epoch gpu_mem GIoU obj cls total targets img_size 2/299 8.08G 0.06912 0.06453 0.06019 0.1938 211 640: 2%|▎ | 15/925 [00:10<05:50, 2.60it/s]The GPU states listed as follows:
The text was updated successfully, but these errors were encountered: