Open
Description
Environment
- Tesseract Version: v4.00.00dev-692-gad5ee18 with Leptonica
- Commit Number: ad5ee18
- Platform: MAC OS 16.7.0 Darwin Kernel Version 16.7.0: Thu Jun 15 17:36:27 PDT 2017; root:xnu-3789.70.16~2/RELEASE_X86_64 x86_64
Current Behavior:
Line 1, unexpected '__' recognized between 1941 and Ritter, with bbox as the entire page.
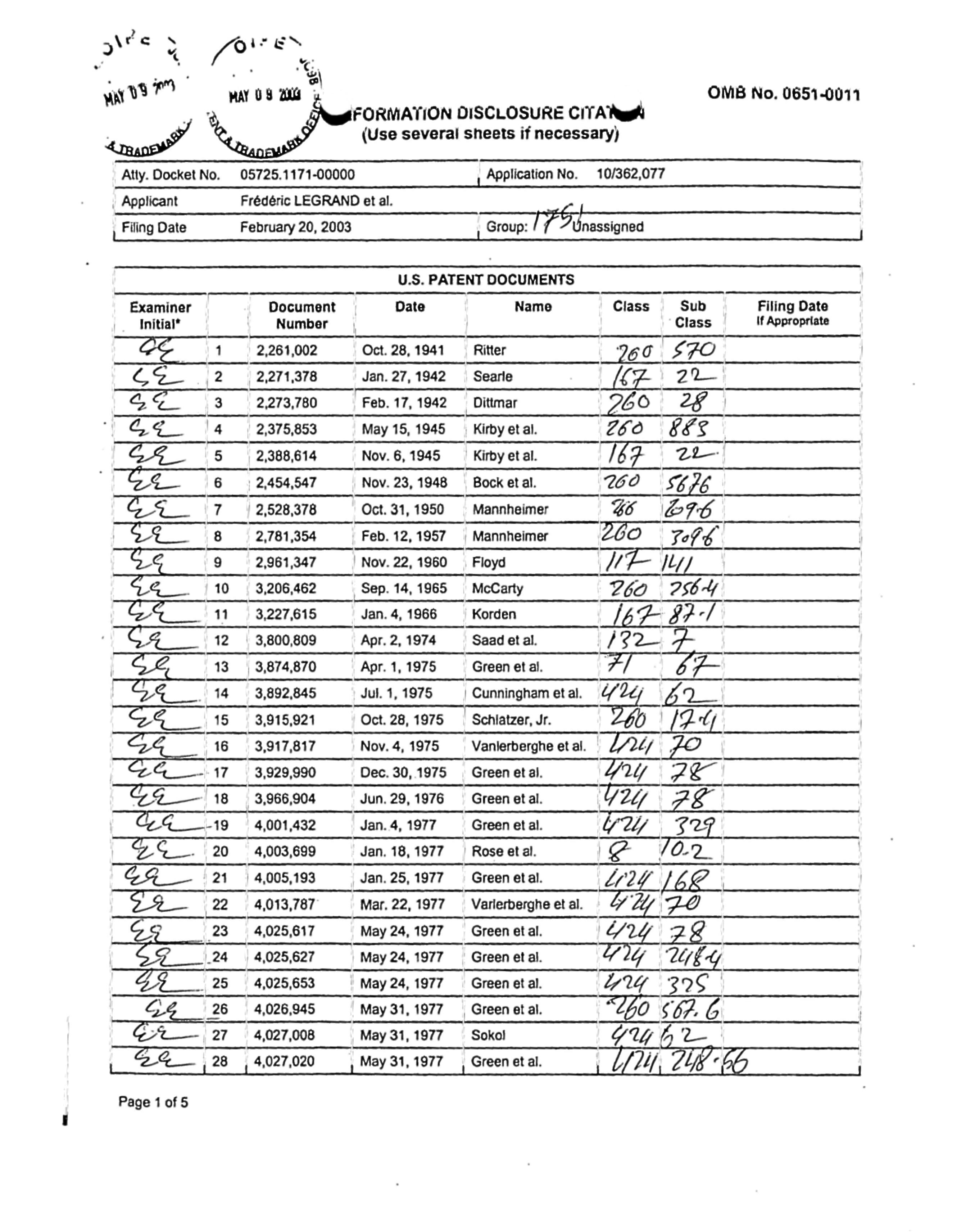
Corresponding HOCR line:
GS 1 2,261,002 Oct. 28,1941 __ Ritter 760 $FO
Expected Behavior:
'__' is not supposed to be recognized in the first place. If the false positive recognition is inevitable, the bbox information should be accurate.
Suggested Fix:
n/a
Activity
[-]Noise character recognized with bbox as the entire page[/-][+]Noise characters recognized with bbox as the entire page[/+]napasa commentedon Mar 26, 2018
When does this will be fixed?
Shreeshrii commentedon Mar 28, 2018
Comparing best and fast OCRed text
While
bestdoes not add__for the vertical bar in table to the OCRed txtfastdid not recognize,as part of the number string.Best
Fast
@zdenop Please label
accuracy
devendrasr commentedon Jun 27, 2018
@Shreeshrii How can we overcome this issue?
willaaam commentedon Sep 3, 2018
This is much more than an accuracy error - even for completely accurate words the bounding boxes make no sense at all, whether using TSV or HOCR output. This is pretty big for me.
The weird part is - somewhere internally it seems to know the coordinates as the word_ids are in order LTR and follow up.
Does anyone have any suggestion on where to start looking? I'm happy to hunt this down with some rusty C skills but I really need a pointer, completely unfamiliar with the tesseract codebase.
It happens with the LSTM engine, haven't been able to test with the legacy engine as tesseract won't recognize the retro traineddata file in the tessdata folder. I'll update this post when I get tesseract 4 --oem 0 working.
Still occurring on the very latest master build (e4b9cff)
Example of the error:
Also goes wrong when printing the character level info:
Sintun commentedon Sep 3, 2018
@willaaam
I am not sure if it's a problem of the tesseract console program or at the api level. If it's independet from the console program it's probably a variation of #1712. I also started looking at this problem. A pointer in order to track it down:
After an OCR run the result information can be extracted through a result Iterator
unique_ptr<tesseract::ResultIterator> ri( tess->GetIterator() );The bounding box of different detail
level(for exampletesseract::RIL_PARA,tesseract::RIL_TEXTLINE,tesseract::RIL_WORD,tesseract::RIL_SYMBOLalso known as paragraph, text line, word, character) can be obtained throughNow the bounding boxes on all levels are consistent, in some cases consistently false. So I would start with a minimal failing image by tracking down where the information from BoundingBox originates and where it goes wrong.
https://tesseract-ocr.github.io/4.0.0/a02399.html#aae57ed588b6bffae18c15bc02fbe4f68
Doing that is also on my ToDo list, but unfortunately i havn't found the time yet. And our Codebase "found" a temporary solution that lead to beautiful function names like
void tesseractBugFixingCharSizePlausibilityCheck();willaaam commentedon Sep 6, 2018
Thanks, I appreciate the pointer, let's see if I can make some time to track this down, hopefully with a friend of mine. This bug breaks all analytics applications that come after tesseract.
And I agree, also crossposted in #1712 so we can nip this one in the bud.
willaaam commentedon Sep 7, 2018
Quick update - we spent some time on this last night and the bug is definitely at the API level unfortunately.
Using the code below we notice that already using BoundingBoxInternal (code below was snapshotted an hour earlier and still using BoundingBox - but same results) we get whole-page coordinates for the boxes.
Inside the BoundingBoxInternal structure, at least for our sample code, cblob_it is always null, so thats where we are going to resume the hunt and check out the BlobBox.
Sample API test code below:
Sintun commentedon Sep 8, 2018
Hey there,
I also followed the path and got down the following lane:
BoundingBox -> BoundingBoxInternal -> restricted_bounding_box -> true_bounding_box -> TBOX WERD::bounding_boxAnd tracked every usage of
WERD::bounding_box,WERD::restricted_bounding_boxI saw, that the the bounding boxes are fine until the code reaches
Tesseract::RetryWithLanguagehttps://tesseract-ocr.github.io/4.0.0/a02479.html#a8952ab340e0f5e61992109e85cb1619c
Within this function the recognizer
(this->*recognizer)(word_data, in_word, &new_words);(which uses
LSTMRecognizeWord)https://tesseract-ocr.github.io/4.0.0/a01743.html#ac50ad7dad904ed14e81cd29a3bfdb82d
https://tesseract-ocr.github.io/4.0.0/a02479.html#a0478ee100b826566b0b9ea048eee636e
is applied.
Before it's application the word and character positions are good. (They are initialized before the lstm runs, so that sane regions can be fed into the lstm)
After this the resulting new word rectangles can have negative values & probably loose / gain characters at the word start / end.
Now there seem to be two possibilites
Considering, that
word_data.lang_words[ max_index + 1 ]->word->bounding_box();results into a bounding box with Points containing +/- 32767
Which usage would result in a boundingBox containing the whole image, after it got cropped down to the image borders,
I would hope, that this is a +/- 1 error on some pointer in the LSTM bounding box / blob index post processing.
Next time i will continue tracking the issue within
LSTMRecognizeWord.Update: I'm still closing in on this, reached
ExtractBestPathAsWords.FrkBo commentedon Sep 12, 2018
Don't know if the following is of any help... If you would comment out the following lines in ccstruct/pageres.cpp on lines 1311-1313
if (blob_it.at_first())
blob_it.set_to_list(next_word_blobs);
blob_end = (blob_box.right() + blob_it.data()->bounding_box().left()) / 2;
You would end up with a lot more lines where the bounding box is equal to the entire page. Maybe the previous if-statement >> if (!blob_it.at_first() || next_word_blobs != nullptr) << does not cover all applicable cases?
Update
Disabling the following line in pageres.cpp (line 1375) seems to 'solve' the issue or at least give better output for the incorrect bounding boxes, but previous 'correct' bounding boxes are changed (and not for the better...)
// Delete the fake blobs on the current word.
word_w->word->cblob_list()->clear();
Sintun commentedon Sep 16, 2018
Hey there,

I'm still working on this and traced the issue down to the character positions computed from the LSTM output. Unfortunately it seems to be more than an "one off" error.
For now i reached the function
RecodeBeamSearch::ExtractBestPathsinrecodebeam.cppDebug output from
RecodeBeamSearch::ExtractPathAsUnicharIdsshows, that
best_nodes[i]->duplicateandbest_nodes[i]->unichar_idare wrong, and off by more than one.Using the image
the letters u and s are attributed to the position of u and one of the L s gets the position of both L s.
Next time i will test the
ExtractBestPathsfunction and follow the source of the wrong values, it shouldn't be far away. I hope that i find the bug source before reaching the LSTM computations.58 remaining items