pysc2_maddpg 这个项目是我在中科院自动化所的实习代码,主要是利用深度强化学习的MADDPG算法,应用到暴雪开源的SC2LE强化学习开发环境,来训练星际争霸2中一个简单的对抗环境。
利用Open AI的MADDPG多智体联合算法,训练了星际争霸2——sc2le环境中最基本5v5对抗中的收割者。
- 当动作空间为3,初始态为攻击态时,胜率达到90%。
- 通过训练,收割者能够实现索敌靠近。
- 能够基本协同作战,以获得更高胜率。
- 考虑血量和己方的攻击力,选择作战攻略(目前还未实现)。
papers是项目的理论支撑,包括项目的参考的论文。
Document是前人文档。
maddpg是代码的核心部分,包含maddpg算法和pysc2环境两个部分。
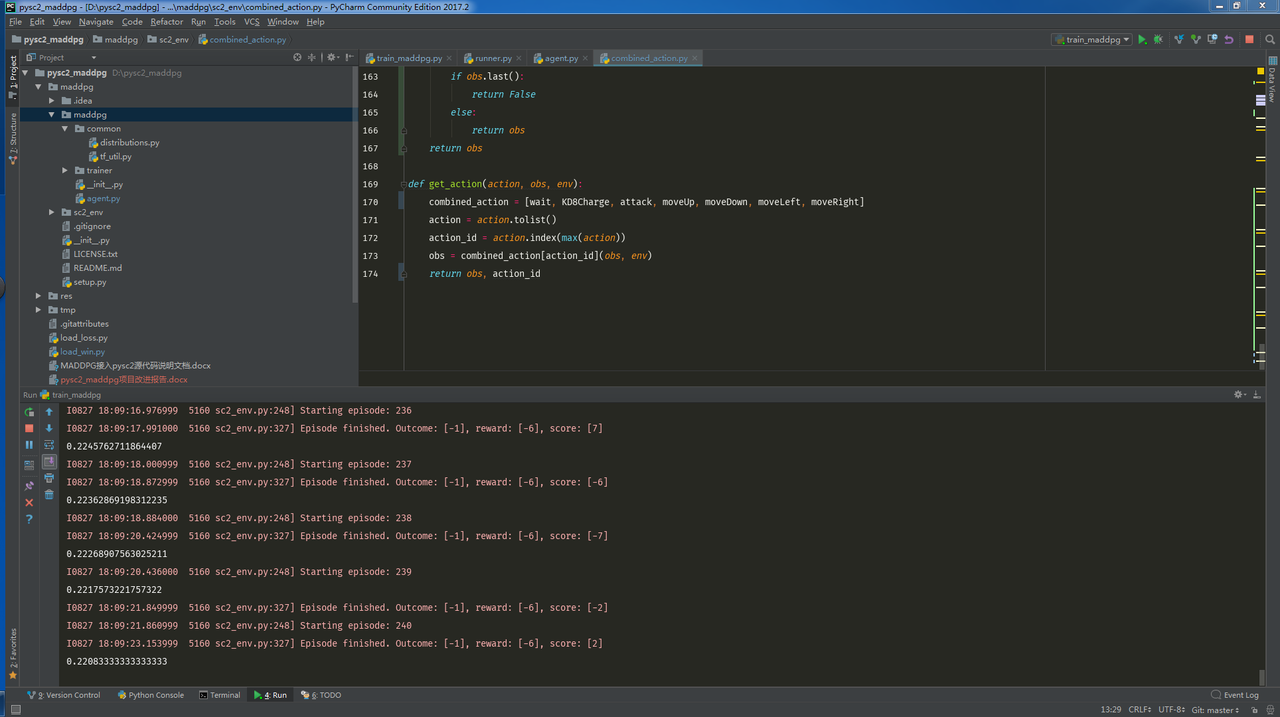
- sc2_env是项目对于pysc2环境的接口,包含combined_action.py和runner.py两个文件。其中combined_action.py是动作空间文件,规定了动作个数,在在3动作空间会有更好的表现。runner.py将我们的agent接入了pysc2环境。
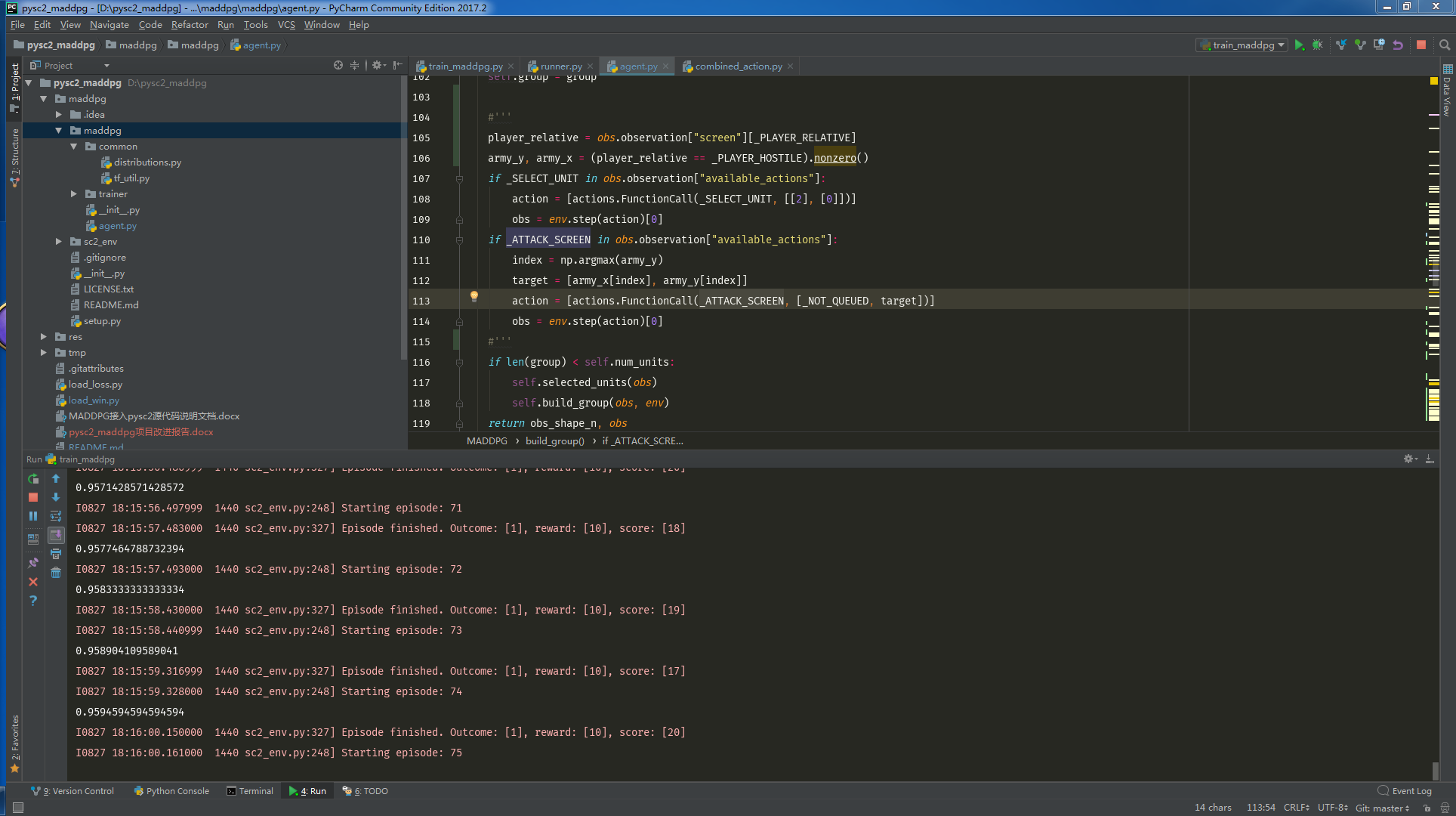
- maddpg是项目调用的maddpg算法的部分,包含trainer,common和agent.py文件。其中trainer和common是MADDPG自带的部分,用于规定算法;agent.py文件是我们自己实现的agent类,具体可以实现一些特殊的动作,如选择单元、选择控制组、获得当前状态等等。
项目的csv文件是数据记录文件,记录了实验的相关数据。
项目的load文件将会显示试验的结果。
- load_win.py显示了胜率随着局数的变化。
- load_loss.py显示了训练的loss曲线。
train_maddpg.py训练总文件,配置好环境之后运行的文件。
游戏采用最简单的5v5场景,为了让收割者们通过学习学到好的策略,设计采用condition-strategy-rewards的基本构架。
为了让收割者们有更好的表现,我们需要让收割者们上场杀敌。杀敌的时候就需要考虑血量和攻击力两个方面。condition暂时还未实现,是未来工作的一部分。
假设我方还有m个幸存的收割者,血量分别是$$Hp_1, Hp_2,..., Hp_m$$,收割者的攻击力大体上相同,所以我方此时的攻击力为$$D=µm$$,µ是常数。同理,对方还剩下n个幸存者,血量分别是$$Hp'_1, Hp_2',..., Hp_m'$$,攻击力为$$D'=µn$$。那么敌我双方团灭时间大致为$$t_1=\frac{\sum{}Hp}{D'}$$和$$t_2=\frac{\sum{}Hp'}{D}$$。当我方团灭时间大于对方时候,$$m\sum{}Hp>n\sum{}Hp'$$时,攻击。
考虑pysc2内置的reward是当前帧减去前一帧的score,为了获得更大score,我们应该让$reaper_i=\arg\min_{reaper_i}(Hp_{reaper_i})$号收割者远离,并派遣其他收割者攻击。
其余情况均远离。
Github上可能无法加载condition,condition图片版点击此处。
采取攻击策略有助于提升胜率,但是盲目攻击又将带来损失,因此我们制定了一套该场景下的策略。
- 主动参兵有奖:设置distance,当我方收割者与离之最近的敌方收割者拉近距离时候会有奖励;若已经进入战场,不再通过distance增加reward。
- 支援队友有奖:当拉近距离之后,孤军奋战是不好的策略,因此当我们所有的收割者都执行攻击动作的时候,有一个相应的奖励。
- 战场杀敌有奖:此项由于涉及到score,是pysc2内设的,因此不予考虑。
rewards在agent.py,runner.py和train_maddpg.py中都有涉及,范围较广,暂时考虑了两种rewards,分别是pysc2内置的score带来的reward 和距离拉近带来的rew_d。
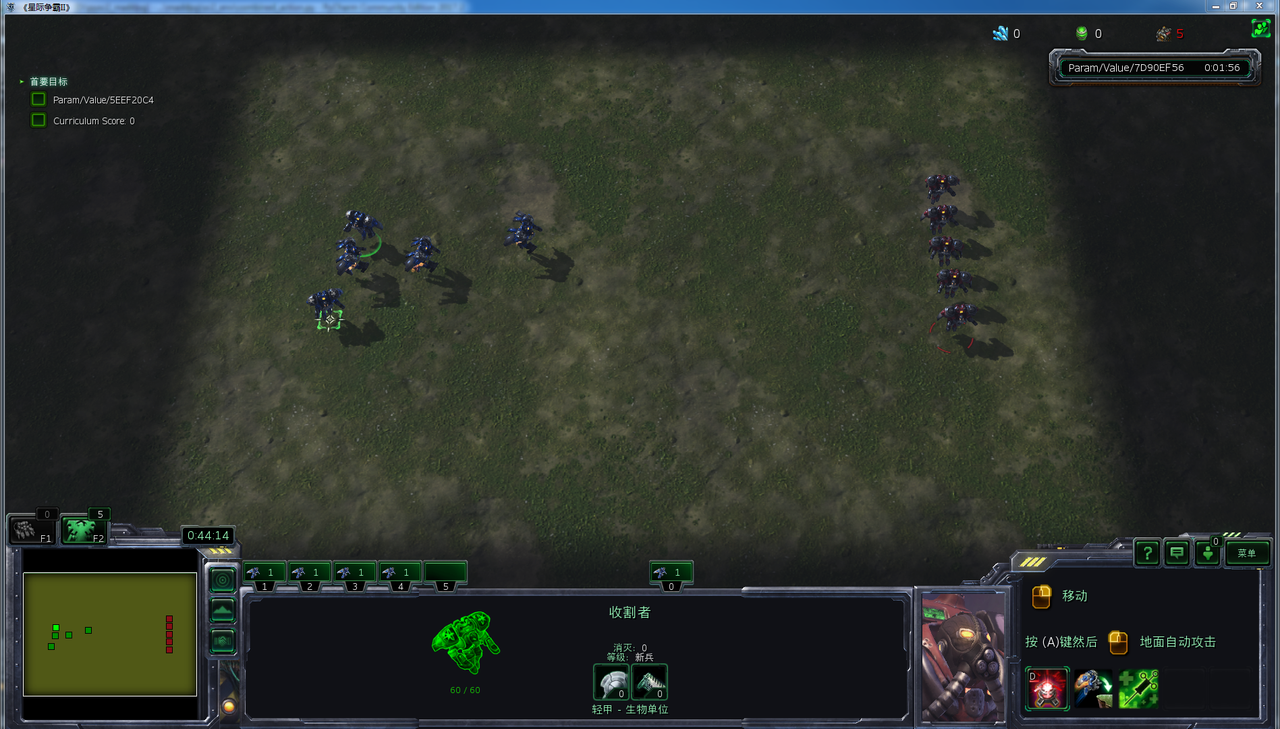
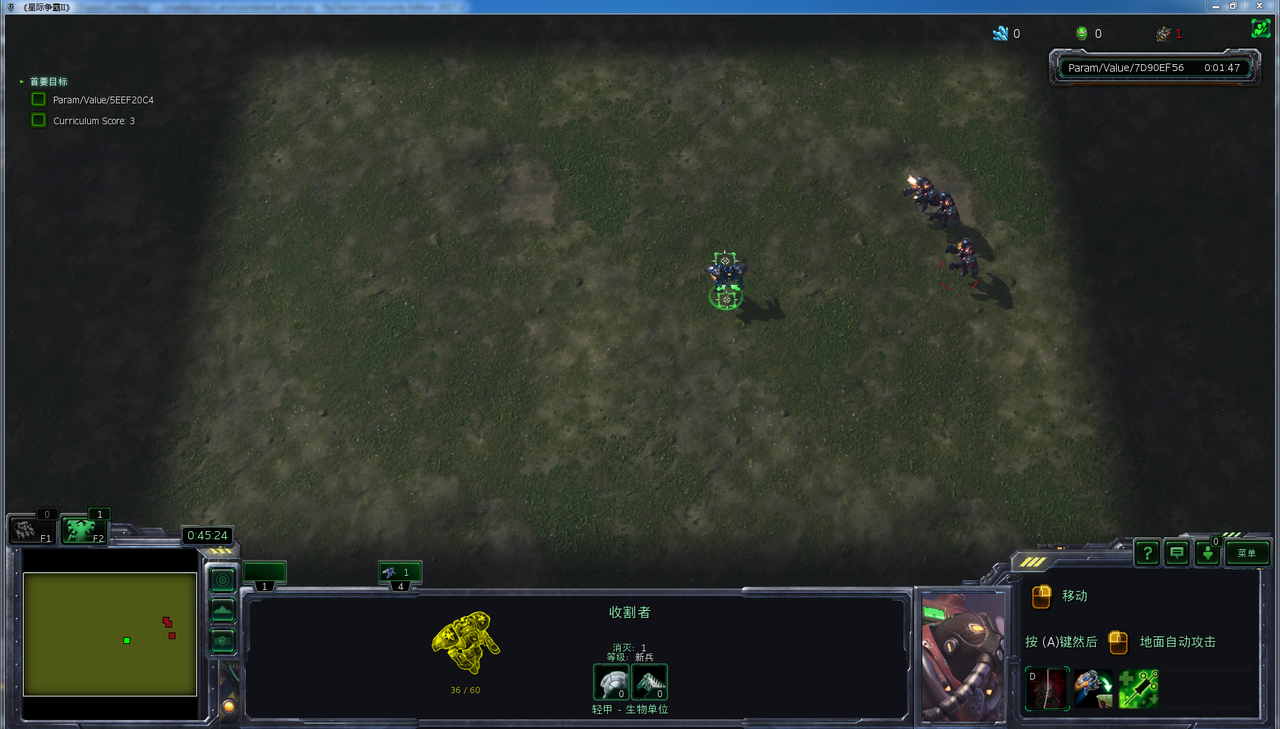
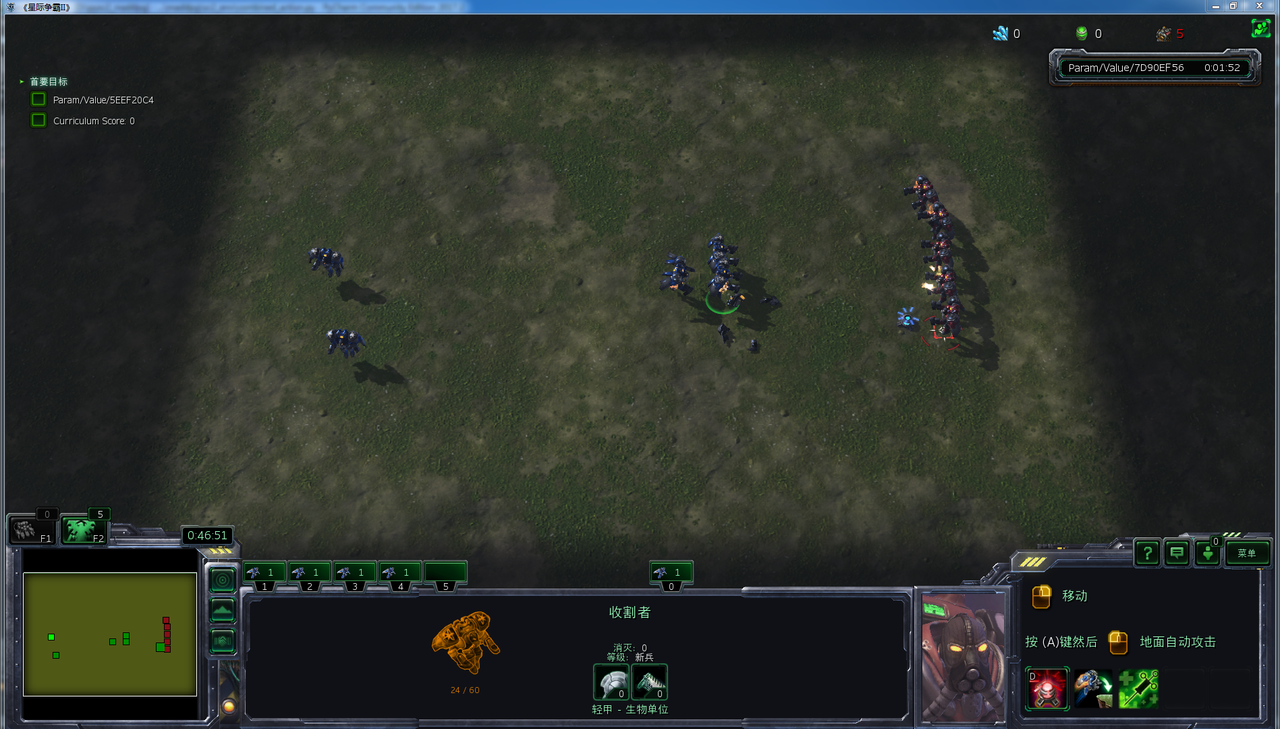
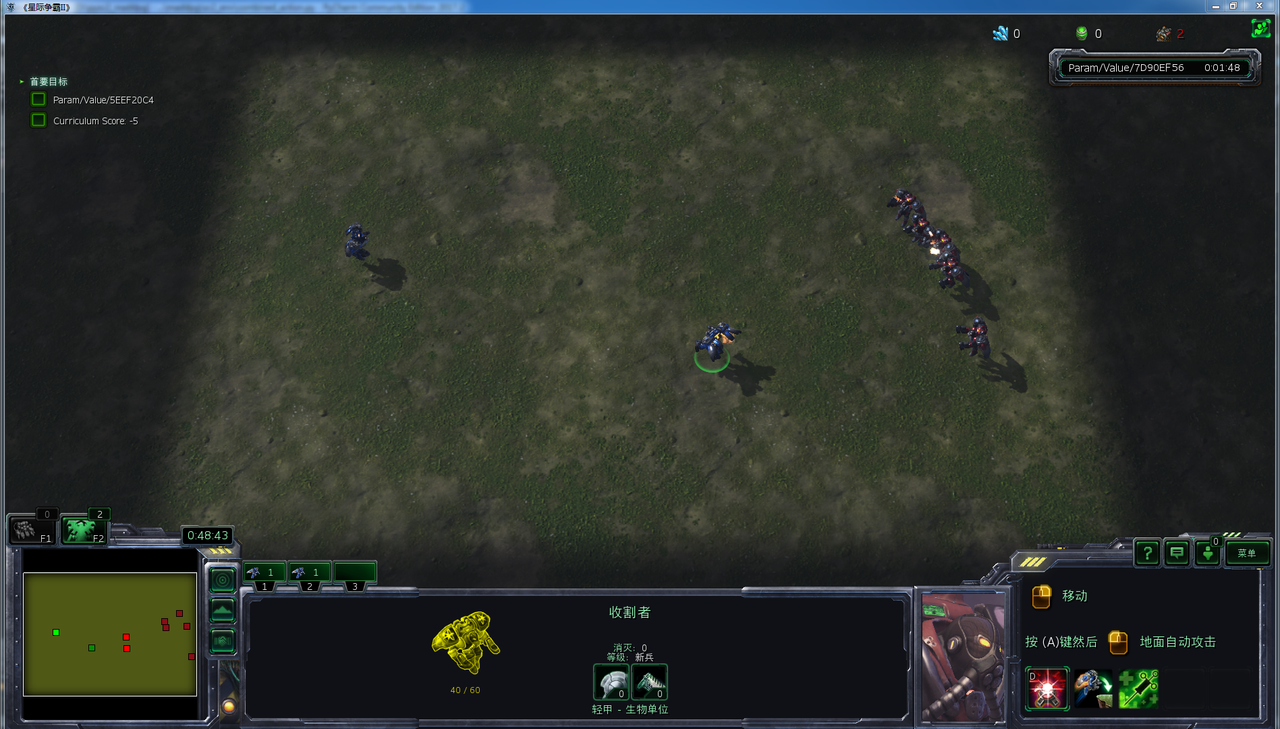
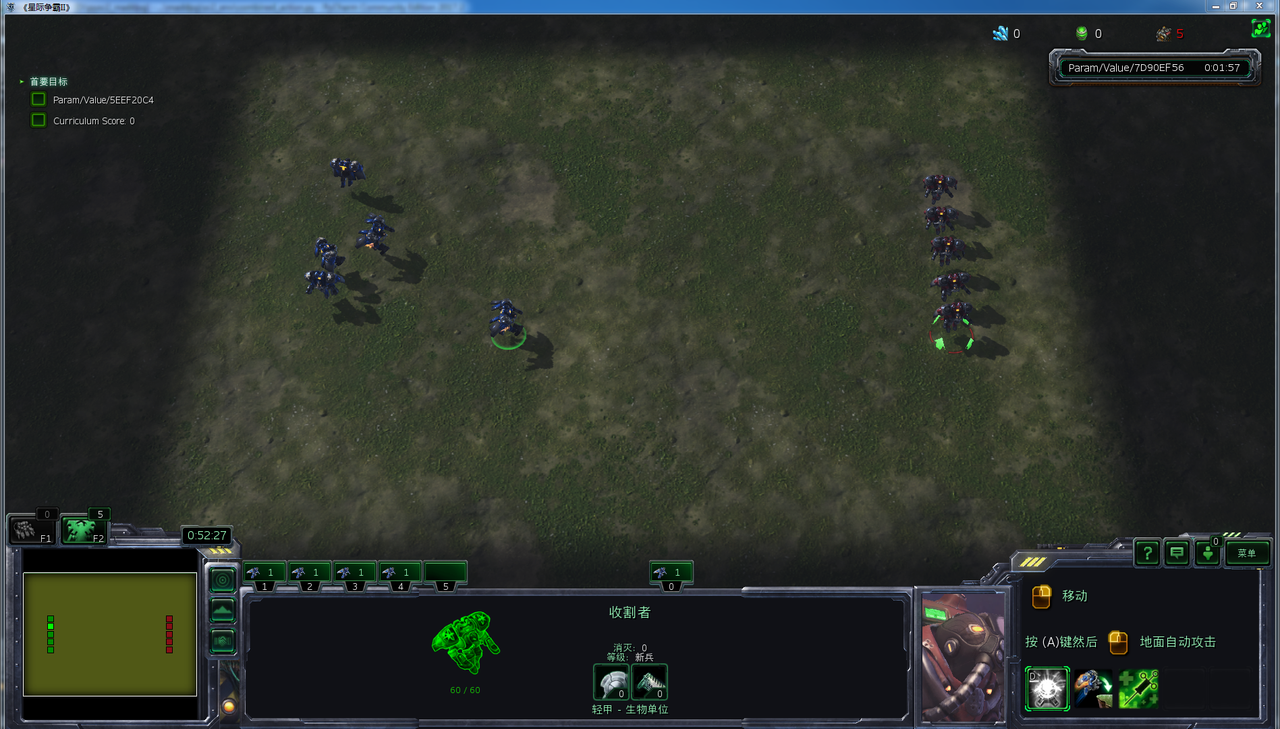
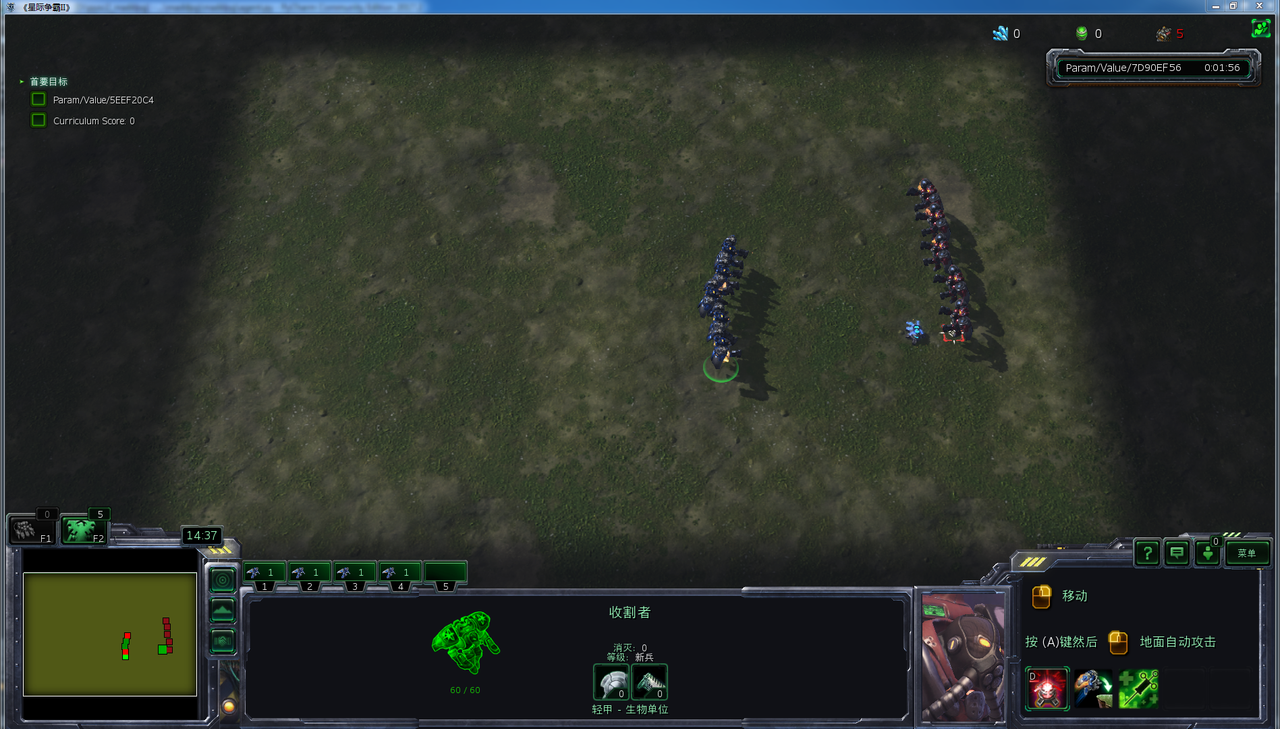
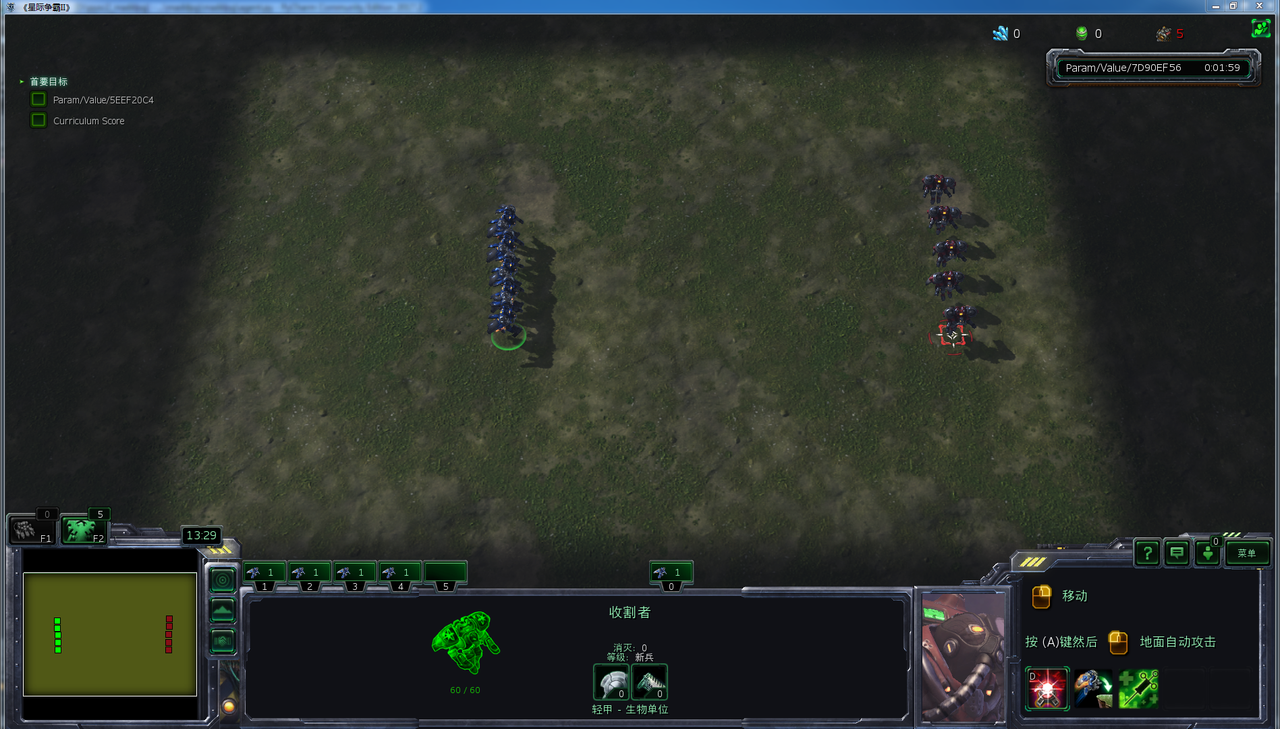
- 在初始化为攻击状态,动作空间为3个动作时,胜率可以达到90%多。
- 在初始化为任意状态,动作空间为3个动作时,胜率可以达到50%多。
- 在初始化为任意状态,动作空间为7个动作时,胜率只有20%左右。
{kind=link}
【2】迈向通用人工智能:星际争霸2人工智能研究环境SC2LE完全入门指南
【3】星际争霸2之环境配置
【1】强化学习基本介绍
【2】DNQ介绍
【3】Intel——DNQ
【4】MADDPG论文翻译
【5】MADDPG官方文档
【6】MADDPG简介
【7】DDPG详解
【8】深度学习A3C
- 感谢导师对我工作的支持。
- 感谢Sherry,在背后默默对我代码工作和学习生活一贯的支持。