[STORM-886] Automatic Back Pressure (ABP) #700
Conversation
| backpressure.worker.low.watermark: 0.4 | ||
| backpressure.executor.high.watermark: 0.9 | ||
| backpressure.executor.low.watermark: 0.4 | ||
| backpressure.spout.suspend.time.ms: 100 |
There was a problem hiding this comment.
This seems way too high. It is not that expensive to poll at a 1ms interval in the spout waiting for back-pressure to be turned off.
|
This looks very interesting. I would really like to see some unit tests, especially around the disruptor queue to show that the callback is working. Perhaps we can also handle the corner cases for callback in DisruptorQueue itself instead of having special case code in other locations as a backup. |
|
+1 Looks very exciting. |
|
It appears that the spouts across all the workers are throttled if an executor queue fills up. For instance if there are multiple spouts, even the ones not causing the executor recv queue to fill would be throttled. Is this correct and if so desirable? Wont it be ideal to trickle the back pressure up via the immediately preceding component(s) than slowing down the entire topology ? |
|
@arunmahadevan It is the intention to throttle the entire topology, all spouts. This is what Heron does and is intended to be a last resort, which is better then nothing, but not a truly final solution. The reason for this is that from the level of a single queue it is very difficult to know what is causing that congestion. STORM-907 is intended as a follow on that will analyze the topology, determine where there are loops and provide more of true backpressure. But in the case of a loop, and storm does support loops, you have no way to determine which upstream part is causing slowness. And in fact it could be the bolt itself, and it needs to increase it's parallelism. |
| (disruptor/consumer-started! receive-queue) | ||
| (fn [] | ||
| ;; this additional check is necessary because rec-q can be 0 while the executor backpressure flag is forever set | ||
| (if (and ((:storm-conf executor-data) TOPOLOGY-BACKPRESSURE-ENABLE) (< (.population receive-queue) low-watermark) @(:backpressure executor-data)) |
There was a problem hiding this comment.
Can we move the and form's second and third conditions to new lines?
|
Addressed comments: To continue work on the rest three comments: |
| storm-cluster-state (:storm-cluster-state worker) | ||
| prev-backpressure-flag @(:backpressure worker)] | ||
| (doseq [ed executors] ;; Debug, TODO: delete | ||
| (log-message "zliu executor" (.get-executor-id ed) " flag is " (.get-backpressure-flag ed))) |
There was a problem hiding this comment.
Thanks for the reminder, I will remove all those debug messages soon after the unit test commit.
|
Hi, Bobby @revans2 , all comments and concerns have been addressed. Ready for another round of review. Thanks! |
|
Initial tests on 5 node openstack cluster (1 zk, 1 nimbus, 3 supervisors). I. Test a normal topology (no congestion happen) Without topology running, the zookeeper node's received packets is 5 pack/second; This shows that Backpressure will have minimal additional overheads to zookeeper for any non-congested topologies. |
|
II. Test with a congested topology. Interestingly, without ABP, this 12 worker (87 executors) topology can not run successfully in Storm since workers frequently crash because overflowing of tuples in the bolt executors. On the contrast, with ABP enabled, this topology runs pretty well. This test shows the great advantage of Backpressure when dealing with topologies that may have congested or slow components. Since (1) ABP makes sure this topology can run successfully; (2) ABP causes small overheads to Zookeeper. |
|
@zhuoliu looks like you missed adding in a file, We also need to upmerge. |
| @@ -602,6 +640,7 @@ | |||
| (log-message "Activating spout " component-id ":" (keys task-datas)) | |||
| (fast-list-iter [^ISpout spout spouts] (.activate spout))) | |||
|
|
|||
| ;; (log-message "Spout executor " (:executor-id executor-data) " found throttle-on, now suspends sending tuples") | |||
There was a problem hiding this comment.
Can we remove this line? it looks like it is no longer needed.
|
For the most part things look really good. I would also love to see something added to Examples. Like a Word Count that just goes as fast as it can. That way we can see before, with acking disabled it crashes, after with acking disabled it stays up and can run really well. I can help with code for that if you want. |
Temp version that can do both throttle and back-to-normal, WordCountTopology changed, may revert it later re-enable the recurring of throttle check to zk in worker Use ephemeral-node for worker backpressure Make backpressure configurable use disruptor/notify-backpressure-checker Remove debug message for daemons Address Bobby and Kyle's comments, to continue for the other three Now we can obtain the latest q size during a batch, addressed the big concern during q check Add metrics for backpressure and emptyEmit stats Put disruptor queue checking inside disruptor queue as a new callback Add unit test for disruptor queue backpressure and callback checks Remove debug messages now seq-id is not needed in tuple-action-fn
|
Thanks, Bobby @revans2 . I addressed all the comments. |
|
@zhuoliu I looked over the code, and I ran some tests with a word count program that does not sleep, and there are not enough split sentence bolts. This kept the workers from crashing, which I verified happened without it. It was able to keep a throughput similar to setting a decent value for max spout pending, but with a larger latency. I am +1 for merging this in. Great work. |
|
Does this solve the problem of tuple timeout, when a bolt is completely stalled waiting for an external component to get back up? Ideally, the tuple timeout should be used as a last resort to detect that internal storm components don't respond. And back pressure should ensure that the Spout doesn't reemit to temporarily busy/blocked bolts - regardless of timeout. |
|
@rsltrifork, No this does not solve that issue. The timeout is still a hard coded value. The backpressure just means that the spout will not be outputting new values. Old tuples can still time out and be replayed. The problem here is the halting problem. How do you know that the bolt is waiting in a controlled manner? Even if you do know that how do you know that if it is waiting in a controlled manner that it has not lost track of a tuple? You have to be able to predict the future to truly solve this problem. A hard coded timeout is a simple solution. There have been a few other proposals to adjust the timeout dynamically, but that all have potentially serious limitations compared to a static timeout. |
|
Thanks for the quick reply, revans2.
A Bolt sending to an external system can include a circuit breaker, so it can keep waiting while the CB is tripped, while regularly retrying sends to check if the recipient is up. While doing this, the Bolt could also tell Storm that processing of the current tuple is currently blocked, and that Storm should reset the tuple timeout for it (and subsequent inflight tuples):
The bolt is continuously saying that it still has the tuple. |
|
@rsltrifork That does sound like a very interesting approach. I would love to see some numbers on how it would perform. |
|
In case external system is down, it could be interesting to pause the Spout for an amount of time. The state "OPEN" of the CB could be directly linked to the spout. I don't know if the implementation of the back pressure is manageable through public API. But it would be a nice enhancement to be able to implement Circuit Breaker algorithm with bolt and spout. Error count and timeout generated by request to external system can be detected by the bolt using those external component and could be propagated to the spout. In case the amount of consecutive error reaches a defined value the spout could be paused by the bolt for an amout of time (CLOSE to OPEN state). After sleeping the spout is considered in HALF OPEN state. If new error occurs spout sleeps for another amount of time else it goes to CLOSE state and continue to read new tuples. Being able to use Circuit breaker framework like Hystrix could be a nice enhancement of the back pressure feature. https://github.com/Netflix/Hystrix |
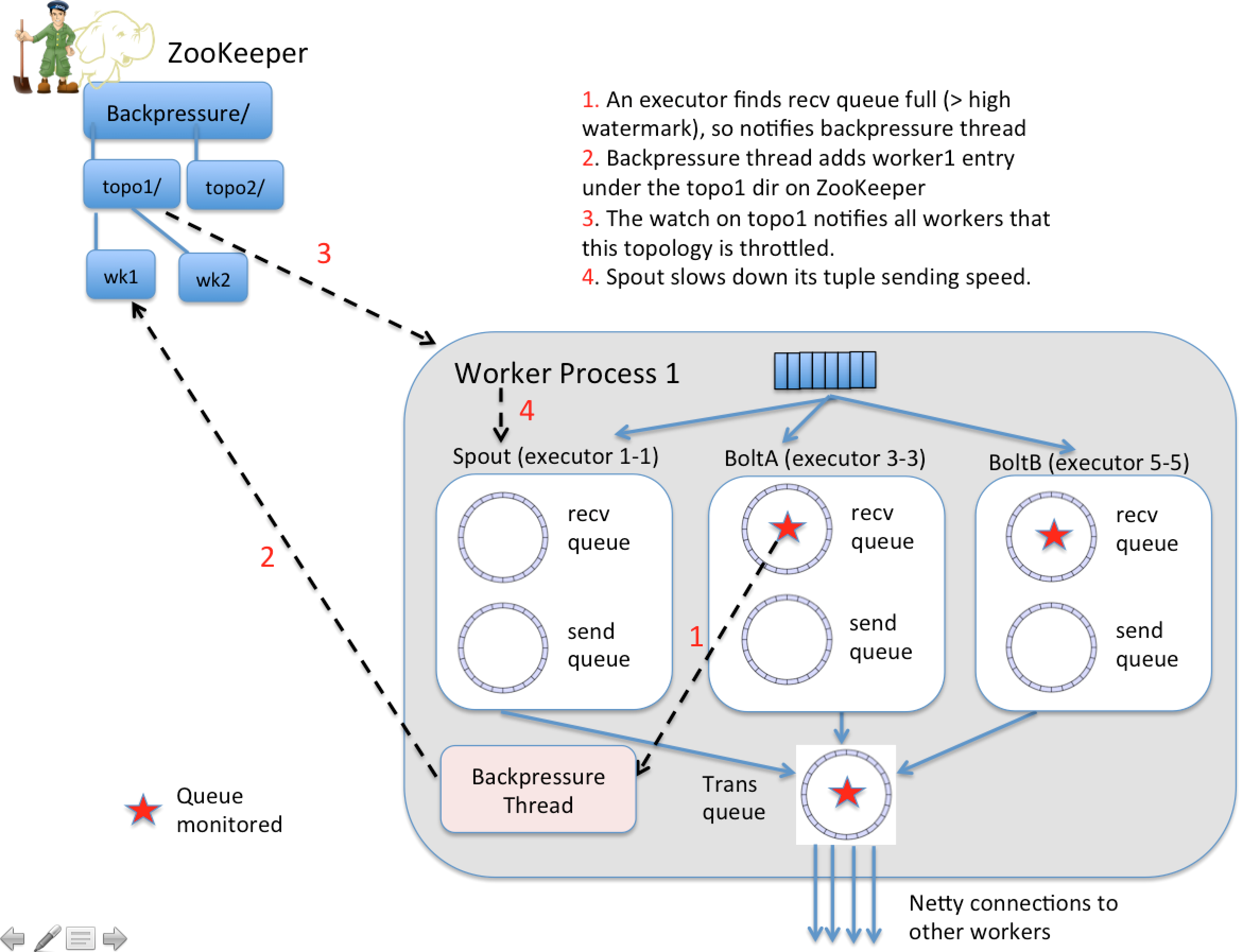
This new feature is aimed for automatic flow control through the topology DAG since different components may have unmatched tuple processing speed. Currently, the tuples may get dropped if the downstream components can not process as quickly, thereby causing a waste of network bandwidth and processing capability. In addition, it is difficult to tune the max.spout.pending parameter for best backpressure performance. Another big motivation is that using max.spout.pending for flow control forces users to enable acking, which does not make sense for the scenarios where acking is not needed and flow control is needed (e.g., the at-most-once cases). Therefore, an automatic back pressure scheme is highly desirable.
In this design, spouts throttle not only when max.spout.pending is hit, but also when any bolt has gone over a high water mark in their receive queue, and has not yet gone below a low water mark again. There is a lot of room for potential improvement here around control theory and having spouts only respond to downstream bolts backing up, but a simple bang-bang controller like this is a great start.
Our ABP scheme implements a light-weight yet efficient back pressure scheme. It monitors certain queues in executors and worker and exploits the callback schemes on ZooKeeper and disruptor queue for a fast-responding (in a push manner) flow control.
Please check the attached figures for more details about the implementation.
https://issues.apache.org/jira/secure/attachment/12761186/aSimpleExampleOfBackpressure.png